Wichtig
Übersetzen ist eine Gemeinschaftsleistung Sie können mitmachen. Diese Seite ist aktuell zu 73.68% übersetzt.
17.22. Interpolation
Bemerkung
In diesem Kapitel lernen wir, wie man Punktdaten interpoliert. Wir werden auch ein weiteres reales Beispiel zur räumlichen Analyse kennenlernen
In dieser Lektion werden wir Punktdaten interpolieren, um einen Rasterlayer zu erhalten. Bevor wir beginnen, müssen wir die Daten vorbereiten. Nach dem Interpolation werden wir den resultierenden Layer noch weiter verarbeiten, so dass sich eine vollständige Analyseroutine ergeben wird.
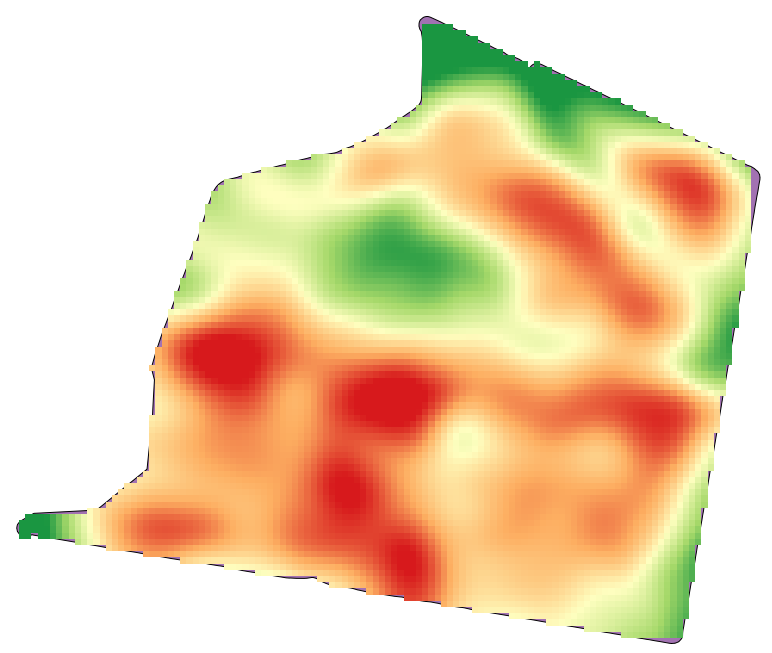
Öffnen Sie die Beispieldaten für diese Lektion, die wie folgt aussehen sollten.

Der Datensatz enthält Daten zum Ernteertrag, so wie er von modernen Erntemaschinen erstellt wird. Wir werden aus diesen Daten einen Rasterlayer des Ernteertrages erstellen. Wir wollen keine weiteren Analysen mit diesem Layer ausführen. Er soll als Hintergrundlayer dienen, der die produktivsten Bereiche und die weniger produktiven Bereiche einfach kennzeichnet.
The first thing to do is to clean–up the layer, since it contains redundant points. These are caused by the movement of the harvester, in places where it has to do a turn or it changes its speed for some reason. The Points filter algorithm will be useful for this. We will use it twice, to remove points that can be considered outliers both in the upper and lower part of the distribution.
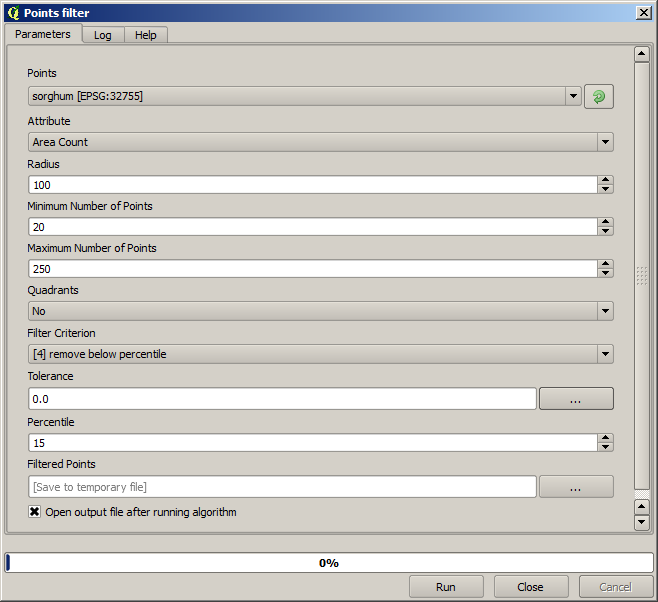
Verwenden Sie bei der ersten Ausführung die folgenden Parameter.
Übernehmen Sie bei der zweiten Ausführung die unten dargestellen Einstellungen.
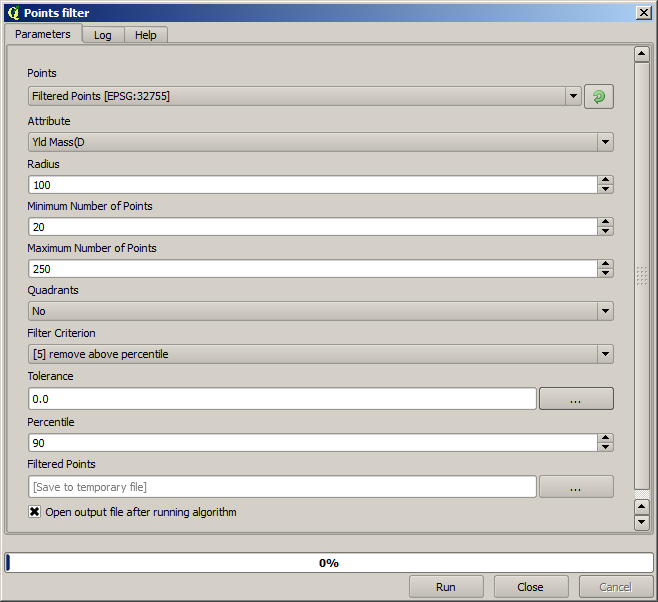
Beachten Sie, dass wir als Eingabe nicht den Ausgangslayer sondern die Ausgabe des ersten Durchlaufes verwenden.
Der Ergebnislayer sollte dem Ausgangslayer ähneln. Er enthält nur weniger Punkte. Wir können das anhand der Attributtabellen überprüfen.
Now let’s rasterize the layer using the Rasterize algorithm.
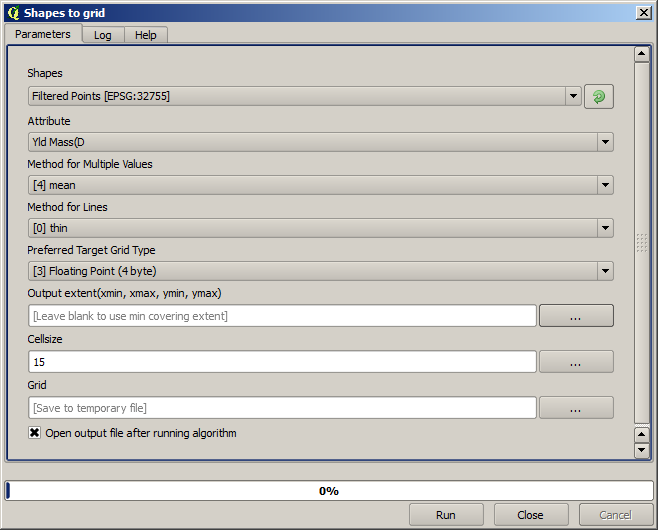
The Filtered points layer refers to the resulting one of the second filter.
It has the same name as the one produced by the first filter, since the name
is assigned by the algorithm, but you should not use the first one. Since we
will not be using it for anything else, you can safely remove it from your
project to avoid confusion, and leave just the last filtered layer.
Der sich ergebene Rasterlayer sieht wie folgt aus.

It is already a raster layer, but it is missing data in some of its cells. It only contain valid values in those cells that contained a point from the vector layer that we have just rasterized, and a no–data value in all the other ones. To fill the missing values, we can use the Close gaps algorithm.
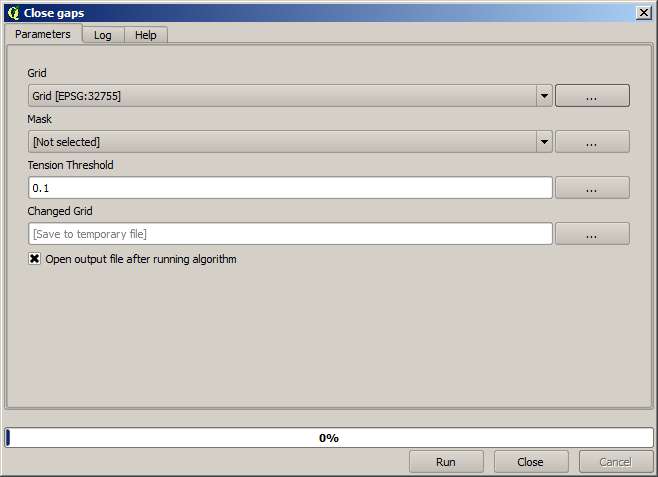
Der Layer ohne Leerwerte sieht wie folgt aus.

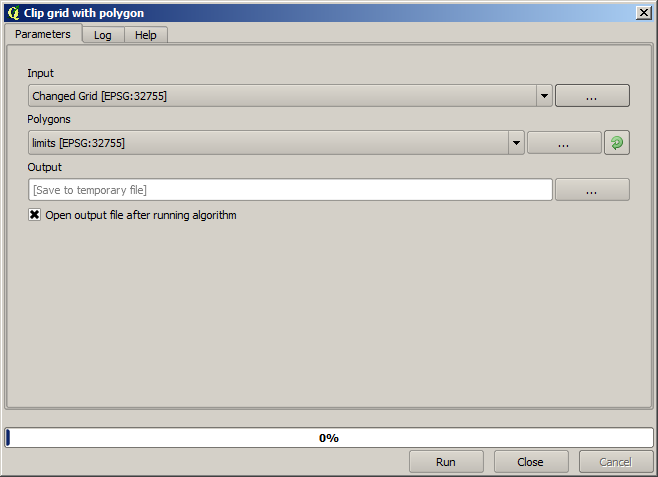
Um die Fläche des Layers genau auf die Region der Messung der Erntemenge zu beschränken, können wir den Layer mit Hilfe des Layer limits zuschneiden.
And for a smoother result (less accurate but better for rendering in the background as a support layer), we can apply a Gaussian filter to the layer.
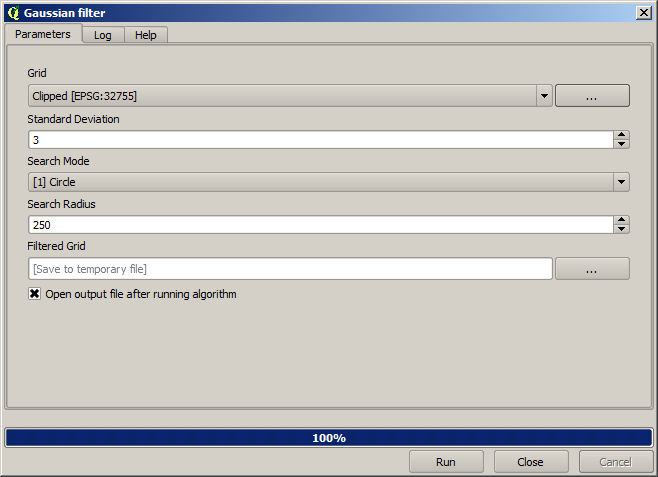
Bei Verwendung der oben aufgeführten Parameter erhalten wir das folgende Ergebnis