Les données raster dans les SIG sont des matrices de cellules discrètes qui représentent des objets, au-dessus ou en dessous de la surface de la Terre. Les cellules de la grille raster sont de la même taille et généralement rectangulaires (dans QGIS, elles seront toujours rectangulaires). Les jeux de données raster les plus classiques sont des données de télédétection telles que des photographies aériennes ou des images satellitaires et des données issues de modèles telles que les matrices d’élévation.
Unlike vector data, raster data typically do not have an associated database
record for each cell. They are geocoded by pixel resolution and the x/y
coordinate of a corner pixel of the raster layer. This allows QGIS to position
the data correctly in the map canvas.
Pour afficher correctement les données, QGIS utilise les informations de géoréférencement intégrées aux couches raster (par exemple GeoTiff) ou présentes dans un fichier world.
Many of the features available in QGIS work the same, regardless the vector
data source. However, because of the differences in formats specifications
(ESRI shapefiles, MapInfo and MicroStation file formats, AutoCAD DXF, PostGIS,
SpatiaLite, DB2, Oracle Spatial and MSSQL Spatial databases, and many more),
QGIS may handle differently some of their properties.
This section describes how to work with these specificities.
Note
QGIS gère les entités de type (multi)point, (multi)ligne, (multi)polygone, CircularString, CompoundCurve, CurvePolygon, MultiCurve, MultiSurface avec des valeurs Z et/ou M.
Merci de prendre note que certains pilotes ne gèrent pas certains de ces types d’entités comme les types CircularString, CompoundCurve, CurvePolygon, MultiCurve et MultiSurface. QGIS les convertira alors en entités de type (multi)polygone.
The ESRI shapefile is still one of the most used vector file format in QGIS.
However, this file format has some limitation that some other file format have
not (like Geopackage, spatialite). Support is provided by the
OGR Simple Feature Library.
A shapefile actually consists of several files. The following three are
required:
.shp fichier contenant la géométrie des entités;
.dbf fichier contenant les attributs au format dBase;
.shx fichier d’index.
Shapefiles also can include a file with a .prj suffix, which contains
the projection information. While it is very useful to have a projection file,
it is not mandatory. A shapefile dataset can contain additional files. For
further details, see the ESRI technical specification at
http://www.esri.com/library/whitepapers/pdfs/shapefile.pdf.
Improving Performance for Shapefiles
To improve the performance of drawing a shapefile, you can create a spatial
index. A spatial index will improve the speed of both zooming and panning.
Spatial indexes used by QGIS have a .qix extension.
Voici les étapes de création d’un index spatial :
- Load a shapefile (see The Browser Panel);
- Open the Layer Properties dialog by double-clicking on the
shapefile name in the legend or by right-clicking and choosing
from the context menu.
- In the General tab, click the [Create Spatial Index] button.
Problem loading a shape .prj file
If you load a shapefile with a .prj file and QGIS is not able to read the
coordinate reference system from that file, you will need to define the proper
projection manually within the General tab of the
Layer Properties dialog of the layer by clicking the
[Specify...] button. This is due to the fact that .prj files
often do not provide the complete projection parameters as used in QGIS and
listed in the CRS dialog.
For the same reason, if you create a new shapefile with QGIS, two different
projection files are created: a .prj file with limited projection
parameters, compatible with ESRI software, and a .qpj file, providing
the complete parameters of the used CRS. Whenever QGIS finds a .qpj
file, it will be used instead of the .prj.
Tabular data is a very common and widely used format because of its simplicity
and readability – data can be viewed and edited even in a plain text editor.
A delimited text file is an attribute table with each column separated by a
defined character and each row separated by a line break. The first row usually
contains the column names. A common type of delimited text file is a CSV
(Comma Separated Values), with each column separated by a comma.
Such data files can also contain positional information in two main forms:
- As point coordinates in separate columns
- As well-known text (WKT) representation of geometry
QGIS allows you to load a delimited text file as a layer or ordinal table. But
first check that the file meets the following requirements:
- The file must have a delimited header row of field names. This must be the
first line in the text file.
- The header row must contain field(s) with geometry definition. These field(s)
can have any name.
- The X and Y coordinates (if geometry is defined by coordinates) must be
specified as numbers. The coordinate system is not important.
Si vous avez des champs qui ne sont pas de type texte et que le fichier est un CSV, vous devriez avoir un fichier CSVT (voir section CSVT Files).
Comme exemple de fichier texte valide, nous pouvons importer le fichier point d’élévation elevp.csv fourni avec le jeu de données échantillon de QGIS (voir section Sample Data) :
X;Y;ELEV
-300120;7689960;13
-654360;7562040;52
1640;7512840;3
[...]
Notons les points suivants à propos du fichier texte :
Le fichier texte d’exemple utilise le ; (point-virgule) comme délimiteur. N’importe quel caractère peut être utilisé comme délimiteur de champ.
La première ligne est la ligne d’en-tête. Elle contient les champs X, Y et ELEV.
Aucun guillemet (") n’est utilisé pour délimiter les champs de type texte.
Les coordonnées X sont stockées dans le champ X.
Les coordonnées Y sont stockées dans le champ Y.
Lors du chargement de fichiers CSV, le pilote OGR suppose que tous les champs sont des chaînes de caractères (c’est-à-dire du texte), sauf indication contraire. Vous pouvez créer un fichier CSVT pour indiquer à OGR (et à QGIS) le type de données correspondant aux différentes colonnes:
| Type |
Nom
|
Exemple
|
|---|
Nombre entier
|
Entier
|
4 |
Nombre décimal
|
Réel
|
3.456 |
| Date |
Date (YYYY-MM-DD) |
2016-07-28 |
Temps
|
Temps (HH:MM:SS+nn)
|
18:33:12+00 |
Date & Heure
|
DateTime (YYYY-MM-DD HH:MM:SS+nn) |
2016-07-28 18:33:12+00 |
Le fichier CSVT est un fichier texte brut d’UNE ligne avec les types de données entre guillemets et séparés par des virgules, par exemple:
"Integer","Real","String"
Vous pouvez même spécifier la largeur et la précision de chaque colonne, par exemple:
"Integer(6)","Real(5.5)","String(22)"
Ce fichier est sauvegardé dans le même dossier que le fichier .csv, avec le même nom, mais en tant qu’extension .csvt
You can find more information at GDAL CSV Driver.
Les couches PostGIS sont stockées dans une base de données PostgreSQL. Les avantages de PostGIS sont les possibilités d’indexation spatiale, de filtre et de requête qu’il fournit. En utilisant PostGIS, les fonctions vecteur telles que la sélection ou l’identification fonctionnent avec plus de précision qu’avec les couches OGR dans QGIS.
Astuce
Couches PostGIS
Normalement, une couche PostGIS est définie par une entrée dans la table geometry_columns. QGIS peut cependant charger des couches qui n’ont pas d’entrée dans la table geometry_columns. Ceci concerne aussi bien les tables que les vues. Définir une vue spatiale fournit un moyen puissant pour visualiser vos données. Référez-vous à votre manuel PostgreSQL pour plus d’informations sur la création des vues.
Cette section fournit quelques détails sur la manière dont QGIS accède aux couches PostgreSQL. La plupart du temps, QGIS devrait simplement fournir une liste des tables de la base de données qui peuvent être chargées et il les chargera à la demande. Cependant, si vous avez des problèmes pour charger une table PostgreSQL dans QGIS, les informations données ci-dessous peuvent vous aider à comprendre les messages de QGIS et vous donner une indication sur comment changer la table ou la vue PostgreSQL pour qu’elle se charge dans QGIS.
QGIS demande que les couches PostgreSQL aient un champ pouvant être utilisé comme clé unique pour la couche. Pour les tables, cela signifie qu’elles doivent avoir une clé primaire ou un champ ayant une contrainte d’unicité. De plus, QGIS impose que cette colonne soit de type int4 (un entier de 4 octets). Alternativement, la colonne ctid peut être utilisée comme clé primaire. Si une table ne respecte pas ces conditions, le champ oid sera utilisé à la place. Les performances seront améliorées si le champ est indexé (notez que les clés primaires sont automatiquement indexées dans PostgreSQL).
QGIS propose une case à cocher Sélectionner par identifiant qui est activée par défaut. Cette option permet de récupérer les identifiants sans les attributs, ce qui est plus rapide dans la plupart des cas.
Si la couche PostgreSQL est une vue, les mêmes conditions s’appliquent, mais elles n’ont pas toujours de clé primaire ou de champ ayant une contrainte d’unicité. Dans ce cas, vous devez définir une clé primaire (de type entier) avant de charger la vue. Si aucun champ ne convient, QGIS ne chargera pas la vue. Si cela arrive, la solution est de modifier la vue de sorte qu’elle inclue un champ qui convient (de type entier et qui soit une clé primaire ou ayant une contrainte d’unicité, de préférence indexé).
Comme pour les tables, une case à cocher Sélectionner par identifiant est activée par défaut (voir ci-dessus pour la signification de la case à cocher). Ça peut avoir du sens de désactiver cette option lorsque vous utilisez des vues coûteuses.
If you want to make a backup of your PostGIS database using the pg_dump and
pg_restore commands, and the default layer styles as saved by QGIS fail to
restore afterwards, you need to set the XML option to DOCUMENT and the
restore will work.
QGIS permet de filtrer les entités directement côté serveur. Cochez l’option  pour l’activer. Seules les expressions supportées seront envoyées à la base de données. Les expressions qui utilisent des opérateurs ou des fonctions non prises en compte seront évaluées en local.
pour l’activer. Seules les expressions supportées seront envoyées à la base de données. Les expressions qui utilisent des opérateurs ou des fonctions non prises en compte seront évaluées en local.
Most of common data types are supported by the PostgreSQL provider: integer, float,
varchar, geometry and timestamp.
Array data types are not supported.
Différents outils, notamment le Gestionnaire de bases de données (BD Manager plugin) ou les outils en ligne de commande comme sh2pgsql ou ogr2ogr, permettent d’importer les données dans une base de données PostgreSQL/PostGIS.
QGIS comes with a core plugin named  DB Manager. It can
be used to load shapefiles and other data formats, and it includes support for
schemas. See section Extension DB Manager for more information.
DB Manager. It can
be used to load shapefiles and other data formats, and it includes support for
schemas. See section Extension DB Manager for more information.
PostGIS includes an utility called shp2pgsql that can be used to import
shapefiles into a PostGIS-enabled database. For example, to import a
shapefile named lakes.shp into a PostgreSQL database named
gis_data, use the following command:
shp2pgsql -s 2964 lakes.shp lakes_new | psql gis_data
Ceci crée une nouvelle couche nommée lakes_new dans la base de données gis_data. La nouvelle couche aura l’identifiant de référence spatiale (SRID) 2964. Référez-vous à la section Utiliser les projections pour plus d’informations sur les systèmes de référence spatiale et les projections.
Astuce
Exporter des jeux de données depuis PostGIS
Like the import tool shp2pgsql, there is also a tool to export
PostGIS datasets as shapefiles: pgsql2shp. This is shipped within
your PostGIS distribution.
En plus de shp2pgsql et DB Manager, un autre outil est fourni pour importer des données géographiques dans PostGIS : ogr2ogr. Il est inclus dans GDAL.
To import a shapefile into PostGIS, do the following:
ogr2ogr -f "PostgreSQL" PG:"dbname=postgis host=myhost.de user=postgres
password=topsecret" alaska.shp
This will import the shapefile alaska.shp into the PostGIS database
postgis using the user postgres with the password topsecret on host
server myhost.de.
Notez qu’OGR doit être compilé avec PostgreSQL pour gérer PostGIS. Vous pouvez le vérifier en tapant (sous  )
)
ogrinfo --formats | grep -i post
Si vous préférez utiliser la commande COPY de PostgreSQL au lieu de la méthode INSERT INTO par défaut, vous pouvez exporter la variable d’environnement suivante (au moins sur et  ) :
) :
ogr2ogr ne crée pas d’index spatial comme le fait shp2pgsl. Vous devez donc effectuer une étape supplémentaire en le créant manuellement avec la commande SQL classique CREATE INDEX (comme détaillé dans la section suivante Améliorer les performances).
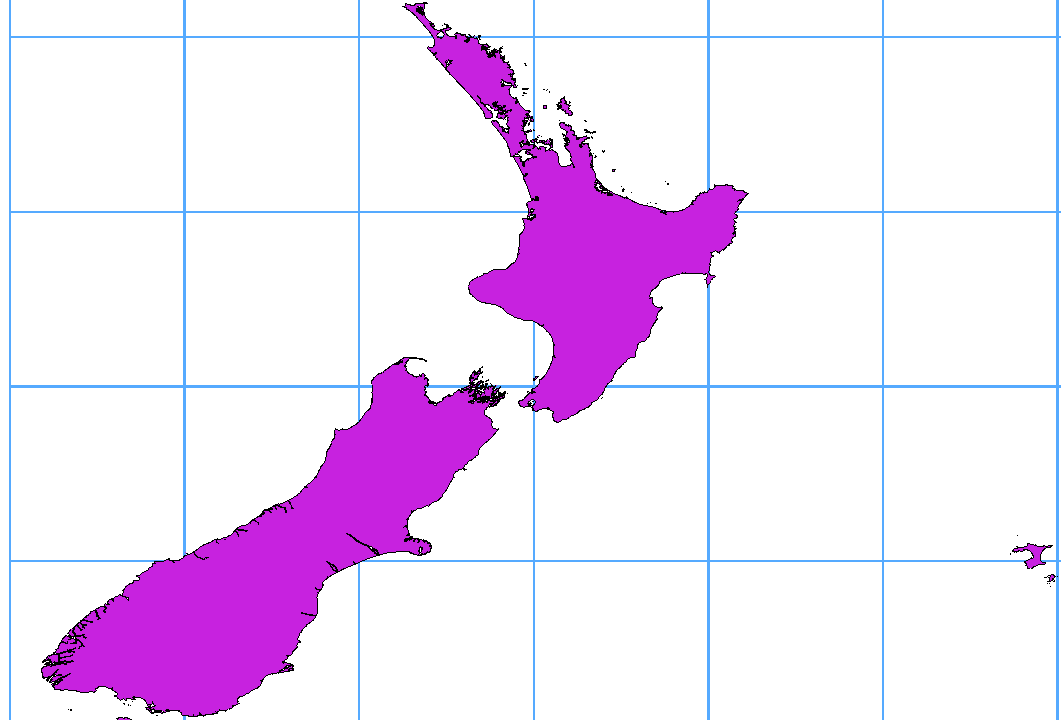
Many GIS packages don’t wrap vector maps with a geographic reference system
(lat/lon) crossing the 180 degrees longitude line
(http://postgis.refractions.net/documentation/manual-2.0/ST_Shift_Longitude.html).
As result, if we open such a map in QGIS, we will see two far, distinct locations,
that should appear near each other. In Figure_vector_crossing, the tiny point on the far
left of the map canvas (Chatham Islands) should be within the grid, to the right of the
New Zealand main islands.
Une solution est de transformer les valeurs longitudinales en utilisant PostGIS et la fonction ST_Shift_Longitude. Cette fonction lit chaque point/sommet de chacune des entités dans une géométrie et si la coordonnée de longitude est inférieure à 0°, elle lui ajoute 360°. Le résultat est une version 0° - 360° des données sur une carte centrée à 180°.
Importer des données dans PostGIS (Importer des données dans PostgreSQL) en utilisant, par exemple, l’extension DB Manager.
Utiliser l’interface en ligne de commande PostGIS pour exécuter la commande suivante (dans cet exemple, “TABLE” est bien le nom de votre table PostGIS): gis_data=# update TABLE set the_geom=ST_Shift_Longitude(the_geom);
Si tout s’est bien passé, vous devriez recevoir une confirmation sur le nombre d’entités qui ont été mises à jour. Ensuite, vous pouvez charger la carte et voir la différence (Figure_vector_crossing_map).
If you want to save a vector layer to SpatiaLite format, you can do this by
right clicking the layer in the legend. Then, click on ,
define the name of the output file, and select ‘SpatiaLite’ as format and the CRS.
Also, you can select ‘SQLite’ as format and then add SPATIALITE=YES in the
OGR data source creation option field. This tells OGR to create a SpatiaLite
database. See also http://www.gdal.org/ogr/drv_sqlite.html.
QGIS gère les vues SpatiaLite éditables.
Si vous souhaitez créer une nouvelle couche SpatiaLite, référez-vous à la section Créer une nouvelle couche SpatiaLite.
Astuce
Extensions de gestion de données SpatiaLite
Pour gérer des données SpatiaLite, vous pouvez également utiliser diverses extensions Python : QSpatiaLite, SpatiaLite Manager ou Gestionnaire de base de données (extension principale, recommandée). Elles peuvent toutes être téléchargées et installées via le Gestionnaire d’extensions.
IBM DB2 for Linux, Unix and Windows (DB2 LUW), IBM DB2 for z/OS (mainframe)
and IBM DashDB products allow
users to store and analyse spatial data in relational table columns.
The DB2 provider for QGIS supports the full range of visualization, analysis
and manipulation of spatial data in these databases.
User documentation on these capabilities can be found at the
DB2 z/OS KnowledgeCenter, DB2 LUW KnowledgeCenter
and DB2 DashDB KnowledgeCenter.
For more information about working with the DB2 spatial capabilities, check out
the DB2 Spatial Tutorial on IBM DeveloperWorks.
The DB2 provider currently only supports the Windows environment through the
Windows ODBC driver.
The client running QGIS needs to have one of the following installed:
- DB2 LUW
- IBM Data Server Driver Package
- IBM Data Server Client
If you are accessing a DB2 LUW database on the same machine or using DB2 LUW as
a client, the DB2 executables and supporting files need to be included in the
Windows path. This can be done by creating a batch file like the following with
the name db2.bat and including it in the directory %OSGEO4W_ROOT%/etc/ini.
@echo off
REM Point the following to where DB2 is installed
SET db2path=C:\Program Files (x86)\sqllib
REM This should usually be ok - modify if necessary
SET gskpath=C:\Program Files (x86)\ibm\gsk8
SET Path=%db2path%\BIN;%db2path%\FUNCTION;%gskpath%\lib64;%gskpath%\lib;%path%