Importante
La traducción es un esfuerzo comunitario puede unirse. Esta página está actualmente traducida en |progreso de traducción|.
15.1. Lección: Introducción a las bases de datos
Antes de utilizar PostgreSQL, vamos a asegurarnos de nuestro terreno cubriendo la teoría de base de datos general. No es necesario ingresar algún código de ejemplo; sólo existe para fines de ilustración.
La meta para esta lección: Para entender los conceptos fundamentales de los conceptos de base de datos.
15.1.1. ¿Qué es una base de datos?
Una base de datos consiste de una colección organizada de datos para uno o más usuarios, típicamente en forma digital. - Wikipedia
Un Sistema de Administración de base de datos (DBMS) consiste de software que opera base de datos, para el almacenamiento, acceso, seguridad, respaldo y otras facilidades. - Wikipedia
15.1.2. Tablas
En base de datos relacionales y base de datos de archivo plano, una tabla es un conjunto de elementos de dato (valores) que se organizan mediante un modelo de columnas verticales (que están identificadas por su nombre) y filas horizontales. Una tabla tiene un numero especifico de columnas pero puede tener cualquier numero de filas. Cada fila se identifica por los valores que aparecen en un subconjunto de columna en particular que ha sido identificado como una llave candidata. - Wikipedia
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
En base de datos SQL una tabla también es comocida como una relación
15.1.3. Columnas / Campos
Una columna es un conjunto de valores de datos de un tipo simple particular, uno para cada fila de la tabla. Las columnas proporcionan la estructura de acuerdo a que filas por las que esta compuesta. El campo término se utiliza a menudo como sinónimo de la columna, aunque muchos consideran que es más correcto utilizar el campo (o valor de campo) para referirse específicamente al único elemento que existe en la intersección entre una fila y una columna. - Wikipedia
Una columna:
| name |
+-------+
| Tim |
| Horst |
Un campo:
| Horst |
15.1.4. Registros
Un registro es la información almacenada en una fila de tabla. Cada registro tiene un campo para cada una de las columnas en la tabla.
2 | Horst | 88 <-- one record
15.1.5. Tipo de datos
Tipo de datos restringe el tipo de información que puede ser almacenada en una columna. - Tim y Horst
Hay muchas clases de tipos de datos. Enfoquemonos en los más comunes:
Cadena- para almacenar datos de texto de formato libreEntero- para almacenar números enterosReal- para almacenar números decimalesFecha- para guardar el cumpleaños de Horst para que nadie se olvideBooleano- para almacenar valores simples verdaderos/falsos
Puede decirle a la base de datos que le permita no almacenar nada en un campo. Si no hay nada en un campo, entonces el contenido del campo se denomina como valor “null”:
insert into person (age) values (40);
select * from person;
Resultado:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
Hay muchos más tipos de datos que puede usar - `!consulte el manual de PostgreSQL!<https://www.postgresql.org/docs/current/datatype.html>`_
15.1.6. Modelización de una dirección de base de datos
Vamos a utilizar un caso de estudio sencillo cómo se construye una base de datos. Queremos crear una dirección base de datos.
★☆☆ Ponte a prueba:
Anotar las propiedades que forma una dirección sencilla y que desea almacenar en nuestra base de datos.
Respuesta
Para nuestra tabla de direcciones teórica, podríamos querer almacenar las siguientes propiedades:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
Al crear la tabla para representar un objeto de dirección, crearíamos columnas para representar cada una de estas propiedades y las nombraríamos con nombres compatibles con SQL y posiblemente abreviados:
house_number
street_name
suburb
city
postcode
country
Estructura de Dirección
Las propiedades que describen una dirección son las columnas. El tipo de información almacenada en cada columna es su tipo de dato. En la siguiente sección analizaremos nuestra tabla de dirección conceptual para ver ¡cómo podemos hacerlo mejor!
15.1.7. Teoría de base de datos
El proceso para crear una base de datos implica la creación de un modelo del mundo real; tomando conceptos del mundo real y representándolos en la base de datos como entidades.
15.1.8. Normalización
Una de las ideas principales de una base de datos es para evitar duplicidad / redundancia. El proceso de eliminar redundancia de una base de datos se llama normalización.
Normalización es una forma sistemática de asegurar que una estructura de base de datos es adecuada para consultas de propósito general y libre de ciertas características indeseables-inserción, actualización y eliminación de anomalías- que podrían conducir a una pérdida de la integridad de los datos.
Hay diferentes tipos de normalización “formas”.
Echemos un vistazo a un ejemplo sencillo:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Imagine que tiene muchos amigos con el mismo nombre de calle o ciudad. Cada vez que se duplican estos datos, se consume espacio. Peor aún, si el nombre de una ciudad cambia, tiene que hacer mucho trabajo para actualizar su base de datos.
15.1.9. ★☆☆ Ponte a prueba:
Redesign the theoretical people table above to reduce duplication and to
normalise the data structure.
Puede leer más sobre la normalización de la base de datos aquí
Respuesta
The major problem with the people table is that there is a single address
field which contains a person’s entire address. Thinking about our theoretical
address table earlier in this lesson, we know that an address is made up of
many different properties. By storing all these properties in one field, we make
it much harder to update and query our data. We therefore need to split the
address field into the various properties. This would give us a table which has
the following structure:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
En la siguiente sección, aprenderá sobre las relaciones de clave externa que podrían usarse en este ejemplo para mejorar aún más la estructura de nuestra base de datos.
15.1.10. Índices
Un índice de base de datos es una estructura que mejora la velocidad de operaciones de recuperación de datos en una tabla de base de datos. - Wikipedia
Imagínese que está leyendo un libro de texto y buscando la explicación de un concepto, ¡y el libro de texto no tiene índice! Tendrá que comenzar a leer en una sola portada y recorrer todo el libro hasta que encuentre la información que necesita. El índice al final de un libro le ayuda a pasar rápidamente a la página con la información relevante:
create index person_name_idx on people (name);
Ahora las búsquedas por nombre serán más rápidas:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. Secuencias
Una secuencia es un generador de números único. Se utiliza normalmente para crear un identificador único para una columna en una tabla.
En este ejemplo, id es una secuencia: el número se incrementa cada vez que se agrega un registro a la tabla:
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. Diagrama de entidad relación
In a normalised database, you typically have many relations (tables). The
entity-relationship diagram (ER Diagram) is used to design the logical
dependencies between the relations. Consider our non-normalised people table
from earlier in the lesson:
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Con un pequeño trabajo podemos dividirlo en dos tablas, eliminando la necesidad de repetir el nombre de la calle para individuos que viven en la misma calle:
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
y:
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
We can then link the two tables using the “keys” streets.id and
people.streets_id.
Si dibujamos el diagrama ER para estas dos tablas se vería algo así:

El diagrama ER nos ayuda a expresar relaciones “uno a muchos”. En este caso, el símbolo de flecha muestra que una calle puede tener mucha gente viviendo en ella.
★★☆ Ponte a prueba:
Nuestro modelo personas tiene aún problemas de normalización - intente ver si se puede normalizar aún más y mostrar sus ideas por medio de un diagrama de ER.
Respuesta
Our people table currently looks like this:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
The street_id column represents a “one to many” relationship between the
people object and the related street object, which is in the streets table.
Una forma de normalizar aún más la tabla es dividir el campo de nombre en first_name y last_name:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
We can also create separate tables for the town or city name and country,
linking them to our people table via “one to many” relationships:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
Un diagrama ER para representar esto se vería así:
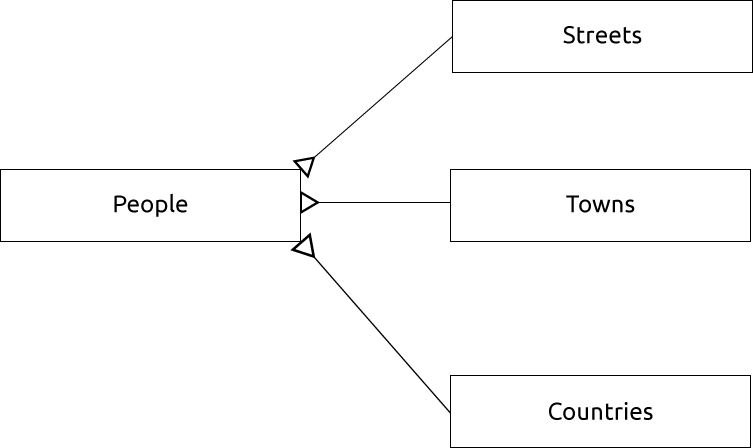
15.1.13. Restricciones, claves primarias y claves foráneas
A database constraint is used to ensure that data in a relation matches the
modeller’s view of how that data should be stored. For example a constraint on
your postal code could ensure that the number falls between 1000 and
9999.
Una clave primaria es uno o más valores de campo que hacen un único registro. Normalmente la clave primaria es llamada id y es una secuencia.
Una clave foránea es utilizada para referirse a un registro único en otra tabla (utilizando la clave primaria de esa otra tabla).
En diagramas de ER, el enlace entre tablas se basa normalmente en claves foráneas que enlazan con claves primarias.
Si miramos nuestro ejemplo de personas, la definición de la tabla muestra que la columna de la calle es una clave externa que hace referencia a la clave principal en la tabla de calles:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. Transacciones
Al añadir, cambiar o borrar datos en una base de datos, siempre es importante que se deje la base de datos en buen estado si algo va mal. La mayoría de la base de datos proporciona una característica llamada asistencia de transacciones. Las transacciones permiten crear una posición de reversión que se puede volver si sus modificaciones a la base de datos no se han ejecutado como estaba previsto.
Tome un esenario donde tenga un sistema de contabilidad. Necesita transferir fondos de una cuenta y añadirlos a otra. La secuencia de pasos sería algo así:
eliminar R20 de Joe
añadir R20 a Anne
Si algo va mal durante el proceso (por ejemplo, corte de energía), la transacción se deshace.
15.1.15. En conclusión
Las bases de datos le permite administrar datos en una forma estructurada utilizando estructuras de código sencillo.
15.1.16. ¿Y ahora qué?
Ahora que hemos visto en teoría cómo las bases de datos funcionan, vamos a crear una nueva base de datos para implementar la teoría que hemos cubierto.