Importante
La traducción es un esfuerzo comunitario tú puedes unirte. Esta página está actualmente traducida en 96.22%.
24.1.18. Análisis raster
24.1.18.1. Clasificación porcentual de la pila de celdas a partir del valor
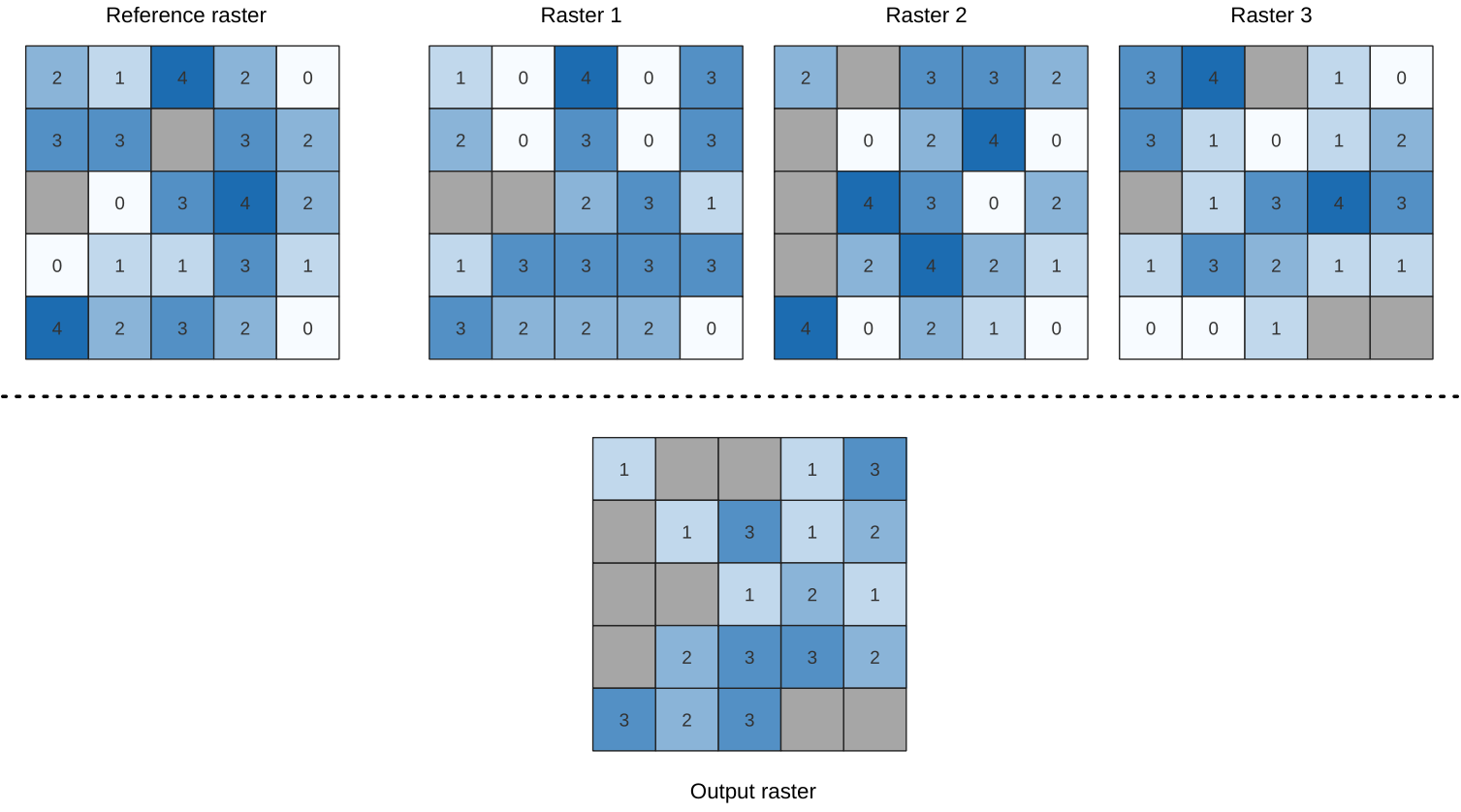
Calcula el valor de rango porcentual por celdas de una pila de rásters en función de un único valor de entrada y los escribe en un ráster de salida.
En cada ubicación de celda, el valor especificado se clasifica entre los valores respectivos en la pila de todos los valores de celda superpuestos y ordenados de los rásteres de entrada. Para valores fuera de la distribución de valores de pila, el algoritmo devuelve NoData porque el valor no se puede clasificar entre los valores de celda.
Hay dos métodos para el cálculo de percentiles:
Interpolación lineal inclusiva (PERCENTRANK.INC)
Interpolación lineal exclusiva (PERCENTRANK.EXC)
El método de interpolación lineal devuelve el rango porcentual único para diferentes valores. Ambos métodos de interpolación siguen sus métodos equivalentes implementados por LibreOffice or Microsoft Excel.
La extensión y la resolución del ráster de salida se definen mediante un ráster de referencia. Las capas ráster de entrada que no coincidan con el tamaño de celda de la capa ráster de referencia se volverán a muestrear mediante el remuestreo del vecino más cercano. Los valores NoData en cualquiera de las capas de entrada darán como resultado una salida de celda NoData si el parámetro «Ignore NoData values» no está configurado. El tipo de datos ráster de salida siempre será Float32.

Figura 24.50 Clasificación porcentual Valor = 1. Las celdas NoData (grises) se ignoran.
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capas de entrada |
|
[ráster] [lista] |
Capas ráster para evaluar. Si se utilizan rásteres multibanda en la pila de ráster de datos, el algoritmo siempre realizará el análisis en la primera banda de los rásteres. |
Methodo |
|
[enumeración] Predeterminado: 0 |
Método para el cálculo del percentil:
|
Valor |
|
[numérico: doble] Predeterminado: 10.0 |
Valor para clasificar entre los valores respectivos en la pila de todos los valores de celda superpuestos y ordenados de los rásters de entrada |
Ignorar valores NoData |
|
[booleano] Predeterminado: Verdadero |
Si no está marcada, cualquier celda NoData en las capas de entrada dará como resultado una celda NoData en el ráster de salida |
Capa de referencia |
|
[ráster] |
La capa de referencia para la creación de la capa de salida (extensión, SRC, dimensiones en píxeles) |
Capa de salida |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a utilizar para NoData en la capa de salida |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de salida |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[cadena de texto] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Código Python
Algoritmo ID: native:cellstackpercentrankfromvalue
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.2. percentil de pila de celdas
Calcula el valor del percentil por celdas de una pila de rásters y escribe los resultados en un ráster de salida. El percentil a devolver está determinado por el valor de entrada del percentil (intervalos entre 0 y 1). En cada ubicación de celda, el percentil especificado se obtiene utilizando el valor respectivo de la pila de todos los valores de celda superpuestos y ordenados de los rásters de entrada.
Hay tres métodos para el cálculo de percentiles:
Rango más cercano: devuelve el valor más cercano al percentil especificado
Interpolación lineal inclusiva (PERCENTRANK.INC)
Interpolación lineal exclusiva (PERCENTRANK.EXC)
Los métodos de interpolación lineal devuelven valores únicos para diferentes percentiles. Ambos métodos de interpolación siguen sus métodos homólogos implementados por LibreOffice or Microsoft Excel.
La extensión y la resolución del ráster de salida se definen mediante un ráster de referencia. Las capas ráster de entrada que no coincidan con el tamaño de celda de la capa ráster de referencia se volverán a muestrear mediante el remuestreo del vecino más cercano. Los valores NoData en cualquiera de las capas de entrada darán como resultado una salida de celda NoData si el parámetro «Ignore NoData values» no está configurado. El tipo de datos ráster de salida siempre será Float32.
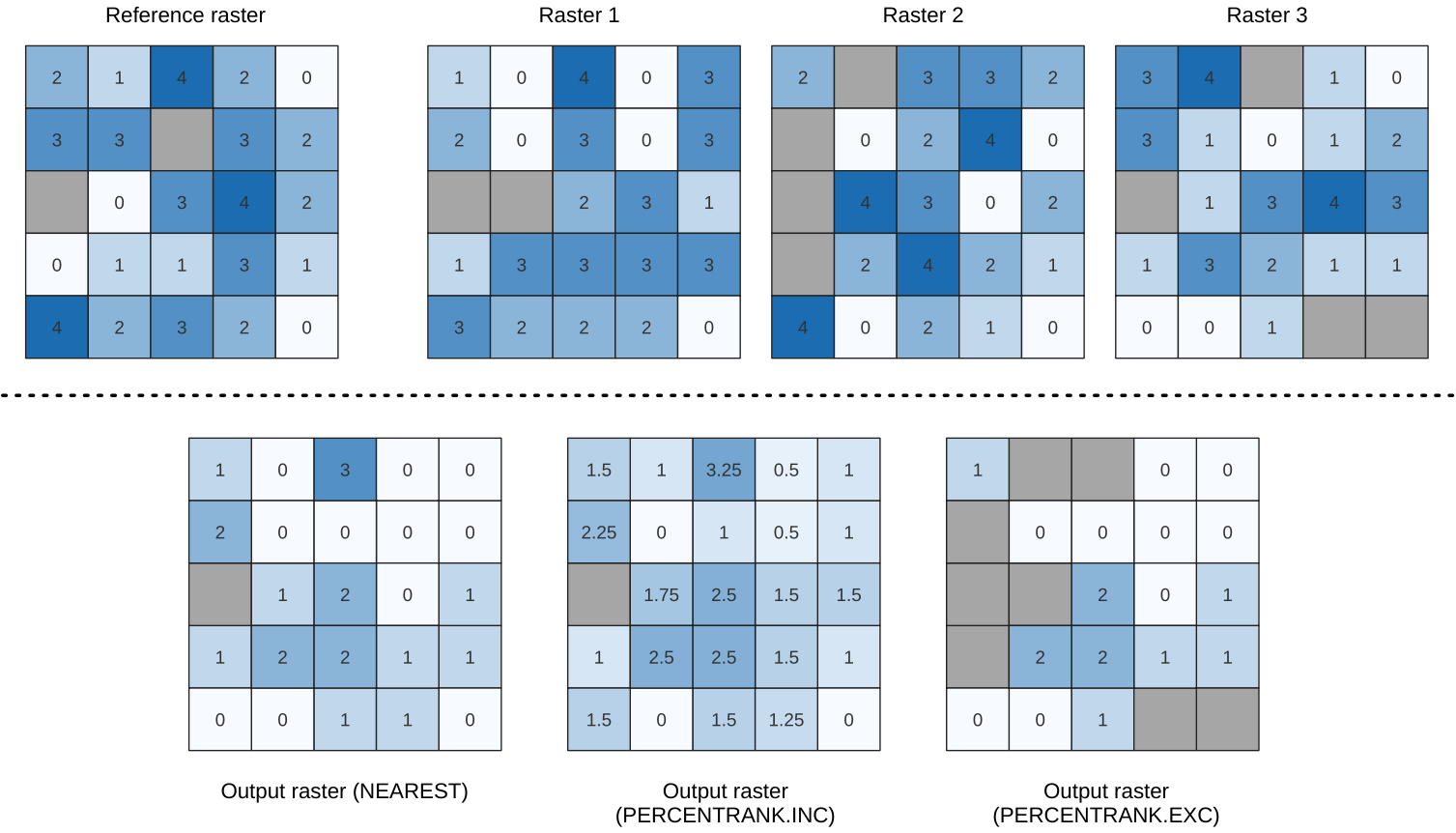
Figura 24.51 Percentil = 0,25. Las celdas NoData (grises) se ignoran.
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capas de entrada |
|
[ráster] [lista] |
Capas ráster para evaluar. Si se utilizan rásteres multibanda en la pila de ráster de datos, el algoritmo siempre realizará el análisis en la primera banda de los rásteres. |
Methodo |
|
[enumeración] Predeterminado: 0 |
Método para el cálculo del percentil:
|
Percentil |
|
[numérico: doble] Preestablecido: 0.25 |
Valor para clasificar entre los valores respectivos en la pila de todos los valores de celda superpuestos y ordenados de los rásteres de entrada. Entre 0 y 1. |
Ignorar valores NoData |
|
[booleano] Predeterminado: Verdadero |
Si no está marcada, cualquier celda NoData en las capas de entrada dará como resultado una celda NoData en el ráster de salida |
Capa de referencia |
|
[ráster] |
La capa de referencia para la creación de la capa de salida (extensión, SRC, dimensiones en píxeles) |
Capa de salida |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a utilizar para NoData en la capa de salida |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de salida |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[cadena de texto] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Código Python
Algoritmo ID: native:cellstackpercentile
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
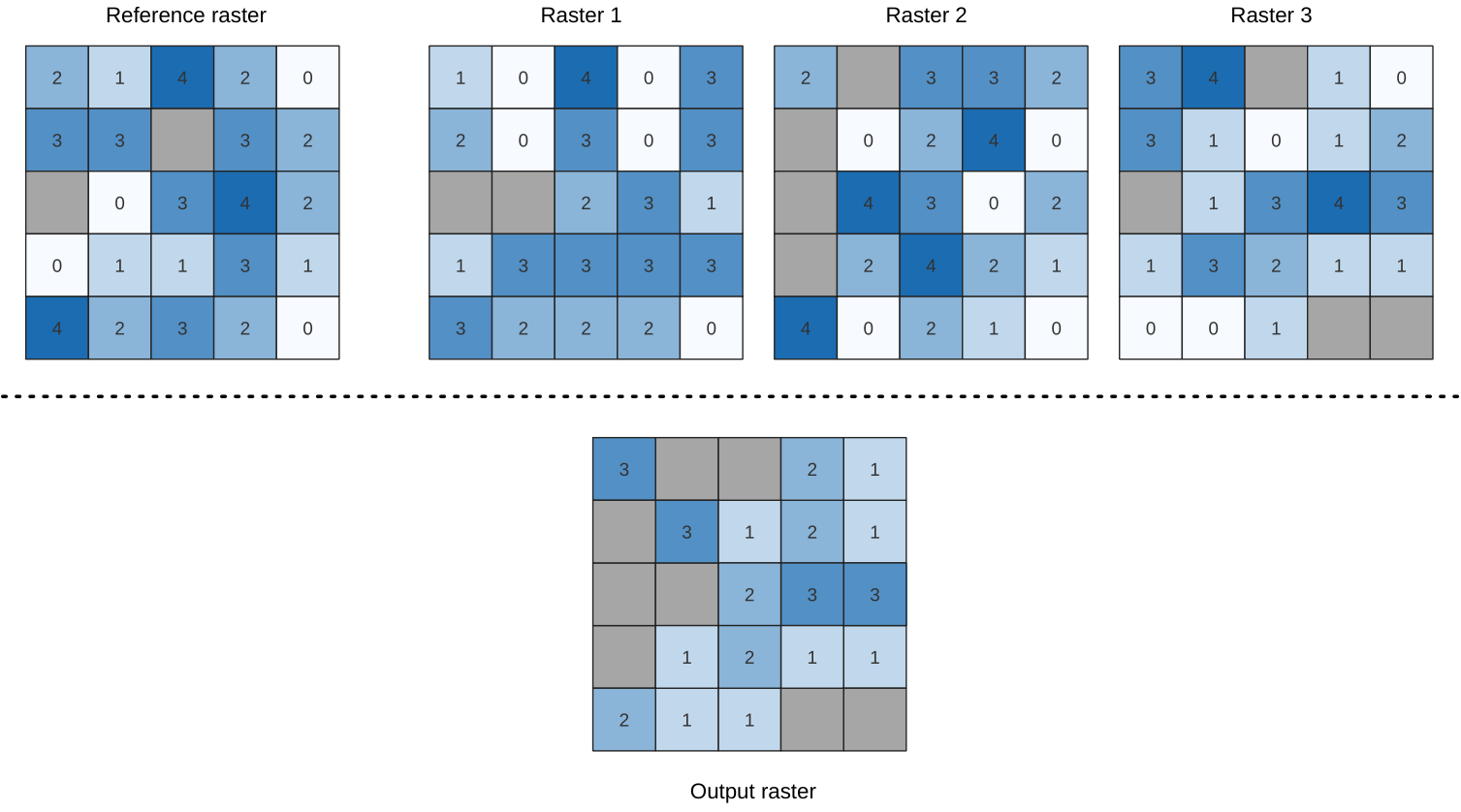
24.1.18.3. Porcentaje de la pila de celdas a partir de la capa ráster
Calcula el valor de rango porcentual por celdas de una pila de rásters en función de un ráster de valores de entrada y los escribe en un ráster de salida.
En cada ubicación de celda, el valor actual del ráster de valores se clasifica entre los valores respectivos en la pila de todos los valores de celda superpuestos y ordenados de los rásters de entrada. Para valores fuera de la distribución de valores de la pila, el algoritmo devuelve NoData porque el valor no se puede clasificar entre los valores de celda.
Hay dos métodos para el cálculo de percentiles:
Interpolación lineal inclusiva (PERCENTRANK.INC)
Interpolación lineal exclusiva (PERCENTRANK.EXC)
Los métodos de interpolación lineal devuelven valores únicos para diferentes percentiles. Ambos métodos de interpolación siguen sus métodos homólogos implementados por LibreOffice or Microsoft Excel.
La extensión y la resolución del ráster de salida se definen mediante un ráster de referencia. Las capas ráster de entrada que no coincidan con el tamaño de celda de la capa ráster de referencia se volverán a muestrear mediante el remuestreo del vecino más cercano. Los valores NoData en cualquiera de las capas de entrada darán como resultado una salida de celda NoData si el parámetro «Ignore NoData values» no está configurado. El tipo de datos ráster de salida siempre será Float32.
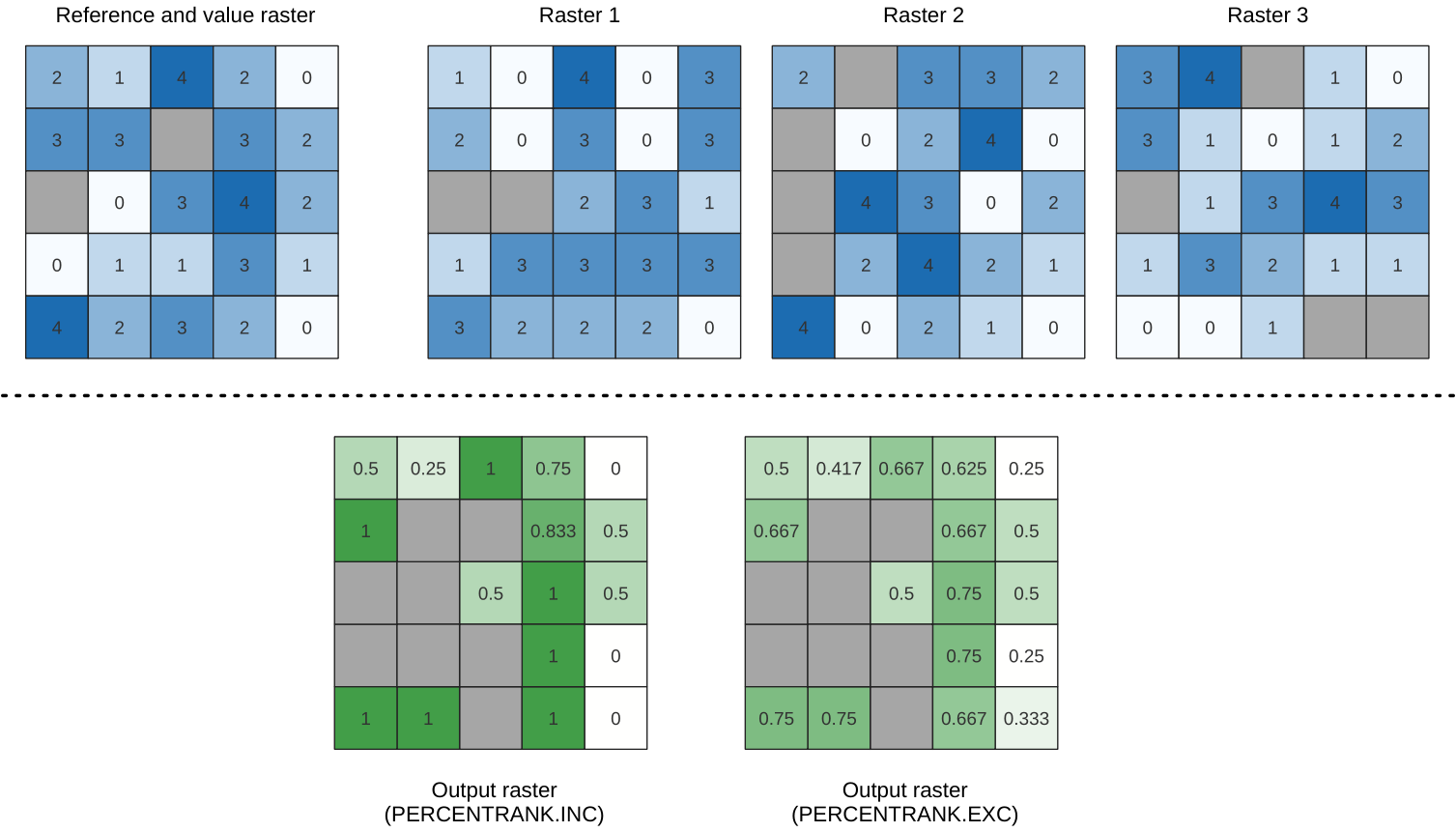
Figura 24.52 Clasificación de las celdas de la capa ráster de valor. Las celdas NoData (grises) se ignoran.
Ver también
percentil de pila de celdas, Clasificación porcentual de la pila de celdas a partir del valor
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capas de entrada |
|
[ráster] [lista] |
Capas ráster para evaluar. Si se utilizan rásteres multibanda en la pila de ráster de datos, el algoritmo siempre realizará el análisis en la primera banda de los rásteres. |
Capa ráster de valor |
|
[ráster] |
La capa para clasificar los valores entre la pila de todas las capas superpuestas |
Banda ráster de valor |
|
[numérico: entero] Predeterminado: 1 |
Banda de la «value raster layer» para comparar |
Methodo |
|
[enumeración] Predeterminado: 0 |
Método para el cálculo del percentil:
|
Ignorar valores NoData |
|
[booleano] Predeterminado: Verdadero |
Si no está marcada, cualquier celda NoData en las capas de entrada dará como resultado una celda NoData en el ráster de salida |
Capa de referencia |
|
[ráster] |
La capa de referencia para la creación de la capa de salida (extensión, SRC, dimensiones en píxeles) |
Capa de salida |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a utilizar para NoData en la capa de salida |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de salida |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[cadena de texto] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Código Python
Algoritmo ID: native:cellstackpercentrankfromrasterlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.4. Estadísticas de celda
Calcula estadísticas por celda basadas en capas ráster de entrada y para cada celda escribe las estadísticas resultantes en un ráster de salida. En cada ubicación de celda, el valor de salida se define como una función de todos los valores de celda superpuestos de los rásteres de entrada.
De forma predeterminada, una celda NoData en CUALQUIERA de las capas de entrada dará como resultado una celda NoData en el ráster de salida. Si la opción Ignorar valores NoData está marcada, las entradas NoData se ignorarán en el cálculo estadístico. Esto puede resultar en una salida NoData para ubicaciones donde todas las celdas son NoData.
El parámetro Capa de referencia especifica una capa ráster existente para usar como referencia al crear el ráster de salida. El ráster de salida tendrá la misma extensión, SRC y dimensiones de píxeles que esta capa.
Detalles del cálculo: Las capas ráster de entrada que no coincidan con el tamaño de celda de la capa ráster de referencia se volverán a muestrear utilizando el remuestreo del vecino más cercano. El tipo de datos ráster de salida se establecerá en el tipo de datos más complejo presente en los conjuntos de datos de entrada, excepto cuando se utilizan las funciones Media, Desviación estándar y Varianza (el tipo de datos siempre es Float32 o Float64 dependiendo del tipo de flotador de entrada) o Count y Variety (el tipo de datos es siempre Int32).
Recuento: la estadística de recuento siempre dará como resultado el número de celdas sin valores NoData en la ubicación de la celda actual.Mediana: si el número de capas de entrada es par, la mediana se calculará como la media aritmética de los dos valores medios de los valores de entrada de la celda ordenada.Minoría/Mayoría: Si no se pudo encontrar una minoría o mayoría única, el resultado es NoData, excepto que todos los valores de celda de entrada son iguales.
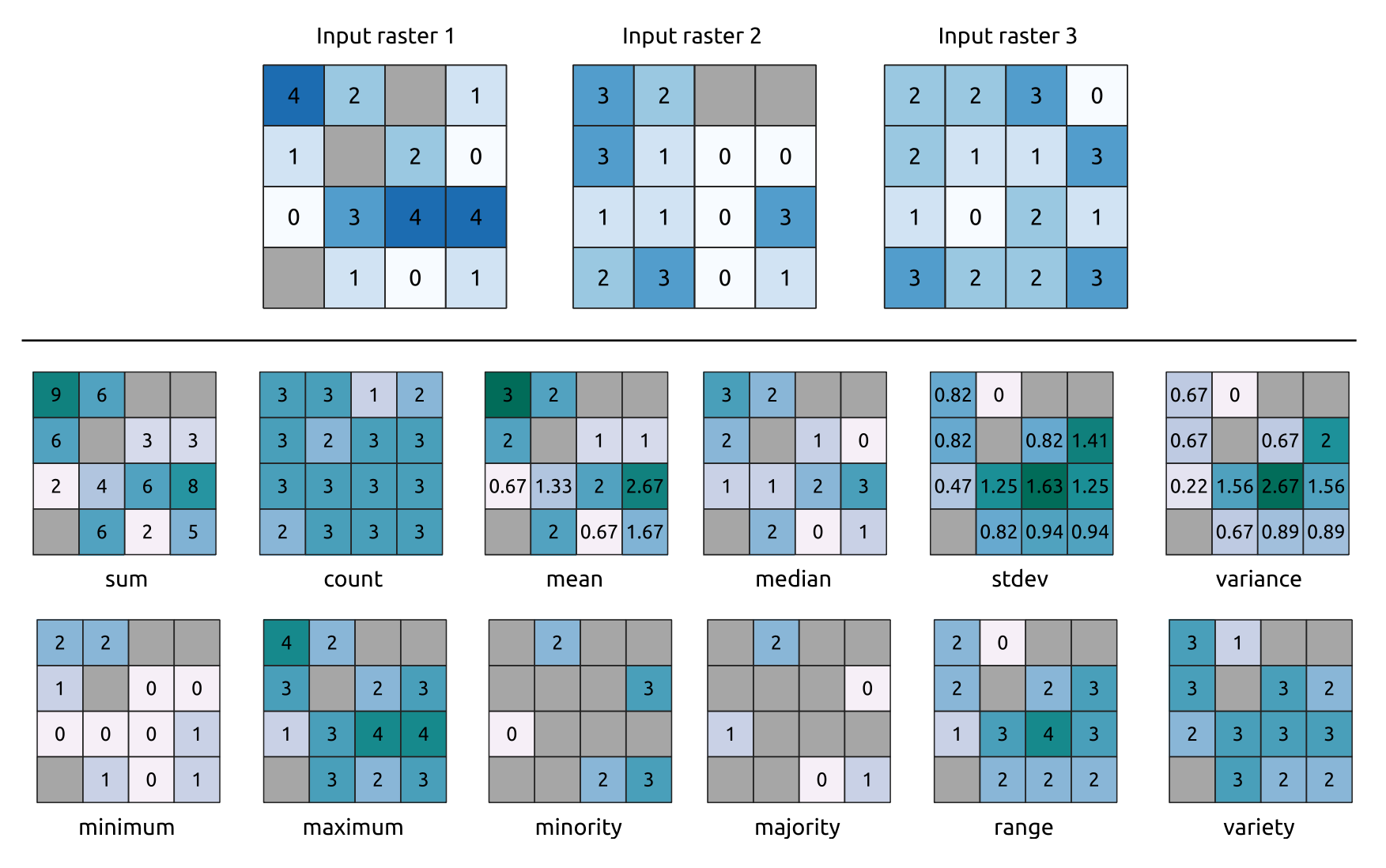
Figura 24.53 Ejemplo con todas las funciones estadísticas. Se tienen en cuenta las celdas NoData (grises).
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capas de entrada |
|
[ráster] [lista] |
Capas ráster entrantes |
Estadística |
|
[enumeración] Predeterminado: 0 |
Estadisticas disponibles. Opciones:
|
Ignorar valores NoData |
|
[booleano] Predeterminado: Verdadero |
Calcular estadísticas también para todas las pilas de celdas, ignorando la existencia de NoData. |
Capa de referencia |
|
[ráster] |
La capa de referencia desde la que crear la capa de salida (extensión, SRC, dimensiones en píxeles) |
Capa de salida |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData Opcional |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a utilizar para NoData en la capa de salida |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Identificador de autoridad de SRC |
|
[src] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Ráster de salida |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Código Python
Algoritmo ID: native:cellstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.5. Frecuencia de igualdad
Evalúa celda por celda la frecuencia (cantidad de veces) que los valores de una pila de entrada de rásteres son iguales al valor de una capa de valor. La extensión y resolución del ráster de salida están definidas por la capa ráster de entrada y siempre es del tipo Int32.
Si se utilizan rásteres multibanda en la pila de ráster de datos, el algoritmo siempre realizará el análisis en la primera banda de los rásteres; use GDAL para usar otras bandas en el análisis. El valor de salida sin datos se puede configurar manualmente.
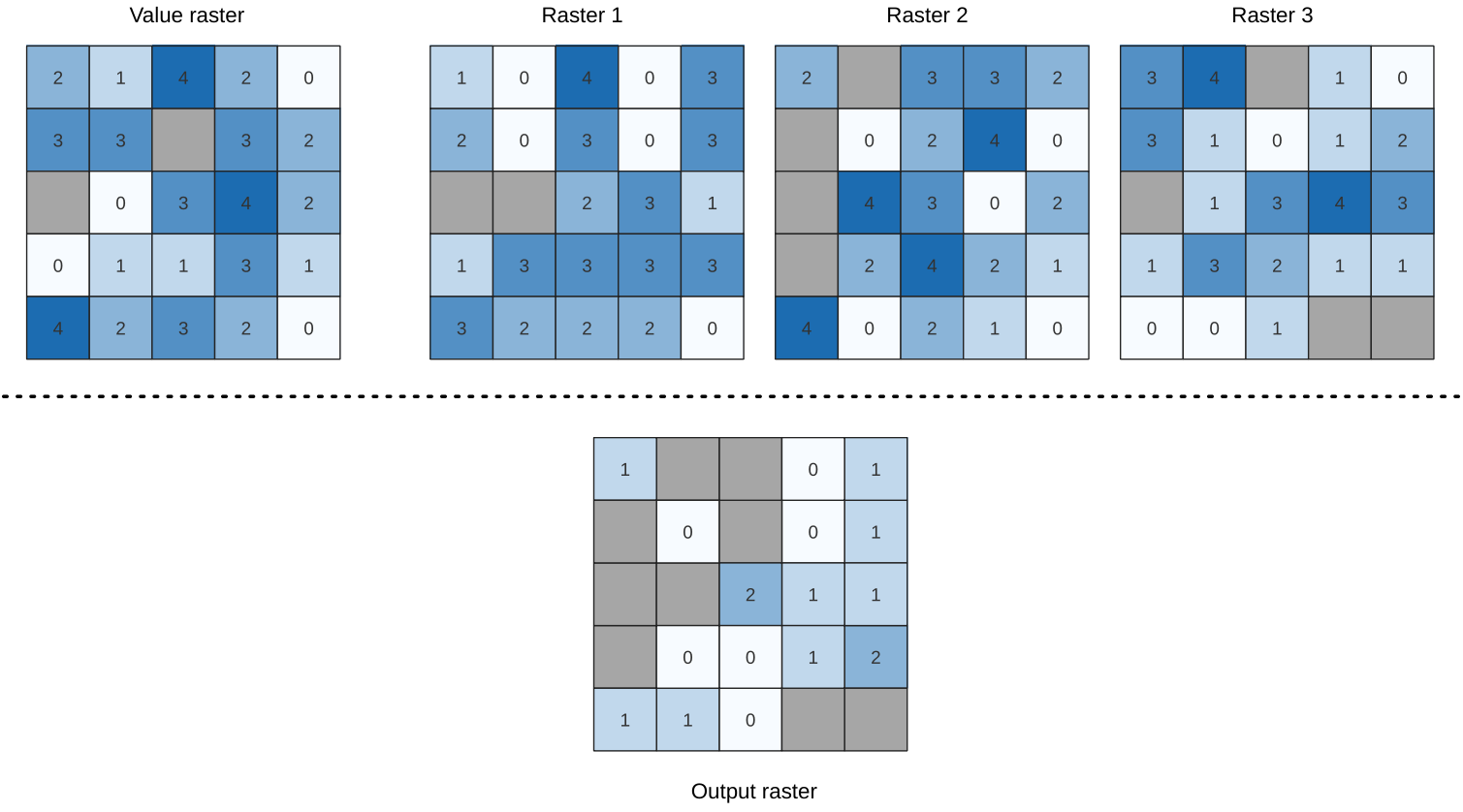
Figura 24.54 Para cada celda del ráster de salida, el valor representa la cantidad de veces que las celdas correspondientes en la lista de rásteres son iguales al ráster de valores. Se tienen en cuenta las celdas sin datos (grises).
Ver también
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor ráster de entrada |
|
[ráster] |
La capa de valor de entrada sirve como capa de referencia para las capas de muestra |
Banda ráster de valor |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Seleccione la banda que desea usar como muestra |
Capas ráster entrante |
|
[ráster] [lista] |
Capas ráster para evaluar. Si se utilizan rásteres multibanda en la pila de ráster de datos, el algoritmo siempre realizará el análisis en la primera banda de los rásteres. |
Ignorar valores NoData |
|
[booleano] Predeterminado: False |
Si no está marcada, cualquier celda sin datos en el ráster de valor o la pila de capas de datos dará como resultado una celda sin datos en el ráster de salida |
Capa de salida |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData Opcional |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a utilizar para NoData en la capa de salida |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de salida |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[cadena de texto] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Conteo de celdas con ocurrencias de valor igual |
|
[numérico: entero] |
|
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Frecuencia media en ubicaciones de celda válidas |
|
[numérico: doble] |
|
Conteo de ocurrencias del valor |
|
[numérico: entero] |
|
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Código Python
Algoritmo ID: native:equaltofrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.6. Ráster Fuzzify (pertenencia gaussiana)
Transforma un ráster de entrada en un ráster difuso asignando un valor de pertenencia a cada píxel, utilizando una función de pertenencia gaussiana. Los valores de pertenencia van de 0 a 1. En el ráster difuso, un valor de 0 implica que no hay pertenencia al conjunto difuso definido, mientras que un valor de 1 significa pertenencia total. La función de pertenencia gaussiana se define como  , donde f1 es la extensión y f2 el punto medio.
, donde f1 es la extensión y f2 el punto medio.
Figura 24.55 Fuzzify raster (gaussian membership) example (midpoint=300, spread=0.00001).
Ver también
Fuzzify ráster (gran número de miembros), Ráster Fuzzify (membresía linear), Fuzzify ráster (número de miembros cercanos), Ráster Fuzzify(influencia de membresía), Ràster Fuzzify (pequeña membresía)
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster de Entrada |
|
[ráster] |
Capa ráster de entrada |
Número de Banda |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Si el ráster es multibanda, elija la banda a la que aplicar fuzzify. |
Función Punto Medio |
|
[numérico: doble] Predeterminado: 10.0 |
Punto medio de la función gausiana |
Distribución de funciones |
|
[numérico: doble] Predeterminado: 0.01 |
Distribución de la función gausiana |
Ráster Fuzzified |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster Fuzzified |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[src] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Código Python
ID Algoritmo: native:fuzzifyrastergaussianmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.7. Fuzzify ráster (gran número de miembros)
Transforma un ráster de entrada en un ráster difuso asignando un valor de número de miembro a cada píxel, utilizando una función de membresía grande. Los valores de pertenencia van de 0 a 1. En el ráster difuso, un valor de 0 implica que no hay pertenencia al conjunto difuso definido, mientras que un valor de 1 significa pertenencia total. La función de gran número de miembros se define como  , donde f1 es la extensión y f2 el punto medio.
, donde f1 es la extensión y f2 el punto medio.

Figura 24.56 Fuzzify raster (large membership) example (midpoint=300, spread=10).
Ver también
Ráster Fuzzify (pertenencia gaussiana), Ráster Fuzzify (membresía linear), Fuzzify ráster (número de miembros cercanos), Ráster Fuzzify(influencia de membresía), Ràster Fuzzify (pequeña membresía)
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster de Entrada |
|
[ráster] |
Capa ráster de entrada |
Número de Banda |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Si el ráster es multibanda, elija la banda a la que aplicar fuzzify. |
Función Punto Medio |
|
[numérico: doble] Predeterminada: 50.0 |
Punto medio de una función larga |
Distribución de funciones |
|
[numérico: doble] Preestablecido: 5.0 |
Distribución de una función larga |
Ráster Fuzzified |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster Fuzzified |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[src] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Código Python
ID Algoritmo: native:fuzzifyrasterlargemembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.8. Ráster Fuzzify (membresía linear)
Transforma un ráster de entrada en un ráster difuso asignando un valor de pertenencia a cada píxel, utilizando una función de pertenencia lineal. Los valores de pertenencia van de 0 a 1. En el ráster difuso, un valor de 0 implica que no hay pertenencia al conjunto difuso definido, mientras que un valor de 1 significa pertenencia total. La función lineal se define como  , donde a es el límite inferior y b el límite superior. Esta ecuación asigna valores de pertenencia mediante una transformación lineal para valores de píxeles entre los límites inferior y superior. Los valores de píxeles más pequeños que el límite bajo reciben una membresía 0, mientras que los valores de píxeles mayores que el límite alto reciben 1 membresía.
, donde a es el límite inferior y b el límite superior. Esta ecuación asigna valores de pertenencia mediante una transformación lineal para valores de píxeles entre los límites inferior y superior. Los valores de píxeles más pequeños que el límite bajo reciben una membresía 0, mientras que los valores de píxeles mayores que el límite alto reciben 1 membresía.

Figura 24.57 Fuzzify raster (linear membership) example (low bound=100, high bound=590).
Ver también
Ráster Fuzzify (pertenencia gaussiana), Fuzzify ráster (gran número de miembros), Fuzzify ráster (número de miembros cercanos), Ráster Fuzzify(influencia de membresía), Ràster Fuzzify (pequeña membresía)
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster de Entrada |
|
[ráster] |
Capa ráster de entrada |
Número de Banda |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Si el ráster es multibanda, elija la banda a la que aplicar fuzzify. |
Límite de membresía difusa baja |
|
[numérico: doble] Predeterminado: 0.0 |
Límite inferior de la función lineal |
Límite alto de membresía difusa |
|
[numérico: doble] Predeterminado: 1.0 |
Límite Superior de la función lineal |
Ráster Fuzzified |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster Fuzzified |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[src] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Código Python
Algoritmo ID: native:fuzzifyrasterlinearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.9. Fuzzify ráster (número de miembros cercanos)
Transforma un ráster de entrada en un ráster difuso asignando un valor de pertenencia a cada píxel, utilizando una función de pertenencia cercana. Los valores de pertenencia van de 0 a 1. En el ráster difuso, un valor de 0 implica que no hay pertenencia al conjunto difuso definido, mientras que un valor de 1 significa pertenencia total. La función de membresía cercana se define como  , donde f1 es la extensión y f2 el punto medio.
, donde f1 es la extensión y f2 el punto medio.

Figura 24.58 Fuzzify raster (near membership) example (midpoint=300, spread=0.00001).
Ver también
Ráster Fuzzify (pertenencia gaussiana), Fuzzify ráster (gran número de miembros), Ráster Fuzzify (membresía linear), Ráster Fuzzify(influencia de membresía), Ràster Fuzzify (pequeña membresía)
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster de Entrada |
|
[ráster] |
Capa ráster de entrada |
Número de Banda |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Si el ráster es multibanda, elija la banda a la que aplicar fuzzify. |
Función Punto Medio |
|
[numérico: doble] Predeterminada: 50.0 |
Punto medio de la función vecino |
Distribución de funciones |
|
[numérico: doble] Predeterminado: 0.01 |
Extensión de la función vecino |
Ráster Fuzzified |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster Fuzzified |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[src] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Código Python
Algoritmo ID: native:fuzzifyrasternearmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.10. Ráster Fuzzify(influencia de membresía)
Transforma un ráster de entrada en un ráster difuso asignando un valor de membresía a cada píxel, utilizando una función de membresía de influencia. Los valores de pertenencia van de 0 a 1. En el ráster difuso, un valor de 0 implica que no hay pertenencia al conjunto difuso definido, mientras que un valor de 1 significa pertenencia total. La función de potencia se define como  , donde a es el límite inferior, b es el límite superior y f1 el exponente. Esta ecuación asigna valores de pertenencia utilizando la transformación de potencia para los valores de píxeles entre los límites inferior y superior. Los valores de píxeles más pequeños que el límite bajo reciben una membresía 0, mientras que los valores de píxeles mayores que el límite alto reciben 1 membresía.
, donde a es el límite inferior, b es el límite superior y f1 el exponente. Esta ecuación asigna valores de pertenencia utilizando la transformación de potencia para los valores de píxeles entre los límites inferior y superior. Los valores de píxeles más pequeños que el límite bajo reciben una membresía 0, mientras que los valores de píxeles mayores que el límite alto reciben 1 membresía.

Figura 24.59 Fuzzify raster (power membership) example (low bound=100, high bound=590, membership exponent=2).
Ver también
Ráster Fuzzify (pertenencia gaussiana), Fuzzify ráster (gran número de miembros), Ráster Fuzzify (membresía linear), Fuzzify ráster (número de miembros cercanos), Ràster Fuzzify (pequeña membresía)
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster de Entrada |
|
[ráster] |
Capa ráster de entrada |
Número de Banda |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Si el ráster es multibanda, elija la banda a la que aplicar fuzzify. |
Límite de membresía difusa baja |
|
[numérico: doble] Predeterminado: 0.0 |
Límite inferior de la función de influencia |
Límite alto de membresía difusa |
|
[numérico: doble] Predeterminado: 1.0 |
Límite superior de la función de influencia |
Límite alto de membresía difusa |
|
[numérico: doble] Preestablecido: 2.0 |
Exponente de la función de influencia |
Ráster Fuzzified |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster Fuzzified |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[src] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Código Python
Algoritmo ID: native:fuzzifyrasterpowermembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.11. Ràster Fuzzify (pequeña membresía)
Transforma un ráster de entrada en un ráster difuso asignando un valor de pertenencia a cada píxel, utilizando una función de pertenencia pequeña. Los valores de pertenencia van de 0 a 1. En el ráster difuso, un valor de 0 implica que no hay pertenencia al conjunto difuso definido, mientras que un valor de 1 significa pertenencia total. La función de pertenencia pequeña se define como |fórmula_pequeña|, donde f1 es el margen y f2 el punto medio.

Figura 24.60 Fuzzify raster (small membership) example (midpoint=300, spread=10).
Ver también
Ráster Fuzzify (pertenencia gaussiana), Fuzzify ráster (gran número de miembros) Ráster Fuzzify (membresía linear), Fuzzify ráster (número de miembros cercanos), Ráster Fuzzify(influencia de membresía)
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster de Entrada |
|
[ráster] |
Capa ráster de entrada |
Número de Banda |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Si el ráster es multibanda, elija la banda a la que aplicar fuzzify. |
Función Punto Medio |
|
[numérico: doble] Predeterminada: 50.0 |
Punto medio de la función pequeña |
Distribución de funciones |
|
[numérico: doble] Preestablecido: 5.0 |
Extensión de la función pequeña |
Ráster Fuzzified |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster Fuzzified |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[src] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Código Python
Algoritmo ID: native:fuzzifyrastersmallmembership
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.12. Frecuencia mayor que
Evalúa celda por celda la frecuencia (cantidad de veces) que los valores de una pila de rásteres de entrada son iguales al valor de un ráster de valores. La extensión y resolución del ráster de salida está definida por la capa ráster de entrada y siempre es del tipo Int32.
Si se utilizan rásteres multibanda en la pila de ráster de datos, el algoritmo siempre realizará el análisis en la primera banda de los rásteres; use GDAL para usar otras bandas en el análisis. El valor de salida sin datos se puede configurar manualmente.
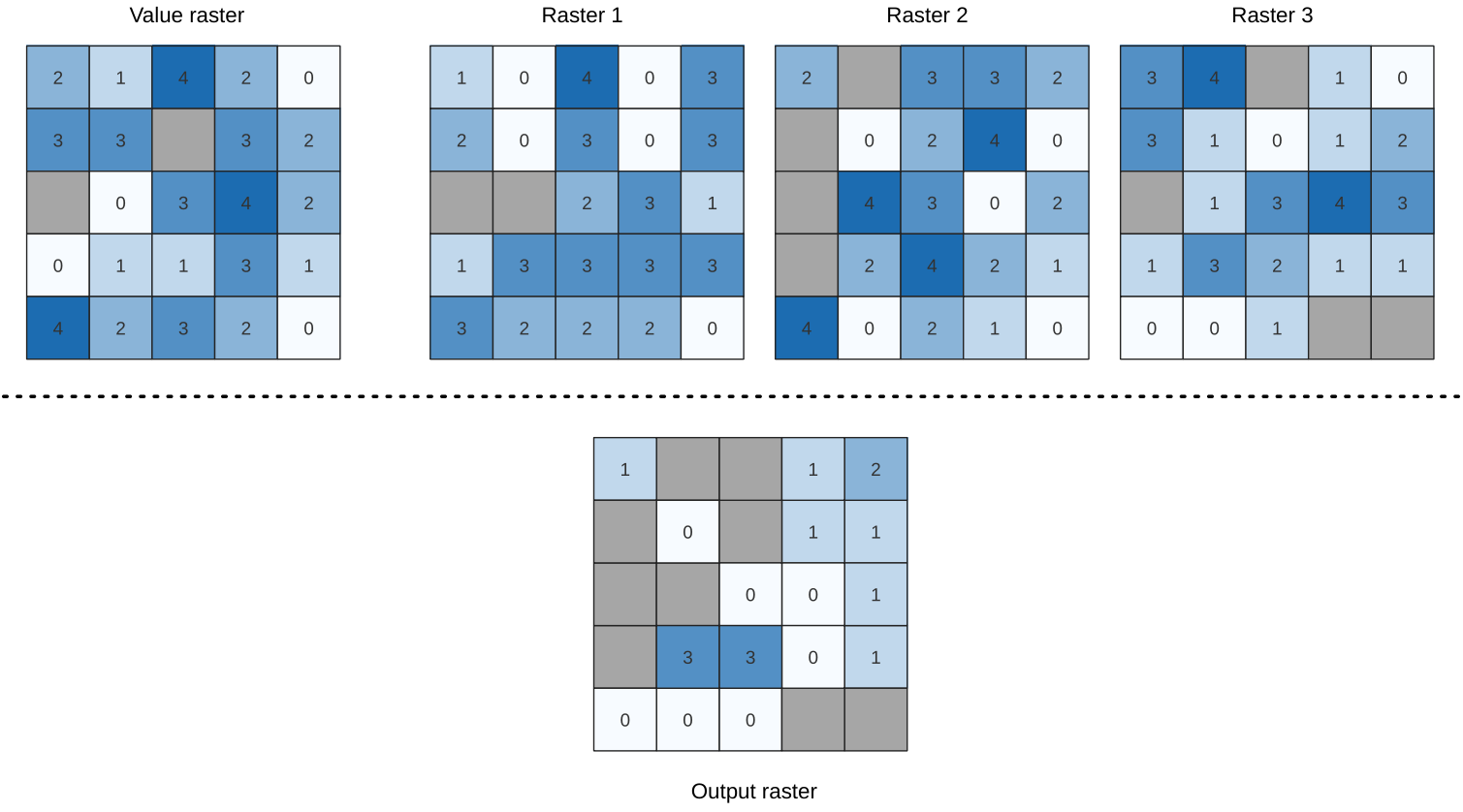
Figura 24.61 Para cada celda del ráster de salida, el valor representa la cantidad de veces que las celdas correspondientes en la lista de rásteres son mayores que el ráster de valor. Se tienen en cuenta las celdas NoData (grises).
Ver también
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor ráster de entrada |
|
[ráster] |
La capa de valor de entrada sirve como capa de referencia para las capas de muestra |
Banda ráster de valor |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Seleccione la banda que desea usar como muestra |
Capas ráster entrante |
|
[ráster] [lista] |
Capas ráster para evaluar. Si se utilizan rásteres multibanda en la pila de ráster de datos, el algoritmo siempre realizará el análisis en la primera banda de los rásteres. |
Ignorar valores NoData |
|
[booleano] Predeterminado: False |
Si no está marcada, cualquier celda sin datos en el ráster de valor o la pila de capas de datos dará como resultado una celda sin datos en el ráster de salida |
Capa de salida |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData Opcional |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a utilizar para NoData en la capa de salida |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de salida |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[cadena de texto] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Conteo de celdas con ocurrencias de valor igual |
|
[numérico: entero] |
|
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Frecuencia media en ubicaciones de celda válidas |
|
[numérico: doble] |
|
Conteo de ocurrencias del valor |
|
[numérico: entero] |
|
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Código Python
Algoritmo ID: native:greaterthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.13. Posición más alta en pila ráster
Evalúa celda por celda la posición del ráster con el valor más alto en una pila de rásteres. Los conteos de posición comienzan con 1 y van hasta el número total de rásteres de entrada. El orden de los rásteres de entrada es relevante para el algoritmo. Si múltiples rásteres presentan el valor más alto, el primer ráster se utilizará para el valor de posición.
Si se utilizan rásteres multibanda en la pila de ráster de datos, el algoritmo siempre realizará el análisis en la primera banda de los rásteres; use GDAL para usar otras bandas en el análisis. Cualquier celda sin datos en la pila de capas ráster dará como resultado una celda sin datos en el ráster de salida a menos que se marque el parámetro «ignore NoData». El valor de salida sin datos se puede configurar manualmente. La extensión y resolución de los rásteres de salida está definida por una capa ráster de referencia y siempre es del tipo Int32.
Ver también
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capas ráster entrante |
|
[ráster] [lista] |
Lista de capas ráster para comparar |
Capa de referencia |
|
[ráster] |
La capa de referencia para la creación de la capa de salida (extensión, SRC, dimensiones en píxeles) |
Ignorar valores NoData |
|
[booleano] Predeterminado: False |
Si no está marcada, cualquier celda sin datos en la pila de capas de datos dará como resultado una celda sin datos en el ráster de salida |
Capa de salida |
|
[ráster] Predeterinado: |
Especificación de la trama de salida que contiene el resultado. Uno de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a utilizar para NoData en la capa de salida |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de salida |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[cadena de texto] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Código Python
Algoritmo ID: native:highestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.14. Frecuencia menor que
Evalúa celda por celda la frecuencia (cantidad de veces) que los valores de una pila de rásteres de entrada son menores que el valor de un ráster de valores. La extensión y resolución del ráster de salida está definida por la capa ráster de entrada y siempre es del tipo Int32.
Si se utilizan rásteres multibanda en la pila de ráster de datos, el algoritmo siempre realizará el análisis en la primera banda de los rásteres; use GDAL para usar otras bandas en el análisis. El valor de salida sin datos se puede configurar manualmente.
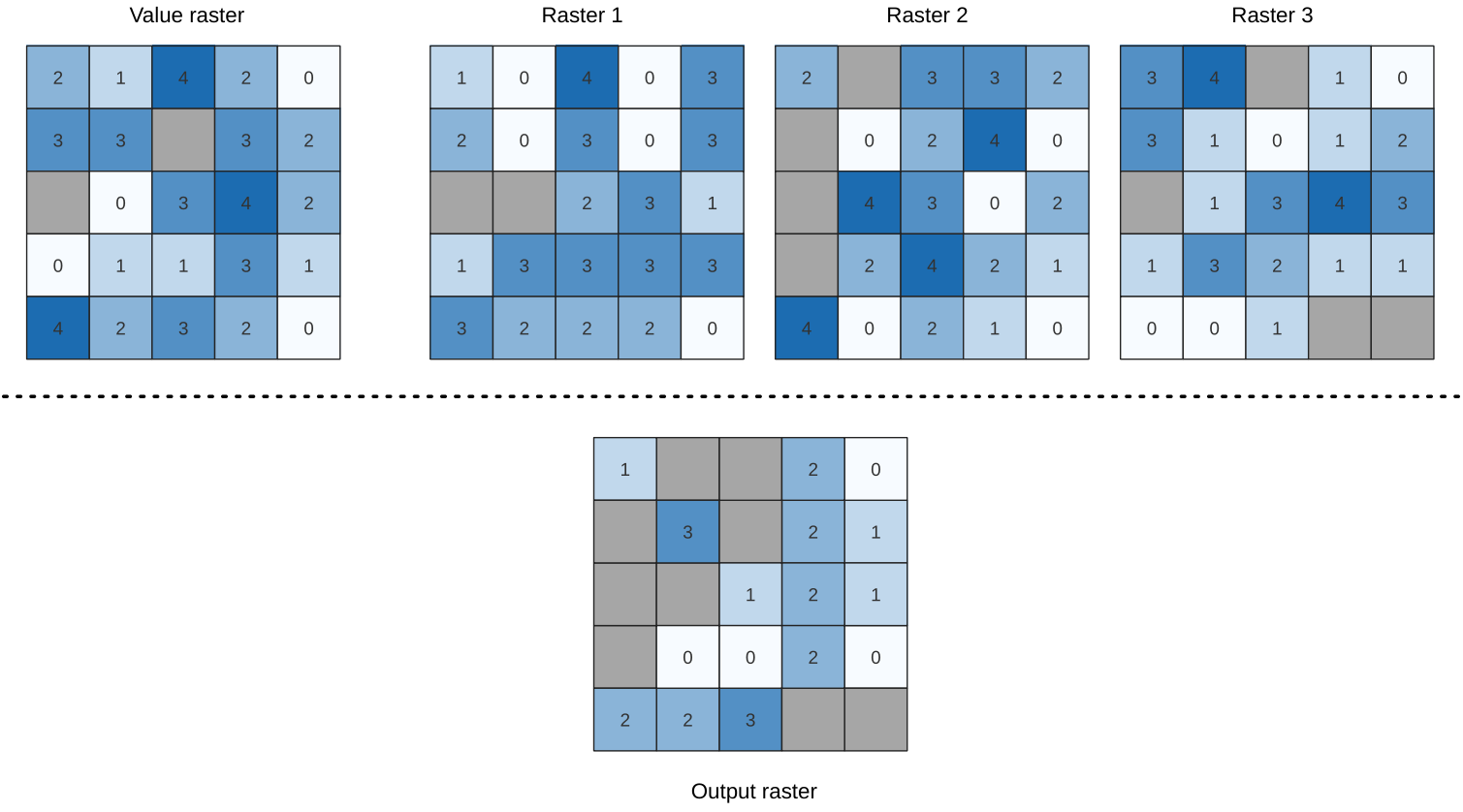
Figura 24.62 Para cada celda del ráster de salida, el valor representa la cantidad de veces que las celdas correspondientes en la lista de rásteres son menores que el ráster de valor. Se tienen en cuenta las celdas NoData (grises).
Ver también
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor ráster de entrada |
|
[ráster] |
La capa de valor de entrada sirve como capa de referencia para las capas de muestra |
Banda ráster de valor |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Seleccione la banda que desea usar como muestra |
Capas ráster entrante |
|
[ráster] [lista] |
Capas ráster para evaluar. Si se utilizan rásteres multibanda en la pila de ráster de datos, el algoritmo siempre realizará el análisis en la primera banda de los rásteres. |
Ignorar valores NoData |
|
[booleano] Predeterminado: False |
Si no está marcada, cualquier celda sin datos en el ráster de valor o la pila de capas de datos dará como resultado una celda sin datos en el ráster de salida |
Capa de salida |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData Opcional |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a utilizar para NoData en la capa de salida |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de salida |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[cadena de texto] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Conteo de celdas con ocurrencias de valor igual |
|
[numérico: entero] |
|
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Frecuencia media en ubicaciones de celda válidas |
|
[numérico: doble] |
|
Conteo de ocurrencias del valor |
|
[numérico: entero] |
|
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Código Python
Algoritmo ID: native:lessthanfrequency
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.15. Posición más baja en pila ráster
Evalúa celda por celda la posición del ráster con el valor más bajo en una pila de rásteres. Los conteos de posición comienzan con 1 y van hasta el número total de rásteres de entrada. El orden de los rásteres de entrada es relevante para el algoritmo. Si varios rásteres presentan el valor más bajo, el primer ráster se utilizará para el valor de posición.
Si se utilizan rásteres multibanda en la pila de ráster de datos, el algoritmo siempre realizará el análisis en la primera banda de los rásteres; use GDAL para usar otras bandas en el análisis. Cualquier celda sin datos en la pila de capas ráster dará como resultado una celda sin datos en el ráster de salida a menos que se marque el parámetro «ignore NoData». El valor de salida sin datos se puede configurar manualmente. La extensión y resolución de los rásteres de salida está definida por una capa ráster de referencia y siempre es del tipo Int32.
Ver también
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capas ráster entrante |
|
[ráster] [lista] |
Lista de capas ráster para comparar |
Capa de referencia |
|
[ráster] |
La capa de referencia para la creación de la capa de salida (extensión, SRC, dimensiones en píxeles) |
Ignorar valores NoData |
|
[booleano] Predeterminado: False |
Si no está marcada, cualquier celda sin datos en la pila de capas de datos dará como resultado una celda sin datos en el ráster de salida |
Capa de salida |
|
[ráster] Predeterinado: |
Especificación de la trama de salida que contiene el resultado. Uno de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a utilizar para NoData en la capa de salida |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de salida |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Identificador de autoridad de SRC |
|
[cadena de texto] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Código Python
Algoritmo ID: native:lowestpositioninrasterstack
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.16. Ráster Booleano AND
Calcula el valor booleano AND para un conjunto de rásteres de entrada. Si todos los rásteres de entrada tienen un valor distinto de cero para un píxel, ese píxel se establecerá en 1 en el ráster de salida. Si alguno de los rásteres de entrada tiene valores de 0 para el píxel, se establecerá en 0 en el ráster de salida.
El parámetro de la capa de referencia especifica una capa ráster existente para usar como referencia al crear el ráster de salida. El ráster de salida tendrá la misma extensión, SRC y dimensiones de píxeles que esta capa.
De forma predeterminada, un píxel NoData en CUALQUIERA de las capas de entrada resultará en un píxel NoData en el ráster de salida. Si la opción Tratar los valores NoData como falsos está marcada, las entradas NoData se tratarán igual que un valor de entrada 0.

Figura 24.63 Raster boolean AND example.
Ver también
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capas de entrada |
|
[ráster] [lista] |
Lista de capas ráster entrantes |
Capa de referencia |
|
[ráster] |
La capa de referencia desde la que crear la capa de salida (extensión, SRC, dimensiones en píxeles) |
Tratar los valores NoData como falsos |
|
[booleano] Predeterminado: False |
Tratar como 0 los valores NoData de los ficheros de entrada al realizar la operación. |
Capa de salida |
|
[ráster] Predeterinado: |
Especificación de la trama de salida que contiene el resultado. Uno de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a utilizar para NoData en la capa de salida |
Tipo de datos salientes |
|
[enumeración] Predeterminado: 5 |
Tipos de datos ráster salientes. Opciones:
Las opciones disponibles dependen de la versión de GDAL compilada con QGIS (vea l menú ) |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Identificador de autoridad de SRC |
|
[src] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Recuento de píxeles sin datos |
|
[numérico: entero] |
Recuento de píxeles NoData en la capa ráster de salida |
El recuento de pixels con valor True |
|
[numérico: entero] |
El recuento de pixels con valor verdadero (valor = 1) en la capa ráster saliente |
Recuento de pixels con valor False |
|
[numérico: entero] |
El recuento de pixels con valor falso (valor = 0) en la capa ráster saliente |
Capa de salida |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Código Python
Algoritmo ID: native:rasterbooleanand
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.17. Ráster Booleano OR
Calculates the boolean OR for a set of input rasters. If any of the input rasters have a non-zero value for a pixel, that pixel will be set to 1 in the output raster. If all the input rasters have 0 values for the pixel it will be set to 0 in the output raster.
El parámetro de la capa de referencia especifica una capa ráster existente para usar como referencia al crear el ráster de salida. El ráster de salida tendrá la misma extensión, SRC y dimensiones de píxeles que esta capa.
De forma predeterminada, un píxel NoData en CUALQUIERA de las capas de entrada resultará en un píxel NoData en el ráster de salida. Si la opción Tratar los valores NoData como falsos está marcada, las entradas NoData se tratarán igual que un valor de entrada 0.

Figura 24.64 Raster boolean OR example.
Ver también
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capas de entrada |
|
[ráster] [lista] |
Lista de capas ráster entrantes |
Capa de referencia |
|
[ráster] |
La capa de referencia desde la que crear la capa de salida (extensión, SRC, dimensiones en píxeles) |
Tratar los valores NoData como falsos |
|
[booleano] Predeterminado: False |
Tratar como 0 los valores NoData de los ficheros de entrada al realizar la operación. |
Capa de salida |
|
[ráster] Predeterinado: |
Especificación de la trama de salida que contiene el resultado. Uno de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a utilizar para NoData en la capa de salida |
Tipo de datos salientes |
|
[enumeración] Predeterminado: 5 |
Tipos de datos ráster salientes. Opciones:
Las opciones disponibles dependen de la versión de GDAL compilada con QGIS (vea l menú ) |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Identificador de autoridad de SRC |
|
[src] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Recuento de píxeles sin datos |
|
[numérico: entero] |
Recuento de píxeles NoData en la capa ráster de salida |
El recuento de pixels con valor True |
|
[numérico: entero] |
El recuento de pixels con valor verdadero (valor = 1) en la capa ráster saliente |
Recuento de pixels con valor False |
|
[numérico: entero] |
El recuento de pixels con valor falso (valor = 0) en la capa ráster saliente |
Capa de salida |
|
[ráster] |
Capa ráster saliente contenedora del resultado |
Código Python
Algoritmo ID: native:rasterbooleanor
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.18. Calculadora ráster
Ejecuta operaciones algebraicas usando capas ráster.
La capa resultante tendrá sus valores calculados de acuerdo con una expresión. La expresión puede contener valores numéricos, operadores y referencias a cualquiera de las capas del proyecto actual.
Ver también
Calculadora Ráster (virtual), Calculadora ráster, Calculadora Ráster
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capas de entrada |
|
[ráster] [lista] |
Lista de capas ráster entrantes |
Expresión |
|
[expresión] |
Expresión basada en ráster que se utilizará para calcular la capa ráster de salida. |
Extensión de salida Opcional |
|
[extensión] |
Especifique la extensión espacial de la capa ráster de salida. Si no se especifica la extensión, se utilizará la extensión mínima que cubra todas las capas de referencia seleccionadas. Los métodos disponibles son:
|
Tamaño de la celda de salida (dejar vacío para que se ajuste automáticamente). Opcional |
|
[numérico: doble] |
Tamaño de celda de la capa ráster de salida. Si no se especifica el tamaño de celda, se utilizará el tamaño de celda mínimo de la capa(s) de referencia seleccionada. El tamaño de celda será el mismo para los ejes X e Y. |
SRC saliente Opcional |
|
[src] |
SRC de la capa ráster de salida. Si no se especifica el SRC de salida, se utilizará el SRC de la primera capa de referencia. |
Calculado |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Opciones de creación Opcional |
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Calculado |
|
[ráster] |
Archivo ráster saliente con los valores calculados. |
Código Python
ID Algoritmo: native:rastercalc
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.19. Calculadora Ráster (virtual)
Added in 3.34
Realiza operaciones algebraicas con capas ráster y genera resultados en memoria.
La capa resultante tendrá sus valores calculados de acuerdo con una expresión. La expresión puede contener valores numéricos, operadores y referencias a cualquiera de las capas del proyecto actual.
Una capa ráster virtual es una capa ráster definida por su URI y cuyos píxeles se calculan sobre la marcha. No se trata de un nuevo archivo en el disco; la capa ráster virtual sigue conectada a las capas ráster utilizadas en el cálculo, lo que significa que borrar o mover estas capas ráster la dañaría. Se puede proporcionar una etiqueta Nombre de la capa, de lo contrario la expresión del cálculo se utiliza como tal. Al eliminar la capa virtual del proyecto se borra, y puede hacerse persistente en un archivo utilizando el menú contextual de la capa .
Ver también
Parámetros
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capas de entrada |
|
[ráster] [lista] |
Lista de capas ráster entrantes |
Expresión |
|
[expresión] |
Expresión basada en ráster que se utilizará para calcular la capa ráster de salida. |
Extensión de salida Opcional |
|
[extensión] |
Especifique la extensión espacial de la capa ráster de salida. Si no se especifica la extensión, se utilizará la extensión mínima que cubra todas las capas de referencia seleccionadas. Los métodos disponibles son:
|
Tamaño de la celda de salida (dejar vacío para que se ajuste automáticamente). Opcional |
|
[numérico: doble] |
Tamaño de celda de la capa ráster de salida. Si no se especifica el tamaño de celda, se utilizará el tamaño de celda mínimo de la capa(s) de referencia seleccionada. El tamaño de celda será el mismo para los ejes X e Y. |
SRC saliente Opcional |
|
[src] |
SRC de la capa ráster de salida. Si no se especifica el SRC de salida, se utilizará el SRC de la primera capa de referencia. |
Nombre de la capa de salida Opcional |
|
[cadena de texto] |
El nombre a asignar a la capa generada. Si no se establece, se utiliza el texto de la expresión de cálculo. |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Calculado |
|
[ráster] |
Salida de la capa ráster virtual con los valores calculados. |
Código Python
ID Algoritmo: native:virtualrastercalc
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.20. Propiedades de capa ráster
Devuelve las propiedades básicas de la capa ráster dada, incluyendo la extensión, el tamaño en píxeles y las dimensiones de los píxeles (en unidades de mapa), el número de bandas y el valor NoData.
Este algoritmo está diseñado para usarse como un medio para extraer estas propiedades útiles para usarlas como valores de entrada para otros algoritmos en un modelo, p. ej. para permitir pasar los tamaños de píxeles de un ráster existente a un algoritmo de ráster GDAL.
Parámetros
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada |
|
[ráster] |
Capa ráster de entrada |
Número de banda Opcional |
|
[banda ráster] Predeterminado: No establecido |
Si devolver también las propiedades de una banda específica. Si se especifica una banda, también se devuelve el valor noData para la banda seleccionada. |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Número de bandas en raster |
|
[numérico: entero] |
El número de bandas en el ráster |
Identificador de autoridad de SRC |
|
[cadena de texto] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión de la capa ráster en el CRS |
La banda tiene un conjunto de valores NoData |
|
[Booleano] |
Indica si la capa ráster tiene un valor establecido para los píxeles NoData en la banda seleccionada. |
Altura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster |
Valor de la banda NoData |
|
[numérico: doble] |
El valor (si está configurado) de los píxeles NoData en la banda seleccionada |
Tamaño de píxel (altura) en unidades de mapa |
|
[numérico: entero] |
Tamaño vertical en unidades de mapa del píxel |
Tamaño de píxel (ancho) en unidades de mapa |
|
[numérico: entero] |
Tamaño horizontal en unidades de mapa del píxel |
Anchura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster |
Coordenada x máxima |
|
[numérico: doble] |
|
Coordenada x mínima |
|
[numérico: doble] |
|
Coordenada y máxima |
|
[numérico: doble] |
|
Coordenada y mínima |
|
[numérico: doble] |
Código Python
Algoritmo ID: native:rasterlayerproperties
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.21. Estadísticas de capa ráster
Calcula estadísticas básicas a partir de los valores de una banda dada de la capa ráster. La salida se carga en el menú .
Parámetros
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada |
|
[ráster] |
Capa ráster de entrada |
Número de banda |
|
[banda ráster] Predeterminado: La primera banda de la capa entrante |
SI el ráster es multibanda, elija la banda de la que quiera obtener las estadísticas. |
Estadísticas |
|
[html] Predeterinado: |
Especificación del archivo de salida:
|
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor máximo |
|
[numérico: doble] |
|
Valor promedio |
|
[numérico: doble] |
|
Valor mínimo |
|
[numérico: doble] |
|
Estadísticas |
|
[html] |
El archivo de salida contiene la siguiente información:
|
Rango |
|
[numérico: doble] |
|
Desviación estándar |
|
[numérico: doble] |
|
Suma |
|
[numérico: doble] |
|
Suma de cuadrados |
|
[numérico: doble] |
Código Python
Algorithm ID: native:rasterlayerstatistics
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.22. Informe de valores únicos de capa ráster
Devuelve el recuento y el área de cada valor único en una capa ráster dada. El cálculo del área se realiza en la unidad de área del SRC de la capa.
Parámetros
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada |
|
[ráster] |
Capa ráster de entrada |
Número de banda |
|
[banda ráster] Predeterminado: La primera banda de la capa entrante |
SI el ráster es multibanda, elija la banda de la que quiera obtener las estadísticas. |
Informe de valores únicos |
|
[archivo] Predeterinado: |
Especificación del archivo de salida:
|
Tabla de valores únicos |
|
[vector: tabla] Preestablecido: |
Especificación de la tabla para valores únicos:
El fichero codificado también puede ser cambiado aquí. |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Identificador de autoridad de SRC |
|
[cadena de texto] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento de píxeles sin datos |
|
[numérico: entero] |
Número de píxeles NoData en la capa ráster de salida |
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Informe de valores únicos |
|
[html] |
El archivo HTML saliente contiene la siguiente información:
|
Tabla de valores únicos |
|
[vector: tabla] |
Una tabla con tres columnas:
|
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Código Python
Algoritmo ID: native:rasterlayeruniquevaluesreport
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.23. Estadísticas zonales de la capa ráster
Calcula estadísticas para los valores de una capa ráster, categorizados por zonas definidas en otra capa ráster.
Ver también
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa Entrante |
|
[ráster] |
Capa ráster de entrada |
Número de banda |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Si el ráster es multibanda elige la banda sobre la que quieras calcular las estadísticas. |
Capa de zonas |
|
[ráster] |
Zonas de definición de capa ráster. Las zonas están dadas por píxeles contiguos que tienen el mismo valor de píxel. |
Número de zonas de banda |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Si el ráster es multibanda, elige la banda que define las zonas |
Estadísticas |
|
[vector: tabla] Predeterminado: |
Especificación del informe de salida. Uno de:
El fichero codificado también puede ser cambiado aquí. |
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de referencia Opcional |
|
[enumeración] Predeterminado: 0 |
Capa ráster utilizada para calcular los centroides que se utilizarán como referencia al determinar las zonas en la capa de salida. Uno de:
|
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Identificador de autoridad de SRC |
|
[cadena de texto] |
El sistema de coordenadas de referencia de la capa ráster saliente |
Extensión |
|
[cadena de texto] |
La extensión espaical de la capa ráster saliente |
Altura en pixels |
|
[numérico: entero] |
El número de filas en la capa ráster de salida |
Recuento de píxeles sin datos |
|
[numérico: entero] |
Número de píxeles NoData en la capa ráster de salida |
Estadísticas |
|
[vector: tabla] |
La capa de salida contiene la siguiente información para cada zona:
|
Recuento total de pixels |
|
[numérico: entero] |
El recuento de pixels en la capa ráster saliente |
Anchura en pixels |
|
[numérico: entero] |
El número de columnas en la capa ráster de salida |
Código Python
Algoritmo ID: native:rasterlayerzonalstats
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.24. Raster minimum/maximum
Extracts the minimum and maximum pixel values from a specified band of a raster layer. If multiple pixels share the same minimum or maximum value, only one of them will be included in the output.
Parámetros
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada |
|
[ráster] |
Raster layer from which to extract the minimum and maximum pixel values. |
Número de banda |
|
[banda ráster] Predeterminado: 1 |
The band of the raster to analyze. If the raster is multiband, specify the band number (starting from 1). |
Extract |
|
[enumeración] Default: 0 (Minimum and Maximum) |
Choose which extrema to extract:
|
Capa de salida |
|
[vector: punto] Predeterminado: |
Especificación de la capa de salida. Una de:
El fichero codificado también puede ser cambiado aquí. |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de salida |
|
[vector: punto] |
Vector layer with point features at the locations of the minimum and/or maximum pixel values. |
Código Python
Algorithm ID: native:rasterminmax
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.25. Raster rank
Added in 3.44
Performs a cell-by-cell analysis in which output values match the rank of a sorted list of overlapping cell values from input layers. The output raster will be multi-band if multiple ranks are provided. If multiband rasters are used in the data raster stack, the algorithm will always perform the analysis on the first band of the rasters.
Figura 24.65 Raster rank result for rank 1 (minimum value). NoData cells in any input raster result in a NoData output cell.
Ver también
Clasificación porcentual de la pila de celdas a partir del valor, percentil de pila de celdas, Porcentaje de la pila de celdas a partir de la capa ráster, Estadísticas de celda, Calculadora ráster
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada |
|
[ráster] [lista] |
Input raster layer(s) to calculate the rank from. |
Rank |
|
[numeric: integer] [list] Default: [1] |
List of ranks to calculate for each pixel in the sorted list of cells values from the input rasters. Cells whose values match the given rank(s) are kept in the output layer. The ranks are 1-based, meaning that the first rank is 1. Negative values are also supported. |
NoData value handling |
|
[enumeración] Predeterminado: 0 |
Choose how to handle NoData values in the input raster:
|
Ranked |
|
[ráster] Predeterinado: |
Specification of the output raster containing the rank values. One of:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Extensión de salida Opcional |
|
[extensión] |
Especifique la extensión espacial de la capa ráster de salida. Si no se especifica la extensión, se utilizará la extensión mínima que cubra todas las capas de referencia seleccionadas. Los métodos disponibles son:
|
Output cell size Opcional |
|
[numérico: doble] |
Tamaño de celda de la capa ráster de salida. Si no se especifica el tamaño de celda, se utilizará el tamaño de celda mínimo de la capa(s) de referencia seleccionada. El tamaño de celda será el mismo para los ejes X e Y. |
SRC saliente Opcional |
|
[src] |
SRC de la capa ráster de salida. Si no se especifica el SRC de salida, se utilizará el SRC de la primera capa de referencia. |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ranked |
|
[ráster] |
Output raster layer containing the result. |
Código Python
Algorithm ID: native:rasterrank
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.26. Volumen de la superficie ráster
Calcula el volumen debajo de una superficie ráster en relación con un nivel base determinado. Esto es principalmente útil para modelos digitales de elevación (MDE).
Parámetros
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de ENTRADA |
|
[ráster] |
Ráster de entrada, representando una superficie |
Número de banda |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Si el ráster es multibanda, elige la banda que debe definir la superficie. |
Nivel Base |
|
[numérico: doble] Predeterminado: 0.0 |
Defina un valor base o de referencia. Esta base se utiliza en el cálculo del volumen de acuerdo con el parámetro |
Methodo |
|
[enumeración] Predeterminado: 0 |
Defina el método para el cálculo del volumen dado por la diferencia entre el valor del píxel de la trama y el
|
Informe de volumen de superficie |
|
[html] Predeterinado: |
Especificación del informe HTML de salida. Uno de:
El fichero codificado también puede ser cambiado aquí. |
Tabla de volumen de superficie |
|
[vector: tabla] Preestablecido: |
Especificación de la tabla de salida. Una de:
El fichero codificado también puede ser cambiado aquí. |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Volumen |
|
[numérico: doble] |
El volumen calculado |
Área |
|
[numérico: doble] |
El área en unidades cuadradas de mapa |
Pixel_count |
|
[numérico: entero] |
El número total de pixels que han sido analizados |
Informe de volumen de superficie |
|
[html] |
El informe de salida (conteniendo volumen, área y recuento de pixel) en formato HTML |
Tabla de volumen de superficie |
|
[vector: tabla] |
La tabla de salida (conteniendo volumen, área y recuento de pixels) |
Código Python
Algoritmo ID: native:rastersurfacevolume
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.27. Reclasificar por capa
Reclasifica una banda ráster asignando nuevos valores de clase basados en los rangos especificados en una tabla de vectores.

Figura 24.66 Reclassified raster by layer (range boundaries: min <= value < max).
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa ráster |
|
[ráster] |
Capa ráster a reclasificar |
Número de banda |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
Si el ráster es multibanda, elige la banda que quieras reclasificar. |
Capa que contiene rupturas de clase |
|
[vectorial: cualquiera] |
Capa vectorial que contiene los valores que se utilizarán para la clasificación. |
Campo de valor mínimo de clase |
|
[campo de tabla: numérico] |
Campo con el valor mínimo del rango para la clase. Utilice |
Campo de valor máximo de clase |
|
[campo de tabla: numérico] |
Campo con el valor máximo del rango para la clase. Utilice |
Campo de valor de salida |
|
[campo de tabla: numérico] |
Campo con el valor que se asignará a los píxeles que caigan en la clase (entre los valores min y max correspondientes). Utilice |
Ráster reclasificado |
|
[ráster] Predeterinado: |
Especificación de raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a aplicar a los valores NoData. |
Límites de rango |
|
[enumeración] Predeterminado: 0 |
Define reglas de comparación para la clasificación. Opciones:
|
Utilizar NoData cuando ningún rango coincide con el valor |
|
[booleano] Predeterminado: False |
Aplica el valor NoData a los valores de banda que no pertenecen a ninguna clase. Si es False, se mantiene el valor original. |
Tipo de datos salientes |
|
[enumeración] Predeterminado: 5 |
Define el formato del fichero raster de salida. Opciones:
Las opciones disponibles dependen de la versión de GDAL compilada con QGIS (vea l menú ) |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster reclasificado |
|
[ráster] |
Capa ráster de salida con valores de banda reclasificados |
Código Python
Algoritmo ID: native:reclassifybylayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.28. Reclasificar por tabla
Reclasifica una banda de ráster asignando nuevos valores de clase basados en los rangos especificados en una tabla fija.

Figura 24.67 Reclassified raster by table (range boundaries: min <= value < max).
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa ráster |
|
[ráster] |
Capa ráster a reclasificar |
Número de banda |
|
[banda ráster] Predeterminado: 1 |
Banda ráster para la cual quieres recalcular valores. |
Tabla de reclasificación |
|
[vector: tabla] |
Una tabla de 3 columnas para rellenar con los valores para establecer los límites de cada clase ( |
Ráster reclasificado |
|
[ráster] Predeterinado: |
Especificación de la capa raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Valor de salida NoData |
|
[numérico: doble] Predeterminado: -9999.0 |
Valor a aplicar a los valores NoData. |
Límites de rango |
|
[enumeración] Predeterminado: 0 |
Define reglas de comparación para la clasificación. Opciones:
|
Utilizar NoData cuando ningún rango coincide con el valor |
|
[booleano] Predeterminado: False |
Aplica el valor NoData a los valores de banda que no pertenecen a ninguna clase. Si es False, se mantiene el valor original. |
Tipo de datos salientes |
|
[enumeración] Predeterminado: 5 |
Define el formato del fichero raster de salida. Opciones:
Las opciones disponibles dependen de la versión de GDAL compilada con QGIS (vea l menú ) |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster reclasificado |
|
[ráster] |
Capa ráster de salida con valores de banda reclasificados |
Código Python
Algoritmo ID: native:reclassifybytable
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.29. Reescalar ráster
Rescales raster layer to a new value range, while preserving the shape (distribution) of the raster’s histogram (pixel values). Input values are mapped using a linear interpolation from the source raster’s minimum and maximum pixel values to the destination minimum and maximum pixel range.
De forma predeterminada, el algoritmo conserva el valor original de NoData, pero existe una opción para anularlo.
Figura 24.68 Cambiar la escala de los valores de una capa ráster de [0 - 50] a [100 - 1000]
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster de Entrada |
|
[ráster] |
Capa ráster que se usará para cambiar la escala |
Número de banda |
|
[banda ráster] Predeterminado: La primera banda de la capa entrante |
Si el ráster es multibanda, elija una banda. |
Nuevo valor mínimo |
|
[numérico: doble] Valor predeterminado: 0.0 |
Valor mínimo de píxel para usar en la capa reescalada |
Nuevo valor máximo |
|
[numérico: doble] Valor predeterminado: 255.0 |
Valor máximo de píxel para usar en la capa reescalada |
Nuevo valor NoData Opcional |
|
[numérico: doble] Predeterminado: No establecido |
Valor a asignar a los píxeles NoData. Si no se establece, se conservan los valores NoData originales. |
Reescalado |
|
[ráster] Predeterinado: |
Especificación de la capa raster de salida. Una de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Reescalado |
|
[ráster] |
Capa ráster de salida con valores de banda reescalados |
Código Python
Algoritmo ID: native:rescaleraster
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.30. Redondear ráster
Redondea los valores de celda de un conjunto de datos ráster según el número especificado de decimales.
Alternativamente, se puede usar un número negativo de lugares decimales para redondear valores a potencias de una base n. Por ejemplo, con un valor base n de 10 y posiciones decimales de -1, el algoritmo redondea los valores de la celda a múltiplos de 10, -2 los redondea a múltiplos de 100, y así sucesivamente. Se pueden elegir valores base arbitrarios, el algoritmo aplica el mismo principio multiplicativo. El redondeo de los valores de la celda a múltiplos de una base n se puede usar para generalizar las capas ráster.
El algoritmo conserva el tipo de datos del ráster de entrada. Por lo tanto, los rásteres de tipo byte/entero solo se pueden redondear a múltiplos de una base n; de lo contrario, se genera un aviso y el ráster se copia como ráster de tipo byte/entero.
Figura 24.69 Redondeo de valores de un ráster
Parámetros
Parámetros básicos
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster de Entrada |
|
[ráster] |
El ráster para procesar. |
Número de banda |
|
[banda ráster] Predeterminado: 1 |
La banda del ráster |
Dirección del redondeo |
|
[lista] Predeterminado: 1 |
Cómo elegir el valor objetivo redondeado. Las opciones son:
|
Número de posiciones decimales |
|
[numérico: entero] Preestablecido: 2 |
Número de decimales a redondear. Use valores negativos para redondear los valores de la celda a un múltiplo de una base n |
Ráster de salida |
|
[ráster] Predeterinado: |
Especificación del archivo de salida. Uno de:
|
Parámetros avanzados
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Base n para redondear a múltiples de n |
|
[numérico: entero] Predeterminado: 10 |
Cuando el parámetro |
Opciones de creación Opcional
|
|
[cadena de texto] Predeterminado: “” |
Para agregar una o más opciones de creación que controlen el ráster a crear (colores, tamaño de bloque, compresión de archivos …). Para mayor comodidad, puede confiar en perfiles predefinidos (consultar GDAL driver options section). Proceso por lotes y Diseñador de modelos: separe varias opciones con un carácter de tubo ( |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Ráster de salida |
|
[ráster] |
La capa ráster de salida con valores redondeados para la banda seleccionada. |
Código Python
Algoritmo ID: native:roundrastervalues
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.31. Valores de muestra ráster
Extrae valores ráster en las ubicaciones de los puntos. Si la capa ráster es multibanda, se muestrea cada banda.
La tabla de atributos de la capa resultante tendrá tantas columnas nuevas como el recuento de bandas de la capa ráster.
Parámetros
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa Entrante |
|
[vector: punto] |
Capa vectorial de puntos que se utilizará para el muestreo |
Capa ráster |
|
[ráster] |
Capa ráster a muestrear en las ubicaciones de los puntos dados. |
Prefijo de columna saliente |
|
[cadena de texto] Predeterminado: “SAMPLE_” |
Prefijo para los nombres de las columnas agregadas. |
Muestreada Opcional |
|
[vector: punto] Predeterminado: |
Especifique la capa de salida que contiene los valores muestreados. Una de:
El fichero codificado también puede ser cambiado aquí. |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Muestreada |
|
[vector: punto] |
La capa de salida que contiene los valores muestreados. |
Código Python
Algoritmo ID: native:rastersampling
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.32. Histograma zonal
Agrega campos que representan recuentos de cada valor único de una capa ráster contenida en entidades poligonales.
La tabla de atributos de la capa de salida tendrá tantos campos como los valores únicos de la capa ráster que intersecta el polígono(s).
Figura 24.70 Ejemplo de histograma de capa ráster
Parámetros
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa ráster |
|
[ráster] |
Capa ráster de entrada. |
Número de banda |
|
[banda ráster] Predeterminado: La primera banda de la capa entrante |
Si el ráster es multibanda, elija una banda. |
Capa de vector que contiene zonas |
|
[vectorial: poligonal] |
Capa de polígono vectorial que define las zonas. |
Prefijo de columna saliente |
Opcional |
[cadena de texto] Predeterminado: “HISTO_” |
Prefijo para los nombres de las columnas de salida. |
Zonas salientes |
|
[vectorial: poligonal] Predeterminado: |
Especifique la capa de polígonos del vector de salida. Una de:
El fichero codificado también puede ser cambiado aquí. |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Zonas salientes |
|
[vectorial: poligonal] |
La capa de polígono de vector de salida. |
Código Python
Algoritmo ID: native:zonalhistogram
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.33. Zonal Minimum/Maximum Point
Added in 3.42
Extracts point features corresponding to the minimum and maximum pixel values within polygon zones.
The output will contain one point feature for the minimum and one for the maximum raster value for every individual zonal feature from a polygon layer. The created point layer will be in the same spatial reference system as the selected raster layer.
Advertencia
Este algoritmo elimina las claves primarias o los valores FID existentes y los regenera en las capas de salida.
Parámetros
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa Entrante |
|
[vectorial: poligonal] |
Polygon layer defining the zones. |
Capa ráster |
|
[ráster] |
Raster layer to extract the minimum and maximum values from. |
Raster Band |
|
[banda ráster] Predeterminado: La primera banda de la capa ráster |
If the raster has multiple bands, select the band to process. |
Zonal extrema |
|
[vector: punto] Predeterminado: |
Especificación de la capa de salida. Una de:
El fichero codificado también puede ser cambiado aquí. |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Zonal extrema |
|
[vector: punto] |
Output layer containing the minimum and maximum points for each zone. |
Código Python
Algorithm ID: native:zonalminmaxpoint
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.
24.1.18.34. Estadísticas de zona
Calcula las estadísticas de una capa ráster para cada entidad de una capa vectorial de polígono superpuesta.
Parámetros
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Capa de entrada |
|
[vectorial: poligonal] |
Capa vectorial poligonal que contiene las zonas. |
Capa ráster |
|
[ráster] |
Capa ráster de entrada. |
Banda ráster |
|
[banda ráster] Predeterminado: La primera banda de la capa entrante |
Si el ráster es multibanda, elija una banda para las estadísticas. |
Prefijo de columna saliente |
|
[cadena de texto] Predeterminado: “_” |
Prefijo para los nombres de las columnas de salida. |
Estadísticas a calcular |
|
[enumeración] [lista] Predeterminado: [0,1,2] |
Lista de operador estadístico para la salida. Opciones:
|
Estadísticas de zona |
|
[vectorial: poligonal] Predeterminado: |
Especifique la capa de polígonos del vector de salida. Una de:
El fichero codificado también puede ser cambiado aquí. |
Salidas
Label |
Nombre |
Tipo |
Descripción |
|---|---|---|---|
Estadísticas de zona |
|
[vectorial: poligonal] |
La capa vectorial zonal con estadísticas añadidas. |
Código Python
Algoritmo ID: native:zonalstatisticsfb
import processing
processing.run("algorithm_id", {parameter_dictionary})
El algoritmo id se muestra al desplazarse sobre el algoritmo en la Caja de Herramientas de Procesamiento. El parámetro diccionario suministra los NOMBREs y valores de los parámetros. Ver consola_procesamiento para detalles sobre como ejecutar algoritmos desde la consola Python.