Importante
La traducción es un esfuerzo comunitario puede unirse. Esta página está actualmente traducida en |progreso de traducción|.
17.14. Primer ejemplo de análisis
Nota
En esta lección vamos a realizar un análisis real utilizando sólo la caja de herramientas, para que pueda tener más familiaridad con los elementos del área de trabajo de procesamiento.
Now that everything is configured and we can use external algorithms, we have a very powerful tool to perform spatial analysis. It is time to work out a larger exercise with some real world data.
Usaremos el conocido conjunto de datos que John Snow usó en 1854, en su innovador trabajo (https://en.wikipedia.org/wiki/John_Snow_%28physician%29), , y obtendremos algunos resultados interesantes. El análisis de este conjunto de datos es bastante obvio y no hay necesidad de sofisticadas técnicas de SIG para obtener buenos resultados y conclusiones, pero es una buena manera de mostrar cómo estos problemas espaciales pueden ser analizados y resueltos mediante el uso de diferentes herramientas de procesamiento.
El conjunto de datos contiene archivos shape con muertes por cólera y ubicaciones de bombas, y un mapa rendido OSM en formato TIFF. Abra el proyecto de QGIS correspondiente para esta lección.
The first thing to do is to calculate the Voronoi diagram (a.k.a. Thiessen polygons) of the pumps layer, to get the influence zone of each pump. The Voronoi polygons algorithm can be used for that.
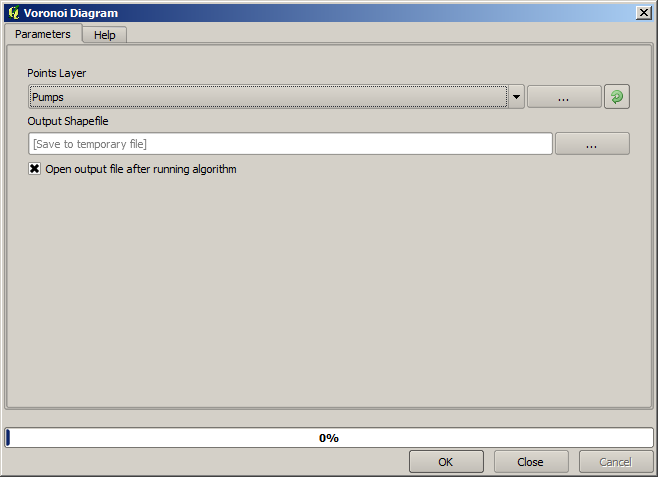
Bastante fácil, pero ya nos dará información interesante.
Claramente, muchos de los casos se encuentran dentro de uno de los polígonos
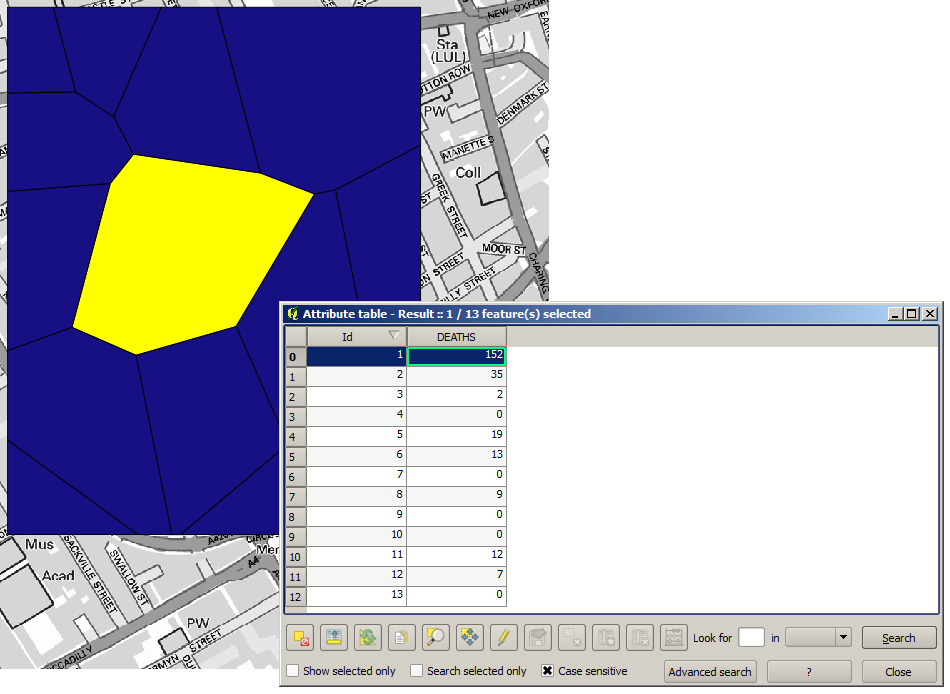
To get a more quantitative result, we can count the number of deaths in each polygon. Since each point represents a building where deaths occurred, and the number of deaths is stored in an attribute, we cannot just count the points. We need a weighted count, so we will use the Count points in polygon tool.
The new field will be called DEATHS, and we use the COUNT field as weighting field.
The resulting table clearly reflects that the number of deaths in the polygon
corresponding to the first pump is much larger than the other ones.
Another good way of visualizing the dependence of each point in the Cholera_deaths layer
with a point in the Pumps layer is to draw a line to the closest one.
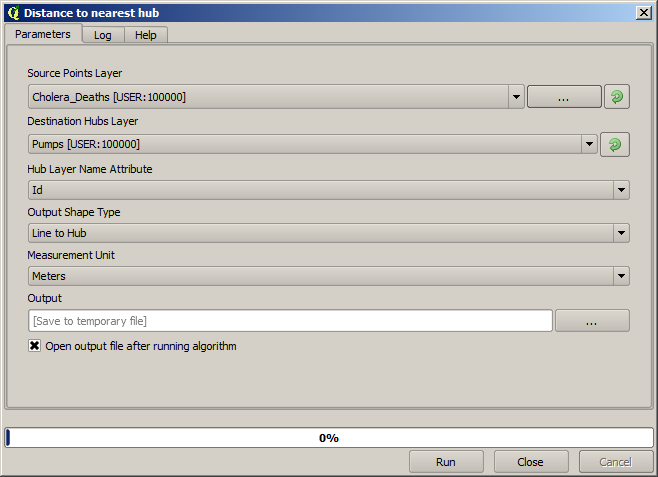
This can be done with the Distance to nearest hub tool, and using the configuration shown next.
El resultado se parece a esto:
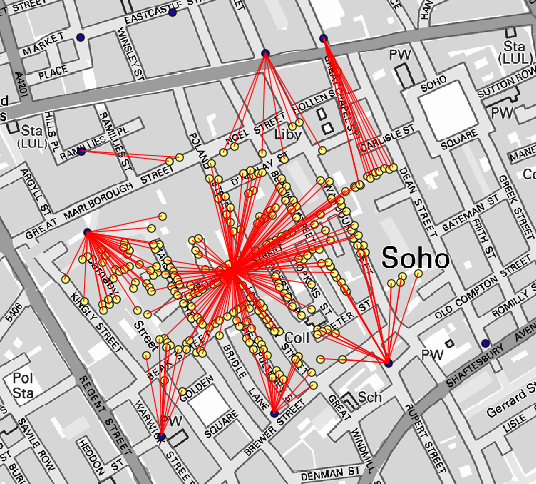
Aunque el número de líneas es mayor en el caso de la bomba central, no se olvide de que esto no representa el número de muertes, pero el número de lugares donde se encontraron casos de cólera. Es un parámetro representativo, pero no está considerando que algunos lugares podrían tener más casos que otros.
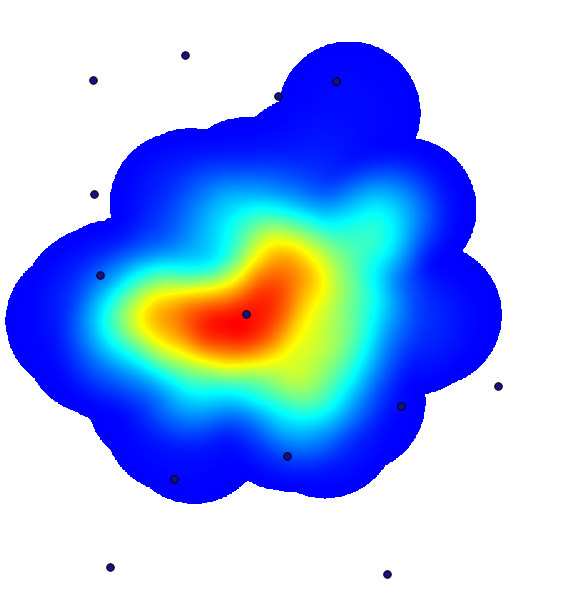
A density layer will also give us a very clear view of what is happening.
We can create it with the Heatmap (Kernel density estimation) algorithm.
Using the Cholera_deaths layer, its COUNT field as weight field, with a radius of 100,
the extent and cell size of the streets raster layer, we get something like this.
Remember that, to get the output extent, you do not have to type it. Click on the button on the right-hand side and select Use layer/canvas extent.
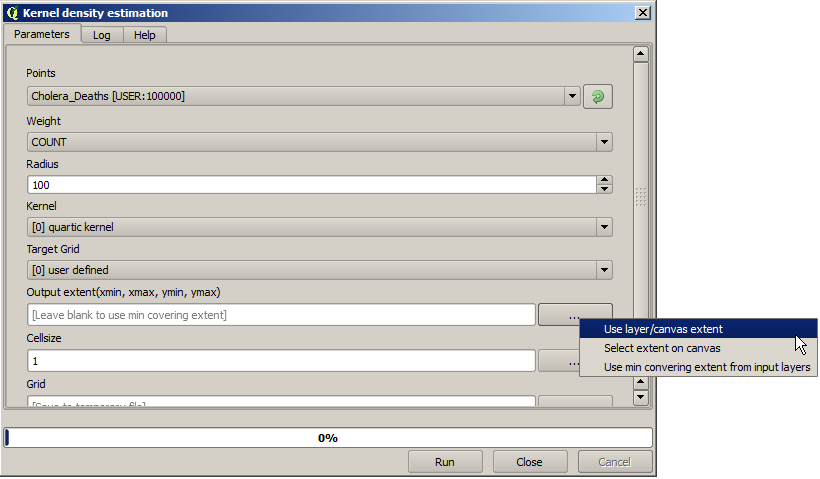
Seleccione la capa de calles ráster y su extensión automáticamente se añadirá al campo de texto. Debe hacer lo mismo con el tamaño de celda, seleccionando el tamaño de celda de esa capa también.
La combinación con la capa de bombas, vemos que hay una bomba claramente en el punto de acceso donde se encuentra la máxima densidad de los casos de muerte.