Importante
unireLa traduzione è uno sforzo comunitario you can join. Questa pagina è attualmente tradotta al 97.73%.
15.1. Lezione: Introduzione ai Database
Prima di usare PostgreSQL, assicuriamoci di conoscere la teoria generale dei database. Non avrai bisogno di inserire codice; è solo a scopo illustrativo.
Obiettivo di questa lezione: Comprendere i concetti fondamentali dei database.
15.1.1. Cos’è un database?
Un database consiste in una raccolta organizzata di dati per uno o più usi. - Wikipedia
Un sistema di gestione del database (DBMS) è costituito da un software che gestisce i database, fornendo spazio di archiviazione, accesso, sicurezza, backup e altri servizi. - Wikipedia
15.1.2. Tabelle
Nei database relazionali e nei database di file flat, una tabella è un insieme di elementi di dati (valori) organizzati utilizzando un modello di colonne verticali (identificate dal loro nome) e righe orizzontali. Una tabella ha un numero specificato di colonne, ma può avere un numero qualsiasi di righe. Ogni riga è identificata dai valori che appaiono in un particolare sottoinsieme di colonne che è stato identificato come una chiave univoca. - Wikipedia
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
Nei database SQL una tabella è anche nota come relazione.
15.1.3. Colonne / Campi
Una colonna è un insieme di valori di dati di un particolare tipo, uno per ogni riga della tabella. Le colonne forniscono la struttura in base alla quale sono composte le righe. Il termine campo viene spesso utilizzato in modo intercambiabile con colonna, anche se molti ritengono più corretto utilizzare campo (o valore del campo) per fare riferimento in modo specifico al singolo elemento esistente all’intersezione tra una riga e una colonna. - Wikipedia
Una colonna:
| name |
+-------+
| Tim |
| Horst |
Un campo:
| Horst |
15.1.4. Record
Un record è l’informazione memorizzata in una riga della tabella. Ogni record avrà un campo per ciascuna delle colonne nella tabella.
2 | Horst | 88 <-- one record
15.1.5. Tipi di dati
Il tipo di dato limita il tipo di informazioni che possono essere archiviate in una colonna. - Tim e Horst
Ci sono diversi tipi di dato. Concentriamoci sui più comuni:
String- per memorizzare dati di testoInteger- per memorizzare numeri interiReal- per memorizzare i numeri decimaliData- per memorizzare il compleanno di Horst, in modo che nessuno lo dimentichi.Boolean- per memorizzare valori di vero/falso
Puoi dire al database di permetterti di non memorizzare nulla in un campo. Se non c’è nulla in un campo, allora il contenuto del campo viene definito come un valore null”:
insert into person (age) values (40);
select * from person;
Risultato:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
Ci sono molti altri tipi di dati che puoi usare - controlla il manuale di PostgreSQL https://www.postgresql.org/docs/current/datatype.html
15.1.6. Creazione di un database di indirizzi
Usiamo un semplice caso di studio per vedere come viene costruito un database. Vogliamo creare un database di indirizzi.
Prova Tu: ★☆☆
Scriviamo le proprietà che costituiscono un indirizzo semplice e che vorremo memorizzare nel nostro database.
Soluzione
Per la nostra teorica tabella degli indirizzi, potremmo voler memorizzare le seguenti proprietà:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
Quando creiamo la tabella per rappresentare un oggetto indirizzo, creiamo colonne per rappresentare ciascuna di queste proprietà e le nominiamo con nomi conformi a SQL e possibilmente abbreviati:
house_number
street_name
suburb
city
postcode
country
Struttura indirizzi
Le proprietà di ogni indirizzo sono espresse nelle colonne. Il tipo di informazioni memorizzate in ogni colonna è il suo tipo di dati. Nella prossima sezione analizzerai la nostra tabella degli indirizzi concettuali per vedere come migliorarla!
15.1.7. Teoria dei database
Il processo di creazione di un database implica la creazione di un modello del mondo reale; prendendo i concetti del mondo reale e rappresentandoli nel database come entità.
15.1.8. Normalizzazione
Una delle idee principali in un database è quella di evitare la duplicazione/ridondanza dei dati. Il processo di rimozione della ridondanza da un database è chiamato Normalizzazione.
La normalizzazione è un modo sistematico per garantire che una struttura di database sia adatta per l’interrogazione e priva di determinati e indesiderabili caratteristiche - inserimento, aggiornamento e anomalia di cancellazione - che potrebbero portare a una perdita dell’integrità dei dati. - Wikipedia
Ci sono diversi tipi di «forme» di normalizzazione.
Guarda un semplice esempio:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Immagina di avere molti amici con lo stesso nome di via o città. Ogni volta che questi dati vengono duplicati, viene consumato spazio. Peggio ancora, se il nome di una città cambia, devi fare un sacco di lavoro per aggiornare il tuo database.
15.1.9. Prova Tu: ★☆☆
Riprogetta la tabella teorica people di cui sopra per ridurre la duplicazione e normalizzare la struttura dei dati.
Puoi leggere di più sulla normalizzazione del database qui https://en.wikipedia.org/wiki/Database_normalization
Soluzione
Il problema principale della tabella people è che c’è un solo campo indirizzo che contiene l’intero indirizzo di una persona. Pensando alla nostra teorica tabella address di prima in questa lezione, sappiamo che un indirizzo è composto da molte proprietà diverse. Memorizzando tutte queste proprietà in un solo campo, rendiamo molto più difficile aggiornare e interrogare i nostri dati. Abbiamo quindi bisogno di dividere il campo indirizzo nelle varie proprietà. Questo ci darebbe una tabella che ha la seguente struttura:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
Nella prossima sezione, imparerai le relazioni Chiavi Esterne che potrebbero essere usate in questo esempio per migliorare ulteriormente la struttura del nostro database.
15.1.10. Indici
Un indice di database è una struttura di dati che migliora la velocità delle operazioni di recupero dei dati su una tabella di database. - Wikipedia
Immagina di leggere un libro e di cercare la spiegazione di un concetto - e il libro non ha un indice! Dovrai iniziare a leggere dalla prima pagina e poi proseguire per tutto il libro fino a trovare l’informazione di cui hai bisogno. L’indice sul retro di un libro ti aiuta a saltare rapidamente alla pagina con le informazioni pertinenti:
create index person_name_idx on people (name);
Ora le ricerche sul nome saranno più veloci:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. Sequenze
Una sequenza è un generatore di numeri univoco. Viene normalmente utilizzato per creare un identificativo univoco per una colonna in una tabella.
In questo esempio, id è una sequenza: il numero viene incrementato ogni volta che un record viene aggiunto alla tabella:
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. Diagramma Entità Relazione
In un database normalizzato, si hanno tipicamente molte relazioni (tabelle). Il diagramma entità-relazione (ER Diagram) è usato per disegnare le dipendenze logiche tra le relazioni. Considera la nostra tabella non normalizzata people nella lezione precedente:
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Con poco lavoro possiamo dividerlo in due tabelle, eliminando la necessità di ripetere il nome della via per le persone che vivono nella stessa strada:
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
e:
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
Possiamo quindi collegare le due tabelle usando le “chiavi” streets.id e people.streets_id.
Se disegnassimo un diagramma ER per questi due tabelle, sarebbe simile a questo:

Il diagramma ER ci aiuta ad esprimere relazioni “da uno a molti”. In questo caso il simbolo della freccia indica che una strada può avere molte persone che vivono su di essa.
Prova Tu: ★★☆
Il nostro modello “people” ha ancora alcuni problemi di normalizzazione: prova a vedere se puoi normalizzarlo ulteriormente e mostrarlo per mezzo di un diagramma ER.
Soluzione
La nostra tabella people attualmente assomiglia a questa:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
La colonna street_id rappresenta una relazione “uno a molti” tra l’oggetto people e il relativo oggetto street, che si trova nella tabella streets.
Un modo per normalizzare ulteriormente la tabella è quello di sudividere il campo nome in nome e cognome:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
Possiamo anche creare tabelle separate per il nome della città e del paese, collegandole alla nostra tabella people tramite relazioni “uno a molti”:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
Un diagramma ER per rappresentare questo sarebbe il seguente:
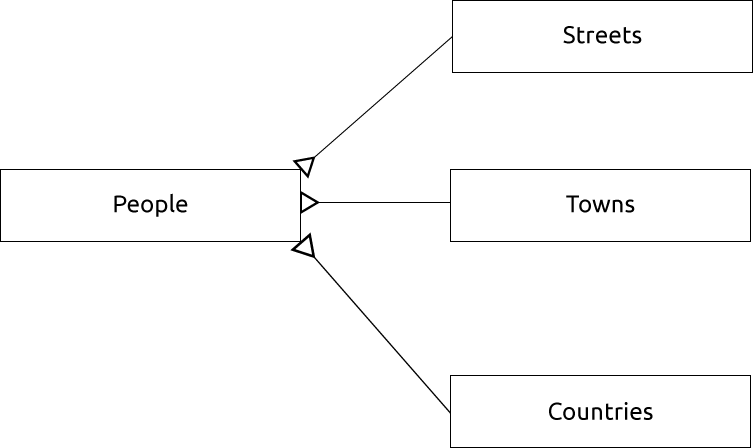
15.1.13. Vincoli, chiavi primarie e chiavi esterne
Un vincolo di database è utile per assicurare che i dati in una relazione corrispondano a come tali dati devono essere memorizzati. Ad esempio un vincolo sul tuo codice postale potrebbe garantire che il numero sia tra 1000 e 9999.
Una chiave Primaria è uno o più valori di campo che rendono un record univoco. Di solito la chiave primaria è chiamata id ed è una sequenza.
Una chiave Esterna viene utilizzata per fare riferimento a un record univoco su un’altra tabella (utilizzando la chiave primaria di quell’altra tabella).
Nel diagramma ER, il collegamento tra tabelle è normalmente basato su chiavi Esterne che si collegano a chiavi Primarie.
Se guardiamo all’esempio people, la definizione della tabella mostra che la colonna street è una chiave esterna che fa riferimento alla chiave primaria nella tabella streets:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. Transazioni
Quando aggiungi, modifichi o elimini dati in un database, è sempre importante che il database sia lasciato in buono stato. La maggior parte dei database fornisce una funzionalità chiamata supporto per le transazioni. Le transazioni consentono di creare una posizione di rollback a cui è possibile tornare se le modifiche al database non sono state eseguite come pianificato.
Considera uno scenario in cui hai un sistema di contabilità. Devi trasferire fondi da un account e aggiungerli a un altro. La sequenza di passaggi sarebbe come questa:
remove R20 from Joe
add R20 to Anne
Se qualcosa andasse storto durante il processo (ad esempio un’interruzione dell’alimentazione), la transazione verrà ripristinata.
15.1.15. In Conclusione
I database ti consentono di gestire i dati in modo strutturato utilizzando semplici strutture di codice.
15.1.16. Cosa Segue?
Ora che abbiamo visto come i database funzionano in teoria, creiamo un nuovo database per implementare la teoria trattata.