Wichtig
Übersetzen ist eine Gemeinschaftsleistung Sie können mitmachen. Diese Seite ist aktuell zu 85.23% übersetzt.
15.1. Lesson: Introduction to Databases
Bevor wir PostgreSQL verwenden, gehen wir einige Grundlagen der allgemeinen Datenbanktheorie durch. Sie müssen die hier verwendeten Beispielcodes nicht abtippen. Sie dienen nur zur Illustration.
Ziel dieser Übung: Verständnis der grundlegenden Datenbankkonzepte.
15.1.1. Was ist eine Datenbank?
Eine Datenbank besteht aus einer organisierten Sammlung von Daten für einen bestimmten oder mehrere Zwecke in der Regel in digitaler Form. - Wikipedia
Ein Datenbankmanagementsystem (DBMS) ist ein Programm, das Datenbanken verwaltet, für die Speicherung von Daten, den Zugriff auf Daten, die Sicherheit, Rettungskopien und weitere Dinge sorgt. - Wikipedia
15.1.2. Tabellen
In relationalen Datenbanken und Flat-File-Datenbanken versteht man unter einer Tabelle eine Menge von Datenelementen (Werte), die in vertikalen Spalten (die durch einen Spaltennamen identifiziert sind) und horizontalen Zeilen organisiert sind. Eine Tabelle hat eine bestimmte Anzahl an Spalten und eine unbegrenzte Anzahl an Zeilen. Jede Zeile wird durch die Werte einer Teilmenge der Spalten, die als Schlüsselkandidat gekennzeichnet sind, identifiziert. -Wikipedia
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
In SQL-Datenbanken wird eine Tabelle auch als Relation bezeichnet.
15.1.3. Spalten / Felder
Eine Spalte ist eine Menge von Datenwerten eines besonders einfachen Typs, ein Wert für jede Zeile der Tabelle. Die Spalten geben die Struktur vor, in der die Zeilen angeordnet sind. Die Bezeichnung Feld wird oftmals abwechselnd mit der Bezeichnung Spalte verwendet. In der Mehrheit wird es jedoch als korrekter angesehen, den Wert der sich an der Überschneidung einer Zeile mit einer Spalte befindet, als Feld (oder Feldwert) zu bezeichnen. -Wikipedia
Eine Spalte:
| name |
+-------+
| Tim |
| Horst |
Ein Feld:
| Horst |
15.1.4. Datensätze
Ein Datensatz ist die in einer Tabellenzeile gespeicherte Information. Jeder Datensatz enthält für jede Spalte der Tabelle ein Feld.
2 | Horst | 88 <-- one record
15.1.5. Datentypen
Datentypen schränken die Art der Information ein, die in einer Spalte gespeichert werden kann. - Tim und Horst
Es viele verschiedene Datentypen. Hier sind die am weitesten verbreiteten:
String- zur Speicherung von freiem TextInteger- um ganzzahlige Zahlen zu speichernReal- zur Speicherung reeller ZahlenDate- um den Geburtstag von Horst zu speichern, so dass niemand ihn vergisstBoolean- um einfache wahr/falsch Werte zu speichern
Man kann der Datenbank auch erlauben gar nichts in einem Feld zu speichern. Wenn ein Feld keinen Wert enthält, wird der Inhalt des Feldes als Null Wert bezeichnet:
insert into person (age) values (40);
select * from person;
Ergebnis:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
Es gibt noch viele weitere Datentypen, die man nutzen kann - check the PostgreSQL manual!
15.1.6. Modellierung einer Adressendatenbank
Wir werden ein einfaches Fallbeispiel betrachten, um zu sehen wie eine Datenbank konsturiert ist. Wir werden eine Adressendatenbank erstellen.
Try Yourself: ★☆☆
Schreiben Sie die Eigenschaften einer einfachen Adresse auf, die wir in der Datenbank speichern wollen.
Antwort
For our theoretical address table, we might want to store the following properties:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
When creating the table to represent an address object, we would create columns to represent each of these properties and we would name them with SQL-compliant and possibly shortened names:
house_number
street_name
suburb
city
postcode
country
Struktur einer Adresse
Die Bestandteile, die zu einer Adresse gehören entsprechen den Spalten. Die Art der Information, die in jeder Spalte gespeichert ist, ist der Datentyp. Im nächsten Abschnitt werden wir unseren Entwurf der Adressentabelle analysieren und verbessern.
15.1.7. Datenbanktheorie
Der Prozess der Erstellung einer Datenbank beinhaltet die Erstellung eines Modells der Wirklichkeit; man repräsentiert Konzepte aus der Wirklichkeit durch Objekte in der Datenbank.
15.1.8. Normalisierung
Eine der grundsätzlichen Ideen einer Datenbank besteht in der Vermeidung von doppelten Daten / Redundanz. Der Prozess des Entfernens von Redundanz aus einer Datenbank wird Normalisierung genannt.
Normalisierung ist ein systematischer Weg, um sicher zu stellen, dass die Datenbankstruktur für allgemeine Abfragen passend und frei von bestimmten ungewollten Eigenschaften - Unregelmäßigkeiten beim einfügen, aktualisieren und löschen von Daten - die zum Verlust der Datenintegrität führen können. - Wikipedia
Es gibt verschiedene Arten der Normalisierung.
Schauen wir uns ein einfaches Beispiel an:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Stellen Sie sich vor, Sie haben viele Freunde die in einer Straße mit demselben Namen oder derselben Stadt leben. Bei jeder Duplizierung der Daten wird Speicherplatz verbraucht. Noch schlimmer ist, dass wenn sich der Name einer Stadt ändert, viele Einträge in der Datenbank korrigiert werden müssen.
15.1.9. Try Yourself: ★☆☆
Verändern sie die obige people Tabelle, um Dopplungen zu verringern und die Datenstruktur zu normalisieren.
Unter dem folgendem Link erfährt man mehr über die Datenbanknormalisierung: here
Antwort
The major problem with the people table is that there is a single address field which contains a person’s entire address. Thinking about our theoretical address table earlier in this lesson, we know that an address is made up of many different properties. By storing all these properties in one field, we make it much harder to update and query our data. We therefore need to split the address field into the various properties. This would give us a table which has the following structure:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
In the next section, you will learn about Foreign Key relationships which could be used in this example to further improve our database’s structure.
15.1.10. Indexe
Ein Datenbankindex ist eine Datenstruktur, die die Geschwindigkeit von Abfrageoperationen auf einer Datenbanktabelle erhöht. - Wikipedia
Stellen Sie sich vor, Sie lesen ein Fachbuch und suchen nach der Erklärung eines Begriffes, aber das Buch hat keinen Index! Sie müssten beginnend mit dem ersten Kapitel das ganze Buch durcharbeiten, bis Sie die gesuchte Information finden. Der Index im Buch hilft, schnell zu der Seite im Buch mit der relevanten Information zu springen:
create index person_name_idx on people (name);
Jetzt ist die Suche nach Namen schneller:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. Sequenzen
Eine Sequenz ist eine Folge eindeutiger Zahlen. Sie wird normalerweise als eindeutiger Identifikator in einer Spalte einer Tabelle verwendet.
In diesem Beispiel ist id eine Sequenz - die Zahl wird mit jeder Aufnahme eines neuen Datensatzes in die Tabelle erhöht:
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. Entity Relationship Diagramme
In einer normalisierten Datenbank hat man normalerweise viele Relationen (Tabellen). Das Entity-Relationship-Diagramm (ER-Diagramm) wird verwendet, um die logischen Beziehungen zwischen den Relationen zu entwerfen. Denken Sie an unsere nicht normalisierte Tabelle people am Anfang der Lektion:
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Mit etwas Arbeit können wir sie in zwei Tabellen teilen. Der Straßenname von Personen die in derselben Straße wohnen, muss dadurch nicht wiederholt werden:
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
und:
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
Wir können nun die beiden Tabellen mit Hilfe der ‚Schlüssel‘ streets.id und people.streets_id verbinden.
Wenn wir ein ER-Diagramm für diese beiden Tabellen entwerfen, sieht es in etwa so aus:

Das ER-Diagramm hilft uns ‚eins zu viele‘ Beziehungen auszudrücken. In diesem Fall zeigt das Pfeilsymbol, dass in einer Straße viele Personen leben können.
Try Yourself: ★★☆
Unser Modell people hat immer noch einige Probleme bezüglich der Normalisierung - versuchen Sie es weiter mit Hilfe eines ER-Diagramms zu normalisieren.
Antwort
Our people table currently looks like this:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
The street_id column represents a ‚one to many‘ relationship between the people object and the related street object, which is in the streets table.
One way to further normalise the table is to split the name field into first_name and last_name:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
We can also create separate tables for the town or city name and country, linking them to our people table via ‚one to many‘ relationships:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
An ER Diagram to represent this would look like this:
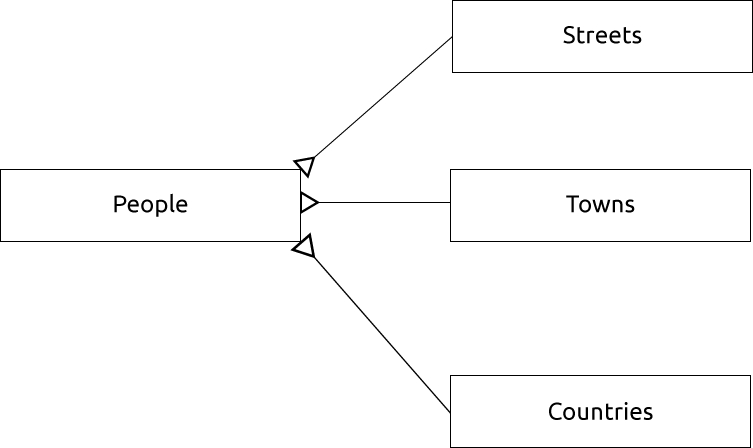
15.1.13. Einschränkungen, Primärschlüssel und Fremdschlüssel
Eine Datenbankeinschränkung wird verwendet, um sicherzustellen, dass die Daten in einer Relation so gespeichert werden, wie es der Modellierer vorgesehen hat. Zum Beispiel kann eine Einschränkung der Postleitzahl darin bestehen, dass die Zahl zwischen 1000 und 9999 liegt.
Ein Primärschlüssel besteht aus einem oder mehreren Feldwerten, die einen Datensatz eindeutig machen. Oftmals wird der Primärschlüssel id genannt und ist eindeutige Zahlenfolge.
Ein Fremdschlüssel ist eine Referenz zu einem eindeutigen Datensatz in einer anderen Tabelle (Nutzung des Primärschlüssels dieser Tabelle).
In ER-Diagrammen basiert die Verbindung zwischen Tabellen normalerweise auf Fremschlüsseln die auf Primärschlüssel verweisen.
In unserem Beispiel, zeigt die Definition der Tabelle, dass die Spalte Straße ein Fremdschlüssel ist. Er verweist auf den Primärschlüssel in der Tabelle Straßen:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. Transaktionen
Wenn beim hinzufügen, ändern oder löschen von Daten in einer Datenbank etwas schief geht, sollte die Datenbank immer in einem konsisten Zustand bleiben. Die meisten Datenbanken enthalten eine sogenannte Transaktionsunterstützung. Transaktionen erlauben es einen Rollback zu erstellen, d.h. einen Zustand vor Ausführung der Transaktion in den bei Problemen zurück gekehrt werden kann.
Ein Beispiel wäre ein Abrechnungssystem in dem man Mittel von einem Konto auf ein anderes Konto transferieren möchte. Es ergibt sich folgende Schrittfolge:
entferne R20 von Joe
Füge R20 bei Anne hinzu
Wenn etwas während des Prozesses schief geht (z.B. Stromausfall), wird ein Rollback der Transaktion ausgeführt.
15.1.15. Zusammengefasst
Datenbanken erlauben es, Daten in einer strukturierten Weise mit Hilfe von einfachem Programierkode zu managen.
15.1.16. Was als nächstes?
Nachdem wir gesehen haben, wie Datenbanken in der Theorie arbeiten, wollen wir nun eine neue Datenbank erstellen und die behandelte Theorie umsetzen.