17.23. Noch mehr Interpolation
Bemerkung
Dieses Kapitel behandelt ein weiteres praktisches Beispiel zur Nutzung von Algorithmen zur Interpolation.
Interpolation ist eine verbreitete Methode. Sie kann auch zur Demonstration verschiedener Techniken in Zusammenhang mit der QGIS Verarbeitungsumgebung verwendet werden. Diese Lektion zeigt einige schon bekannte Algorithmen zur Interpolation, verfolgt aber ein andere Herangehensweise.
Die Daten für diese Lektion enthalten auch Punktdaten, in diesem Fall Höhenwerte. Wir werden die Daten in ähnlicher Weise wie in der vorherigen Lektion interpolieren. Dieses Mal werden wir Teile der Ausgangsdaten speichern und zur Bewertung des Interpolationsprozesses verwenden.
Als Erstes müssen wir den Punktlayer rastern und die sich ergebenen Leerwerte füllen. Wir verwenden dazu aber nicht alle Punkte des Layers. Wir werden 10% der Punkte für die spätere Bewertung verwenden, d.h. wir nutzen nur 90% der Punkte für die Interpolation. Um das zu erreichen, könnten wir den Algorithmus Split shapes layer randomly verwenden, den wir aus einer vorherigen Lektion kennen. Aber es gibt noch einen besseren Weg, bei dem wir keinen temporären Layer erstellen müssen. Wir können vor der Ausführung des Algorithmus die gewünschten Punkte selektieren (90% der Punkte). Bei der Rasterung werden dann nur diese Punkte berücksichtigt. Die restlichen Punkte werden ignoriert. Die Selektion kann mit Hilfe des Algorithmus Zufällige Auswahl erfolgen. Starten Sie ihn mit den folgenden Parametern.
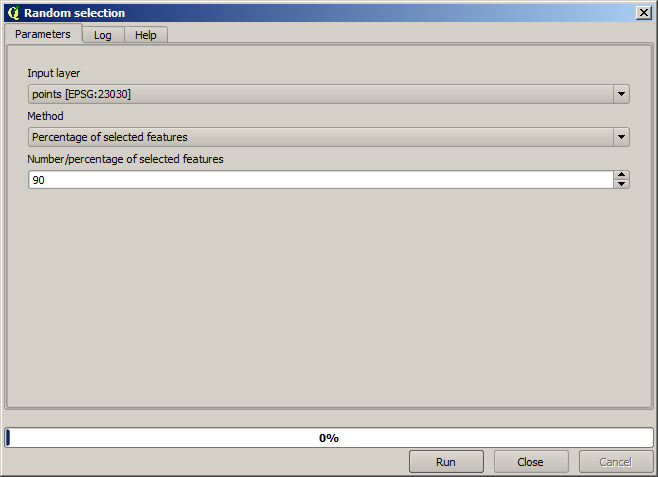
Damit werden 90% der Punkte des Layer für die Rasterung ausgewählt

Die Auswahl ist zufällig, so dass Ihre Auswahl vermutlich von der hier gezeigten Auswahl abweicht.
Starten Sie nun den Algorithmus Rastern, um den ersten Rasterlayer zu erhalten. Füllen Sie anschließend die Leerwerte mit Hilfe des Algorithmus Close gaps [Cell resolution: 100 m].

Um die Qualität der Interpolation zu überprüfen, verwenden wir nun die nicht selektierten Punkte. An diesen Punkten kennen wir die tatsächliche Geländehöhe (der Wert im Punktlayer) und die interpolierte Geländehöhe (der Wert im interpolierten Rasterlayer). Wir können die beiden durch Berechnung der Differenz der Werte vergleichen.
Da wir die nicht selektierten Punkte nutzen möchten, müssen wir als Erstes die Selektion umkehren.

Die Punkte enthalten die Ausgangswerte aber nicht die interpolierten. Um sie in einem neuen Feld hinzuzufügen, können wir den Algorithmus Add Raster values to points verwenden.
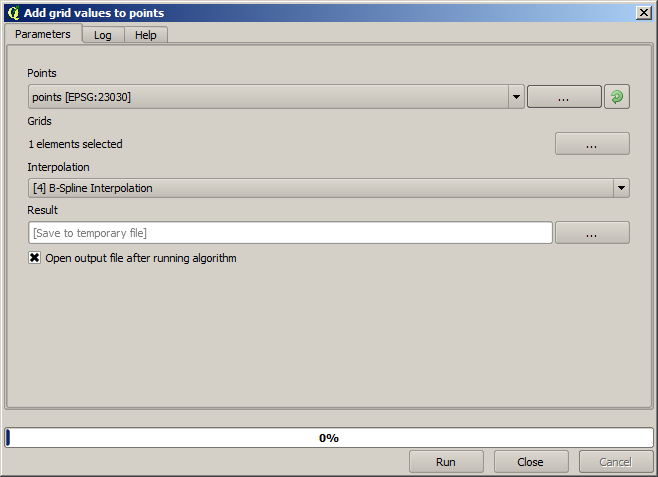
Der zu wählende Rasterlayer (der Algorithmus unterstützt mehrere Raster, wir benötigen nur eins) ist das Ergebnis der Interpolation. Wir haben den Layer in interpolate umbenannt. Dieser Layernamen wird auch als Name für das hinzugefügte Feld verwendet.
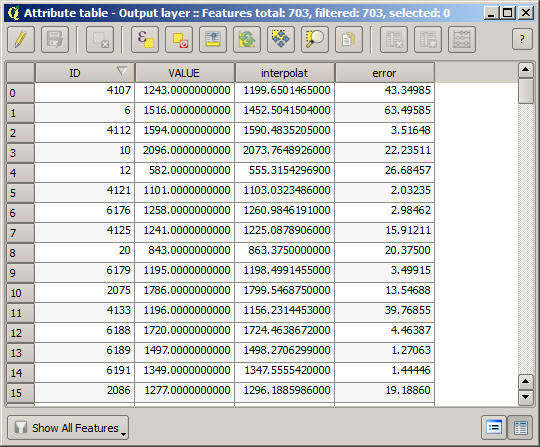
Wir haben nun einen Vektorlayer, der für Punkte die nicht für die Interpolation verwendet wurden, beide Werte enthält.
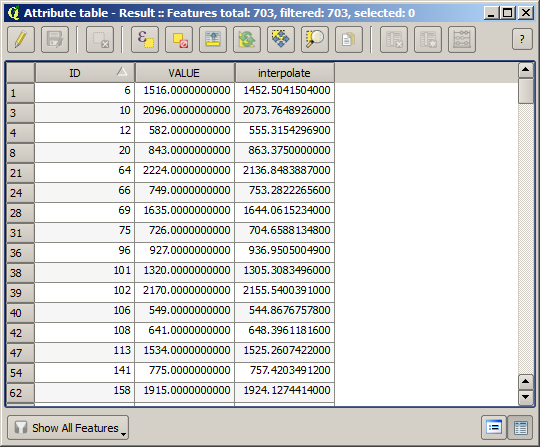
Wir werden für die nächste Aufgabe den Feldrechner verwenden. Öffnen Sie den Algorithmus Feldrechner und starten ihn mit den folgenden Parametern.
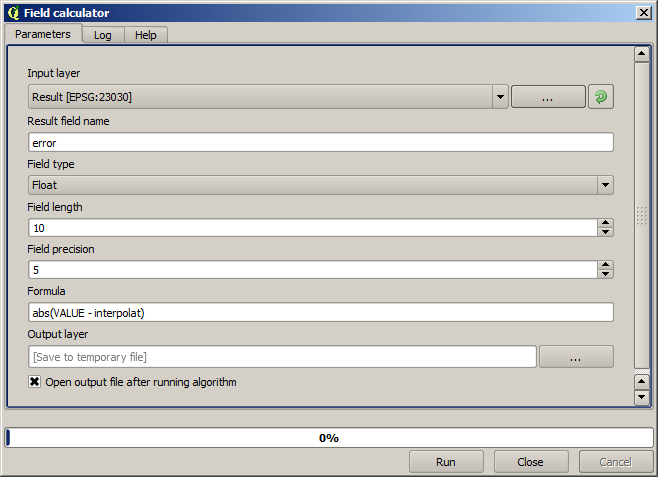
Wenn Ihr Feld mit den Werten aus dem Rasterlayer einen anderen Namen hat, müssen Sie die Formel entsprechend anpassen. Nach dem Ausführen des Algorithmus erhalten Sie einen Layer der nicht für die Interpolation verwendeten Punkte mit der Differenz zwischen den zwei Höhenwerten.
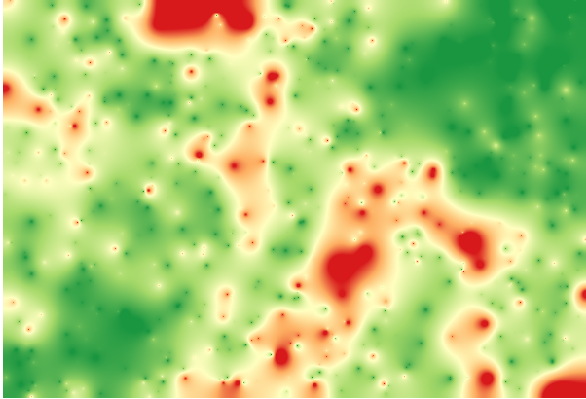
Die Darstellung des Layer entsprechend dieses Wertes gibt uns einen ersten Hinweis, wo die größten Abweichungen liegen.
Die Interpolation dieses Layers liefert einen Rasterlayer mit dem zu erwartenden Fehler für alle Punkte in der interpolierten Fläche.
Sie können dieselbe Information (Differenz zwischen den Ausgangspunktdaten und den interpolierten Werten) auch direkt über erhalten.
Ihre Resultate weichen unter Umständen von den hier ermittelten ab. Dies liegt an der Zufallskomponente, die wir mit der anfänglichen zufälligen Auswahl eingeführt hatten.