Belangrijk
Vertalen is een inspanning van de gemeenschap waaraan u deel kunt nemen. Deze pagina is momenteel voor 100.00% vertaald.
17.23. Meer interpolatie
Notitie
Dit hoofdstuk geeft een ander praktisch geval weer waar algoritmes voor interpolatie werden gebruikt.
Interpolatie is een veel voorkomende techniek, en het kan worden gebruikt om verscheidene technieken te demonstreren die kunnen worden toegepast met behulp van het framework Processing van QGIS. Deze les gebruikt enkele algoritmes voor interpolatie dia al werden besproken, maar het heeft een andere benadering.
De gegevens voor deze les bevat ook een puntenlaag, in dit geval met hoogtegegevens. We gaan het in grote mate op dezelfde manier interpoleren zoals we in de eerdere les deden, maar deze keer zullen we een deel van de originele gegevens opslaan om die te gebruiken om de kwaliteit van het proces van interpolatie te beoordelen.
We moeten eerst de puntenlaag rasteriseren en de resulterende cellen met Geen gegevens vullen, maar met behulp van slechts een fractie van de punten op de laag. We zullen 10% van de punten opslaan voor een latere controle, dus moeten we 90% van de punten klaarmaken voor de interpolatie. We zouden, om dat te doen, het algoritme Split shapes layer randomly kunnen gebruiken, wat we al in een eerdere les hebben gebruikt, maar er is een betere manier om het te doen, zonder dat we een nieuwe tussenliggende laag zouden moeten maken. In plaats daarvan hoeven we slechts de punten die we willen gebruiken voor de interpolatie te selecteren (het gedeelte van 90%), en dan het algoritme uit te voeren. Zoals we al hebben gezien zal het algoritme voor het rasteriseren alleen de geselecteerde punten gebruiken en de rest negeren. De selectie kan worden gedaan met het algoritme Random selection. Voer dat uit met de volgende parameters.
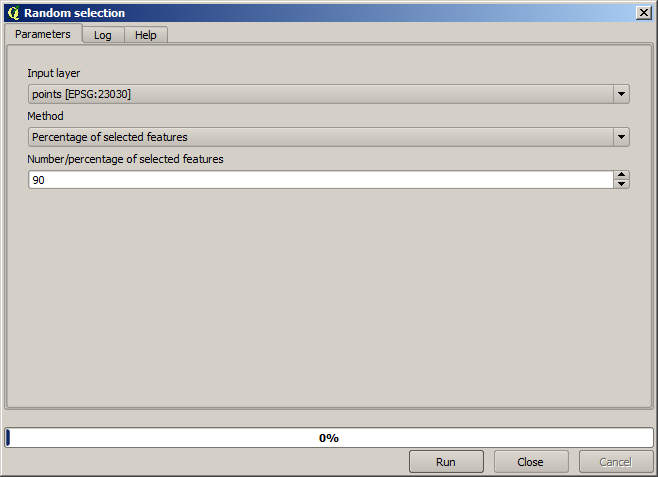
Dat zal 90% van de punten in de laag selecteren om te rasterizeren

De selectie is willekeurig, dus zou uw selectie af kunnen wijken van de selectie die in bovenstaande afbeelding wordt weergegeven.
Voer nu het algoritme Kaart naar raster converteren uit om de eerste rasterlaag te krijgen, en voer dan het algoritme Close gaps uit om de cellen met Geen gegevens te vullen [Celresolutie: 100 m].

We kunnen nu de punten gebruiken die niet zijn geselecteerd om de kwaliteit van de interpolatie te controleren. Op dit punt weten we de echte hoogte (de waarde in de puntenlaag) en de geïnterpoleerde hoogte (de waarde in de geïnterpoleerde rasterlaag). We kunnen die twee vergelijken door de verschillen tussen die waarden te berekenen.
Omdat we de punten gaan gebruiken die niet zijn geselecteerd, laten we dus eerst de selectie omdraaien.

De punten bevatten de originele waarden, maar niet de geïnterpoleerde. We kunnen het algoritme Add raster values to points gebruiken om ze toe te voegen aan een nieuw veld
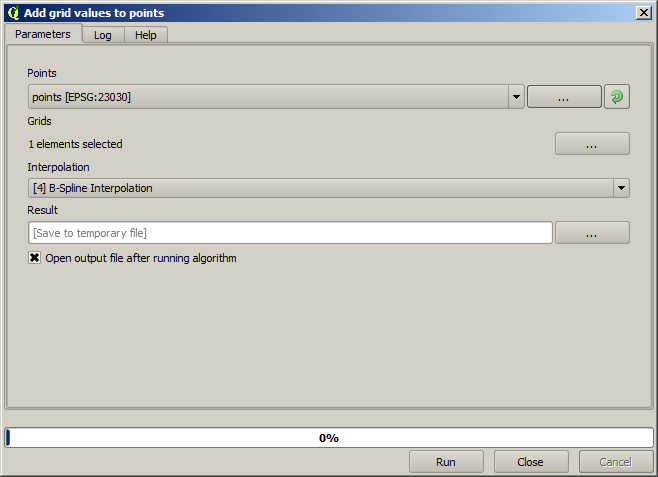
De rasterlaag om te selecteren (het algoritme ondersteunt meerdere rasters, maar we hebben er slechts één nodig) is de resulterende van de interpolatie. We hebben die hernoemd naar interpolate en die laagnaam is die welke zal worden gebruikt als naam voor het veld dat zal worden toegevoegd.
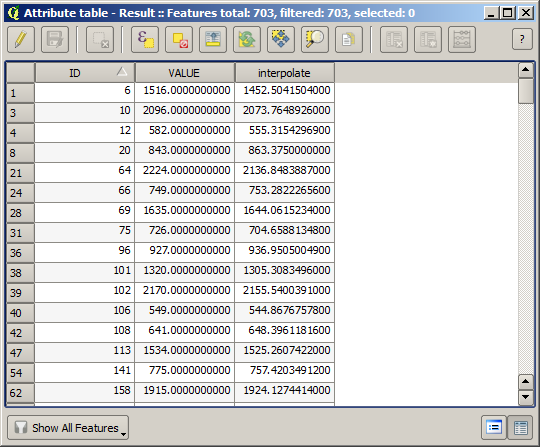
Nu hebben we een vectorlaag die beide waarden bevat, met punten die niet werden gebruikt voor de interpolatie.
Nu zullen we Veldcalculator gebruiken voor deze taak. Open het algoritme Veld calculator en voer dat uit met de volgende parameters.
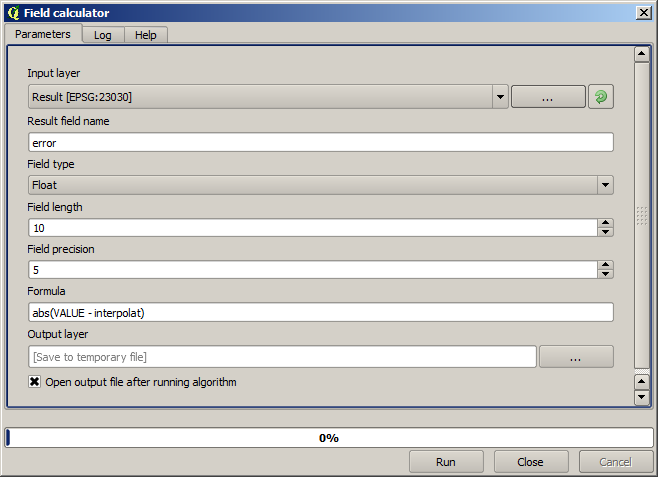
Als uw veld met de waarden uit de rasterlaag een andere naam heeft, zou u de hierboven vermelde formule overeenkomstig moeten aanpassen. Door het uitvoeren van dit algoritme zult u een nieuwe laag verkrijgen met slechts de punten die we niet hebben gebruikt voor de interpolatie, waarvan elk het verschil bevat tussen de twee hoogtewaarden.
Weergeven van die laag overeenkomstig die waarde zal ons een eerste idee geven over waar de grootste verschillen te vinden zullen zijn.
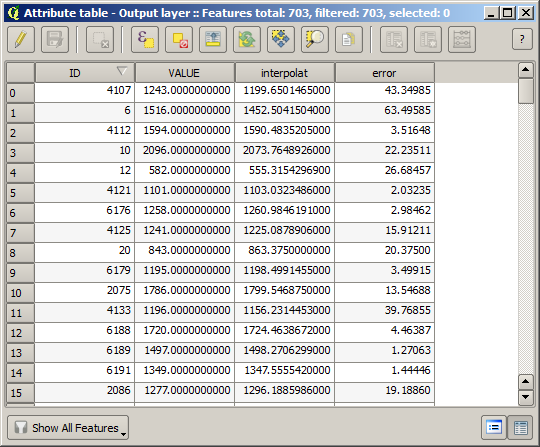
Interpoleren van die laag zal u een rasterlaag geven met de geschatte fout in alle punten van het geïnterpoleerde gebied.
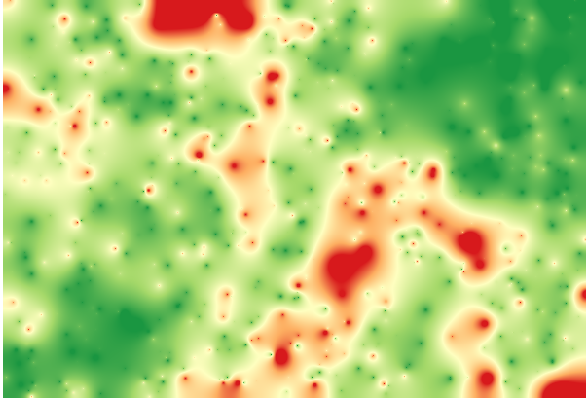
U kunt dezelfde informatie (verschil tussen originele puntwaarden en de geïnterpoleerde) ook direct krijgen met .
Uw resultaten zouden af kunnen wijken van deze, omdat er een willekeurige component werd geïntroduceerd bij het uitvoeren van de willekeurige selectie, aan het begin van deze les.