21. Folha de respostas¶
21.1. Results For Añadiendo Tu Primera Capa¶
21.1.1.  Preparación¶
Preparación¶
You should see a lot of lines, symbolizing roads. All these lines are in the vector layer that you just loaded to create a basic map.
21.2. Results For Un resumen de la Interfaz¶
21.2.1. Resumen (Parte 1)¶
Refiérase a la imagen que muestra el diseño de la interfaz y comprobar que recuerdas los nombres y las funciones de los elementos de la pantalla.
21.2.2. Resumen (Parte 2)¶
Guardar como
Zoom a la capa
Ayuda
Renderizado on/off
Línea de medida
21.3. Results For Trabajando con Datos Vector¶
21.3.1. Shapefiles¶
There should be five layers on your map:
lugares
- water
- buildings
- rivers and
- roads.
21.3.2. Databases¶
All the vector layers should be loaded into the map. It probably won’t look nice yet though (we’ll fix the ugly colors later).
21.4. Results For Simbología¶
21.4.1. Colores¶
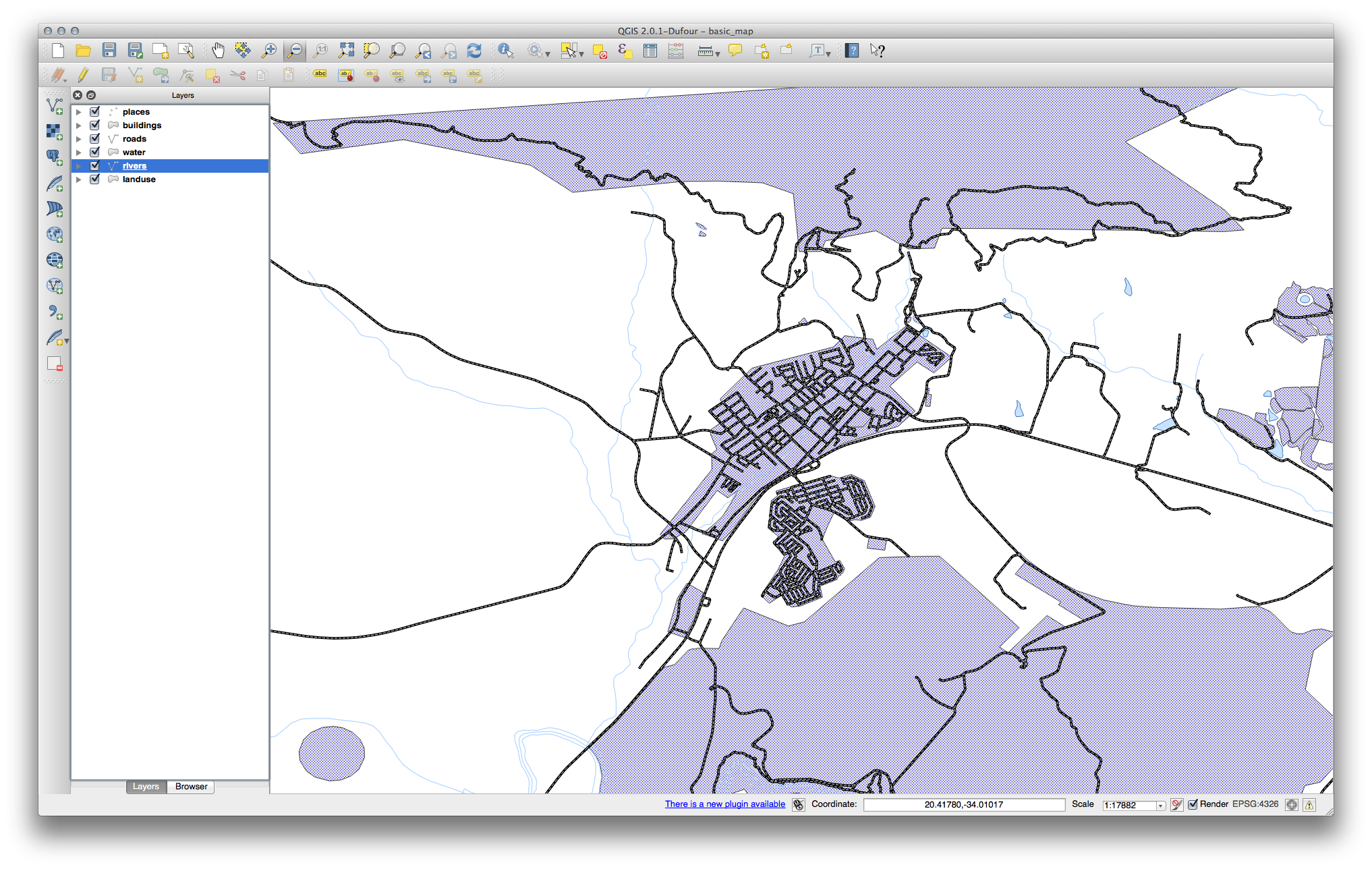
Comprueba que los colores están cambiando como esperas que cambien.
- It is enough to change only the water layer for now. An example is below, but may look different depending on the color you chose.
Nota
If you want to work on only one layer at a time and don’t want the other layers to distract you, you can hide a layer by clicking in the check box next to its name in the Layers list. If the box is blank, then the layer is hidden.
21.4.2. Estructura de símbolos¶
Ahora tu mapa debería aparecer así:
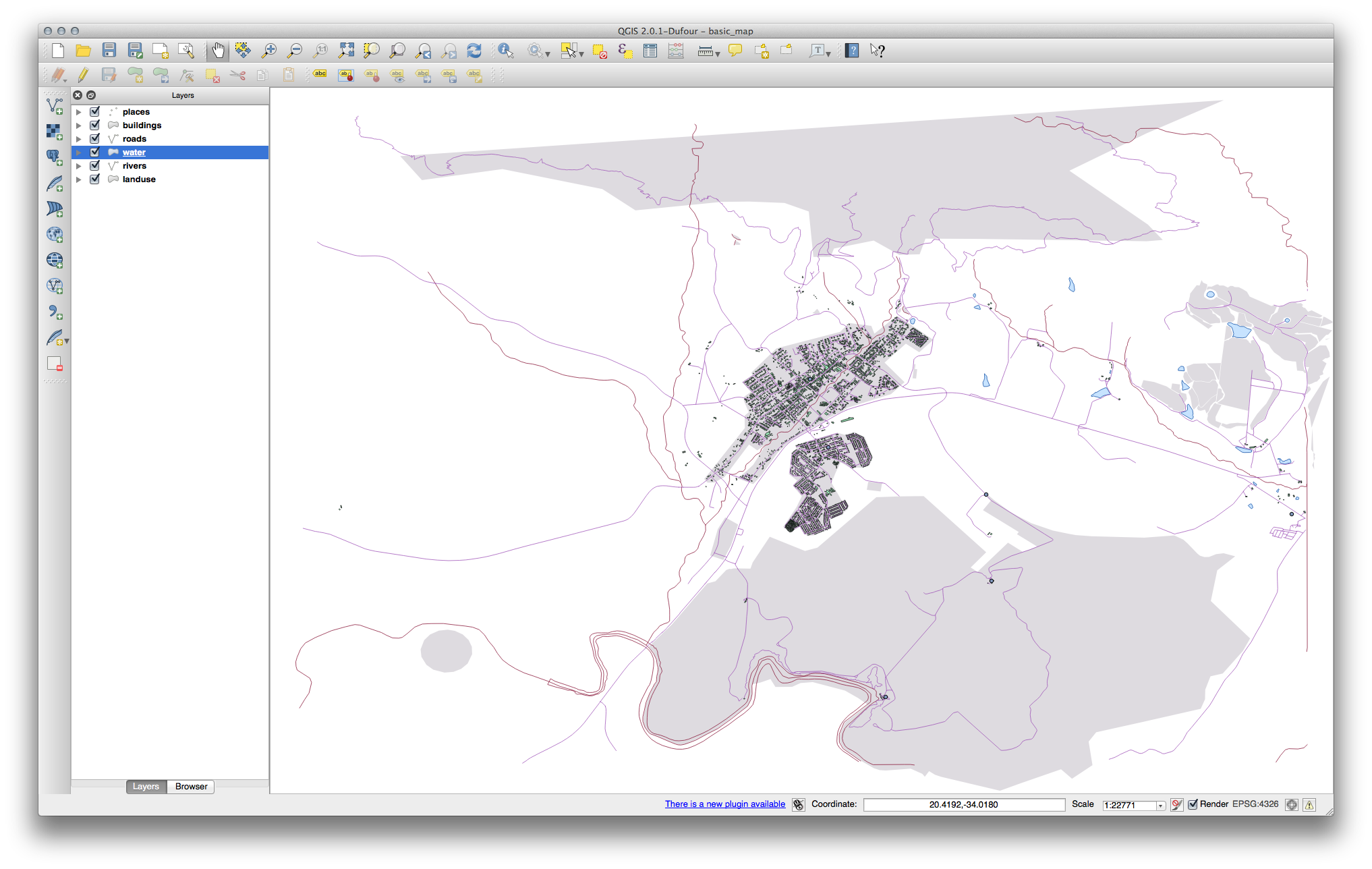
Si tu eres un usuario principiante, puede detenerse aquí.
Use el método anterior para cambiar los colores y estilos a todas las capas restantes.
Trata de usar colores naturales para los objetos. Por ejemplo, una carretera no debería ser roja o azul, pero si puede ser gris o negro.
- Also feel free to experiment with different Fill Style and Border Style settings for the polygons.
21.4.3.  Capas de símbolos¶
Capas de símbolos¶
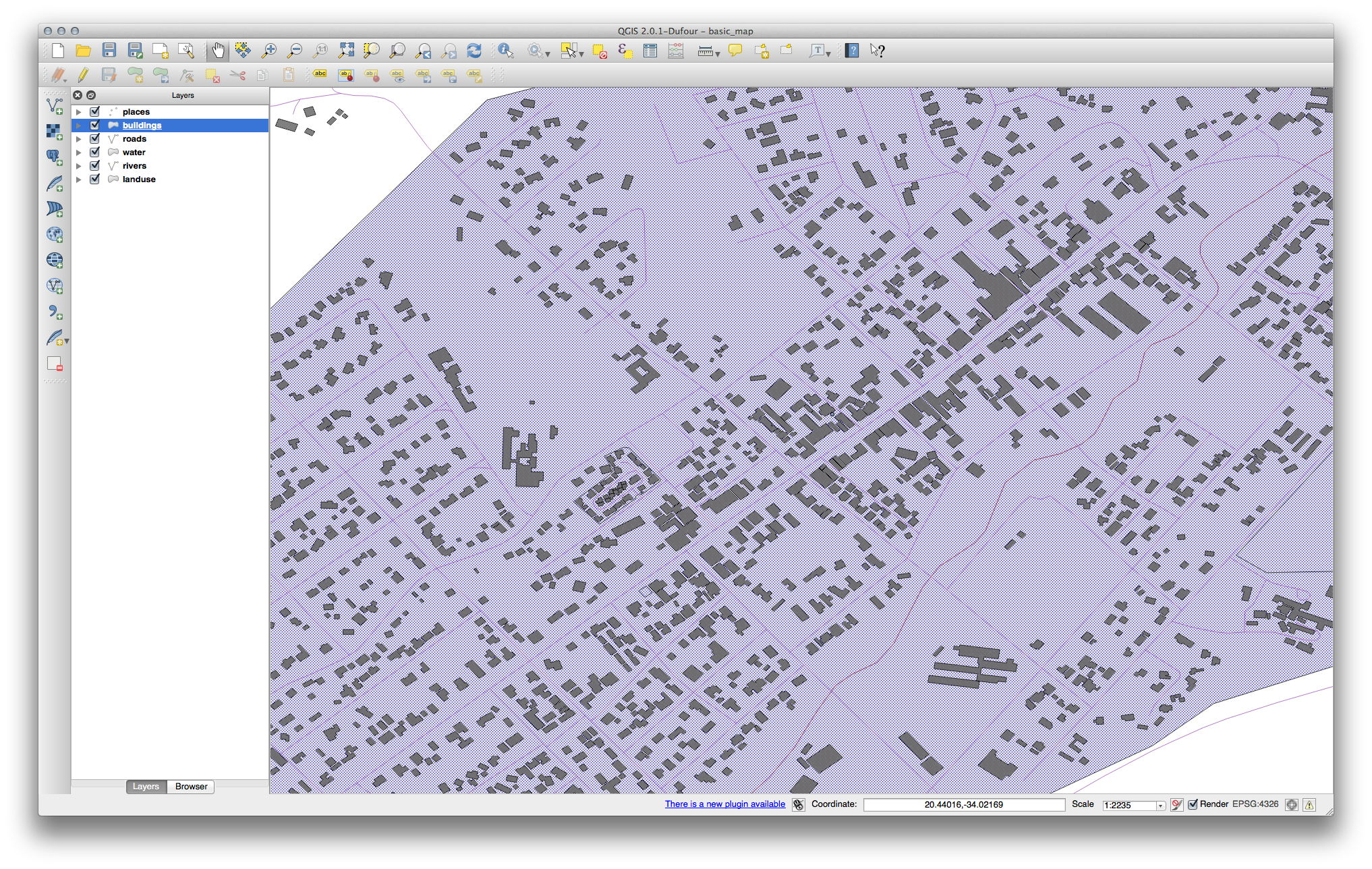
Personaliza tu construcciones capa como gustes, pero recuerda que tiene que ser fácil de contar las diferentes partes del mapa.
He aquí un ejemplo:
21.4.4. Niveles de símbolo¶
To make the required symbol, you need two symbol layers:
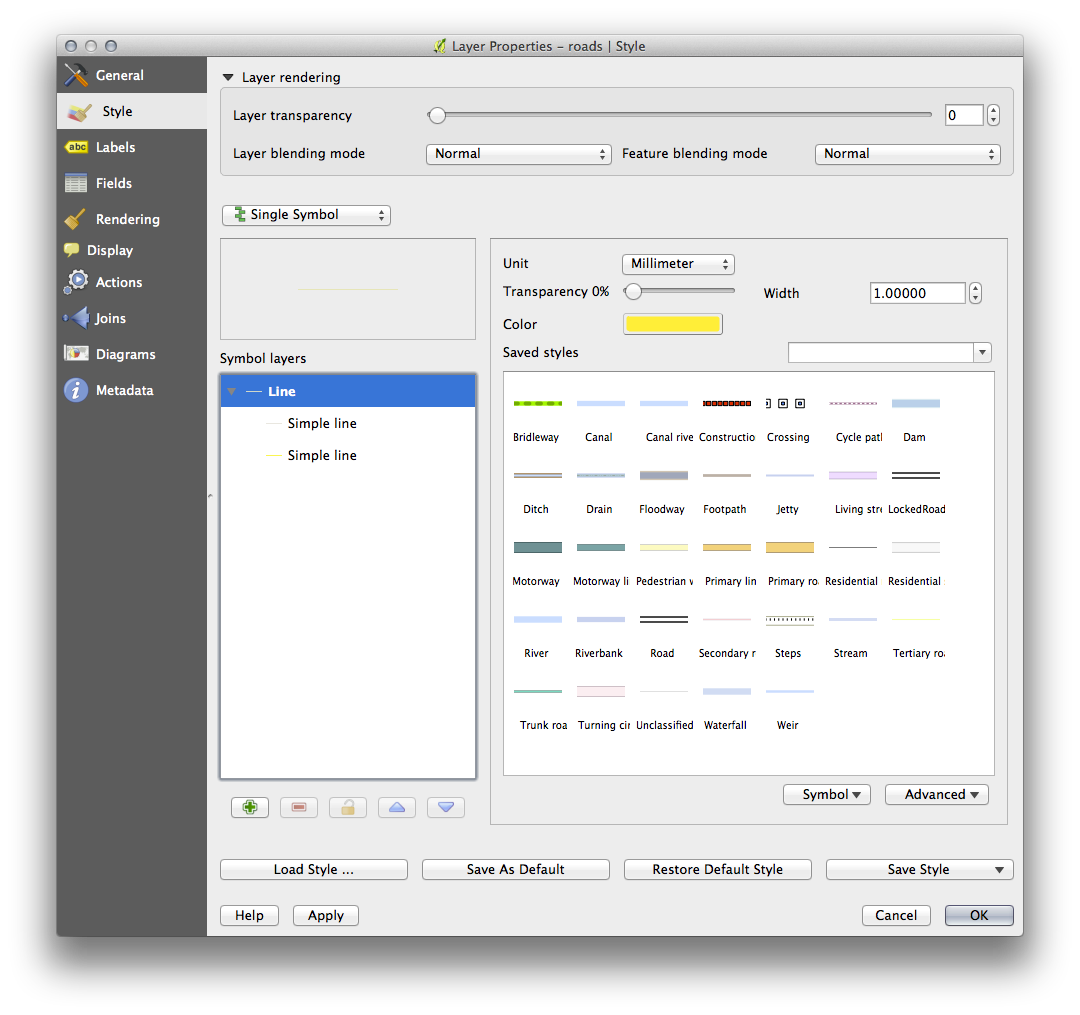
The lowest symbol layer is a broad, solid yellow line. On top of it there is a slightly thinner solid gray line.
If your symbol layers resemble the above but you’re not getting the result you want, check that your symbol levels look something like this:

Ahora tu mapa debería tener este aspecto:
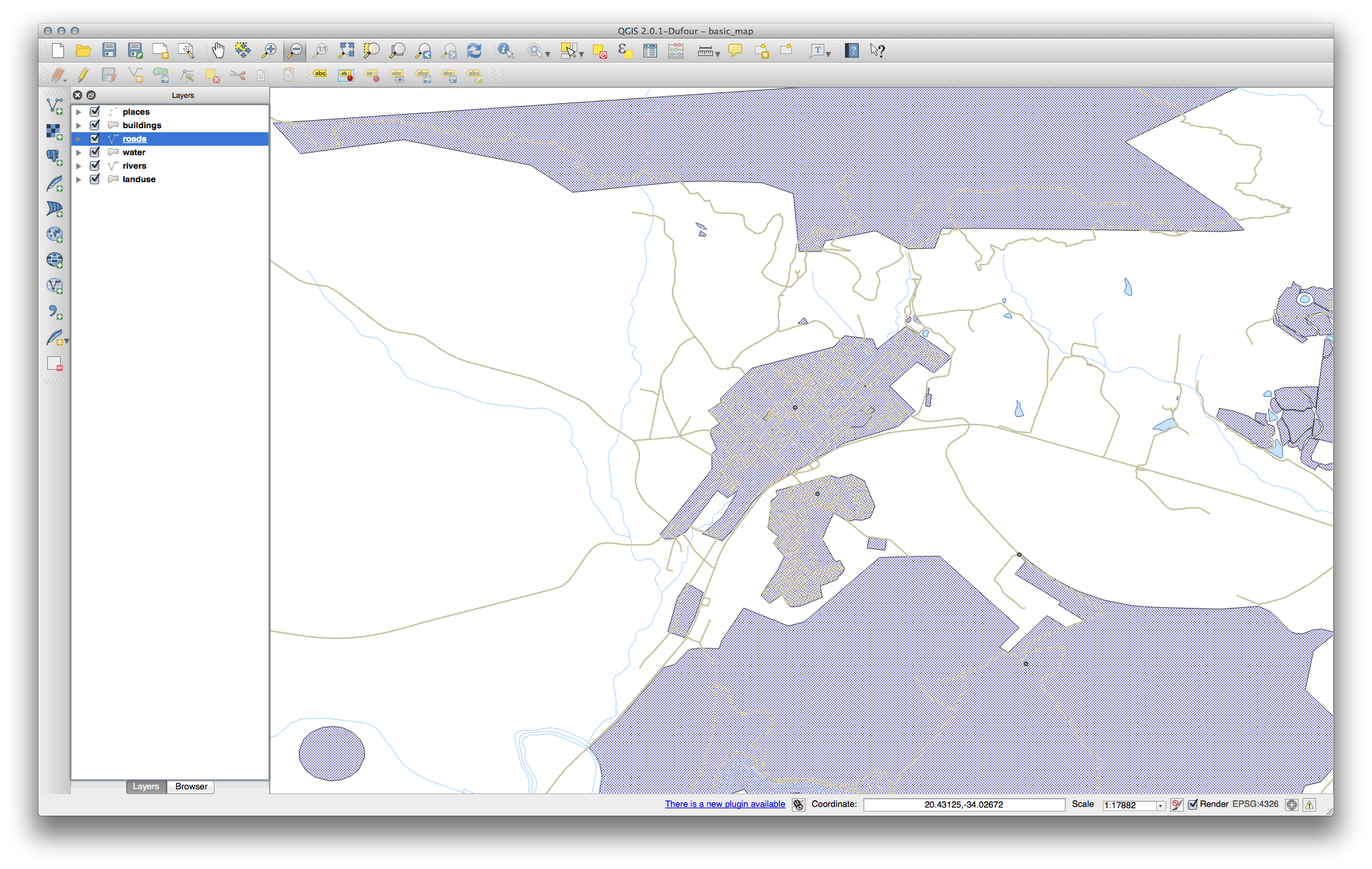
21.4.5.  Niveles de símbolo¶
Niveles de símbolo¶
Ajustar tus niveles de símbolo a estos valores:
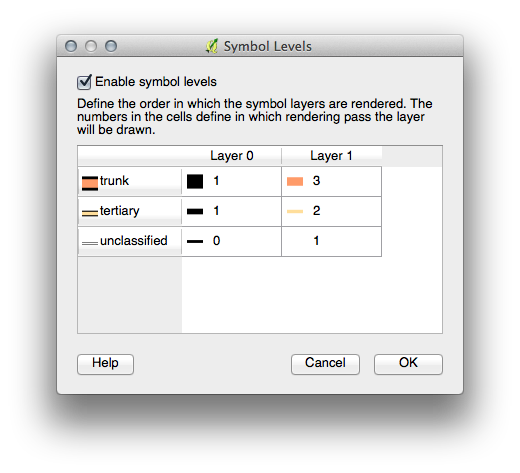
Probar con diferentes valores para dar diferentes resultados.
Abrir de nuevo su mapa original antes de continuar con el siguiente ejercicio.
21.5. Results For Atributo de dato¶
21.5.1. * Atributo de dato*¶
The NAME field is the most useful to show as labels. This is because all its values are unique for every object and are very unlikely to contain NULL values. If your data contains some NULL values, do not worry as long as most of your places have names.
21.6. Results For La herramienta de etiqueta¶
21.6.1. Personalizarción de Etiqueta (Parte 1)¶
Su mapa ahora debe presentar los puntos del marcador y las etiquetas deben compensarse por :kbd::2.0 mm: El estilo de los marcadores y etiquetas debe permitir que sean claramente visibles en el mapa:
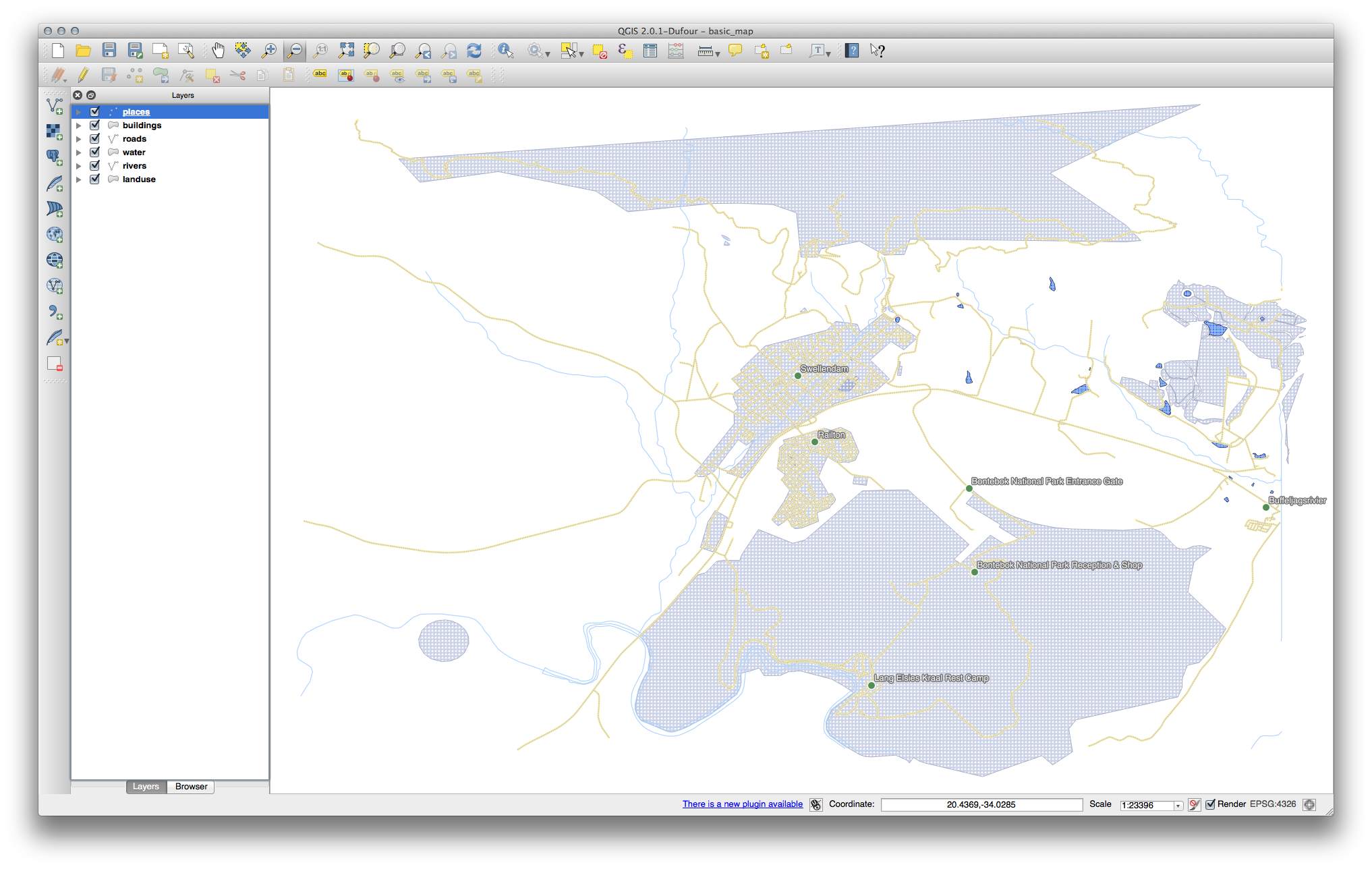
21.6.2. Personalizarción de Etiqueta (Parte 2)¶
Una posible solución tiene este producto final:

Para llegar a este resultado:
Use un tamaño de fuente de 10, un :guialabel::Distancia de etiqueta de 1,5 mm, :guialabel:`Ancho de símbolo` and :guialabel:`Tamaño de símbolo` de 3.0 mm.
Además, este ejemplo usa el Etiqueta envuelta en caracteres opción:
Introduzca un _kbd:espacio en este campo y clic en Aplicar para lograr el mismo efecto. En nuestro caso, algunos de los nombres de lugares son muy largos, resultando en nombres con múltiples líneas que no sera muy fácil de usar. Usted puede encontrar un ajuste que sea mas apropiado a su mapa.
21.6.3. Utilización de la configuración de definición de datos¶
Aún en modo edición, establecer los valores de FONT_SIZE a cualquiera que prefiera. El ejemplo usa 16 para ciudades, 14 para suburbios, 12 para localidades y 10 para haldeas.
Recuerda guardar cambios y salir del modo edición.
Regresar a Texto opción de formato de la capa lugares y selecciona Tamaño de fuente en el Campo de atributos de el tamaño de fuente de datos desplegable:
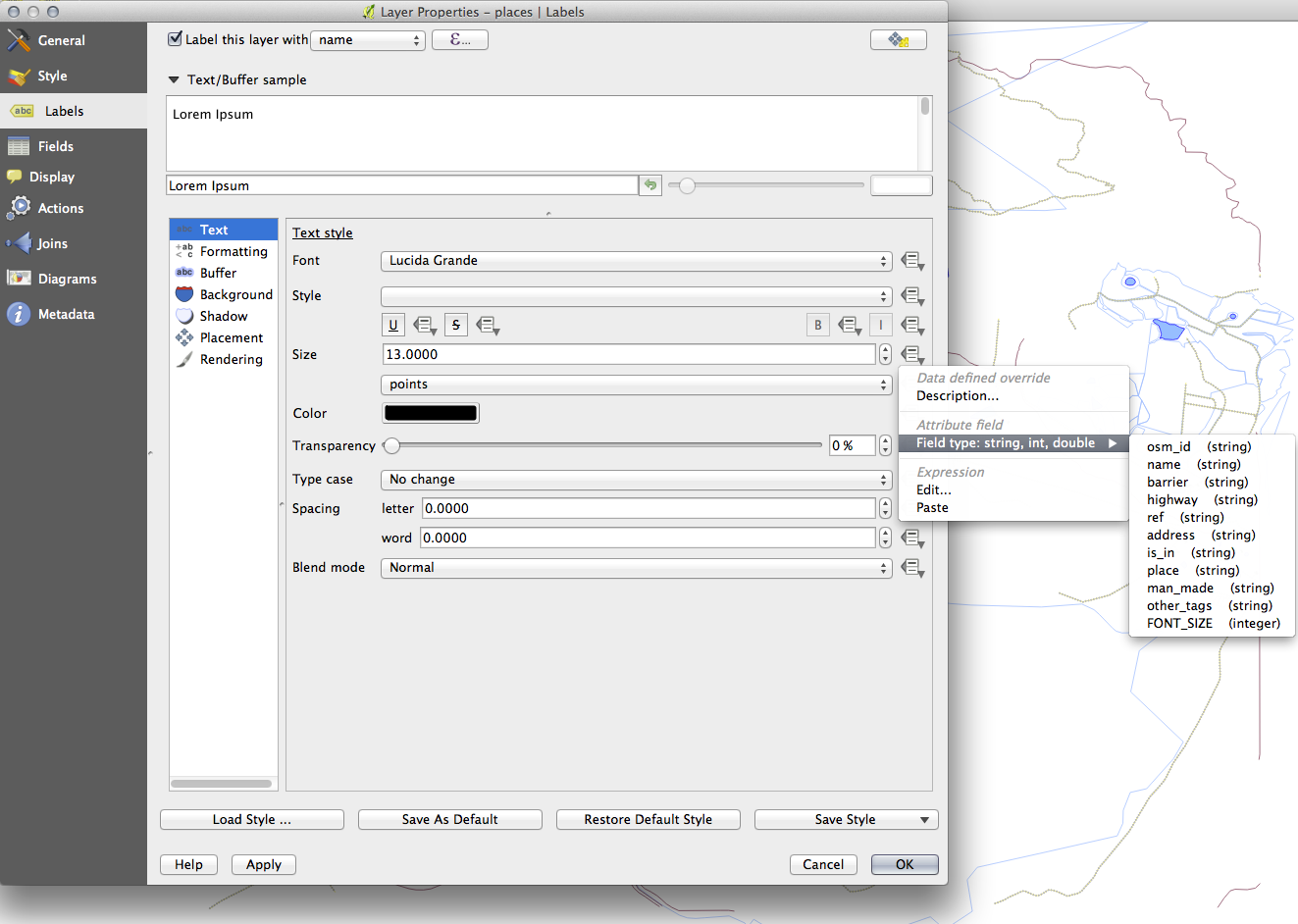
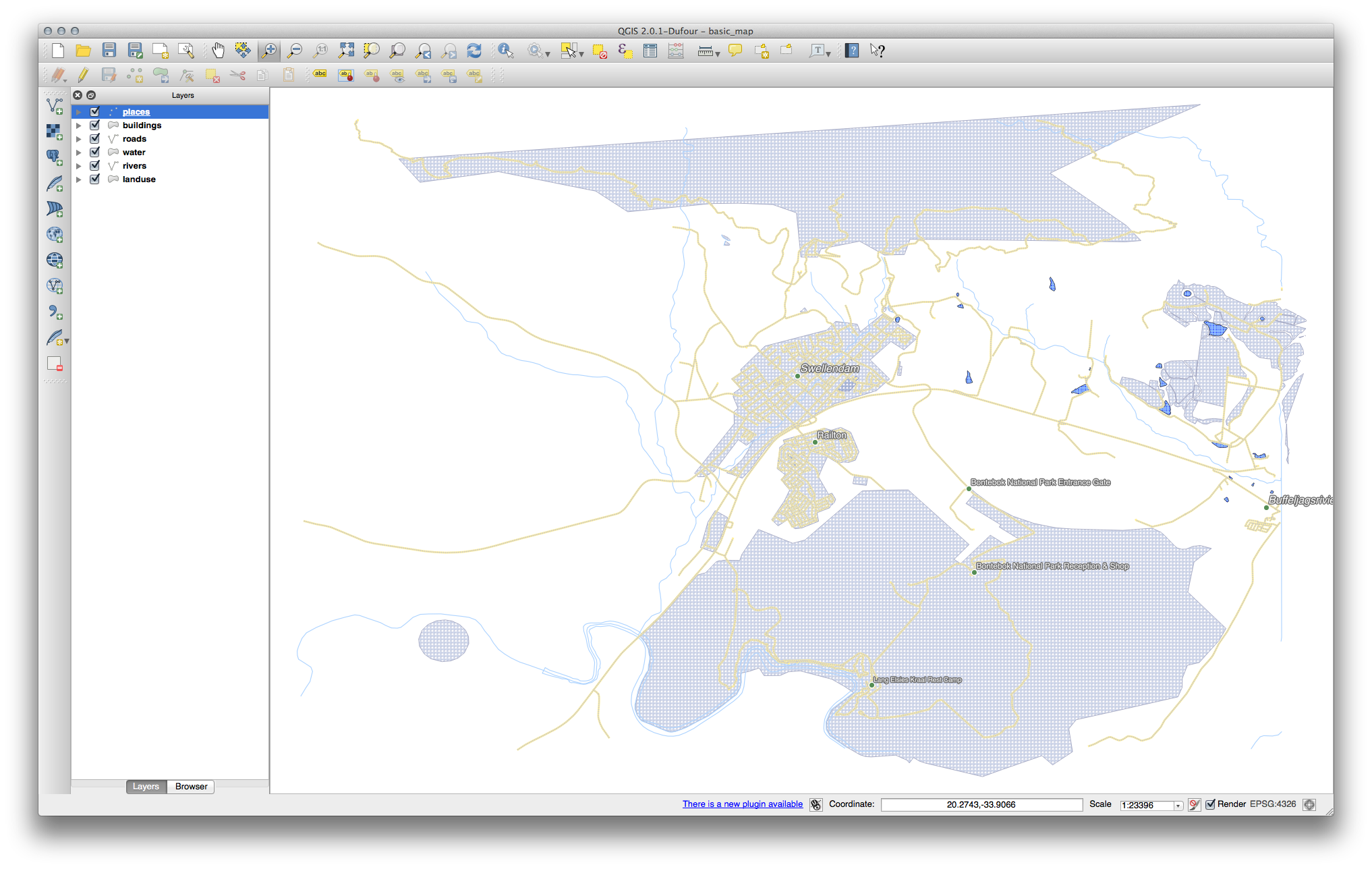
Sus resultados, si usó los valores antes mencionados, debería ser esto:
21.7. Results For Clasificación¶
21.7.1. Refinar la clasificación¶
Usa el nombre del método como en el primer ejercicio de la lección para deshacerse de los límites:
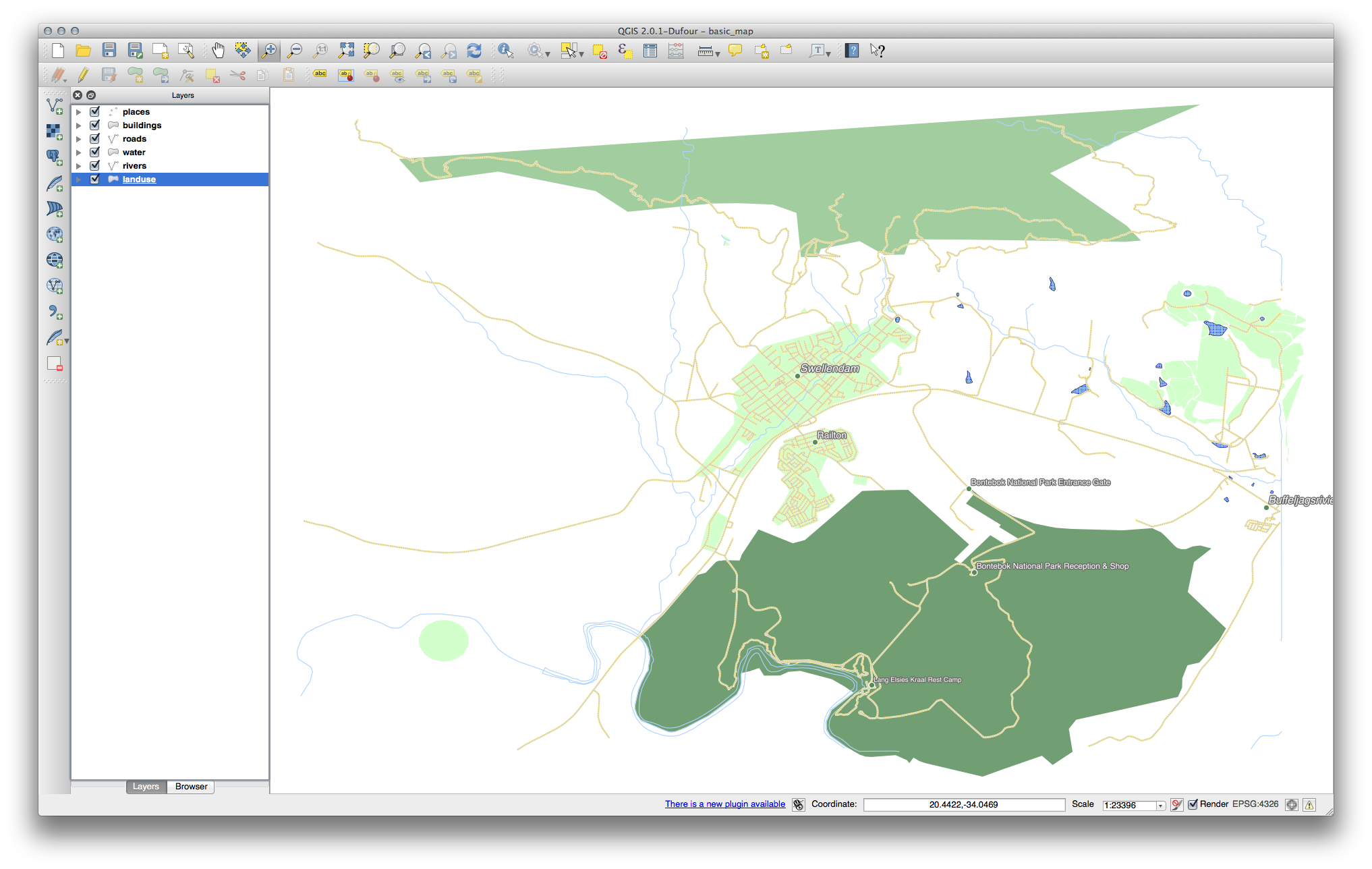
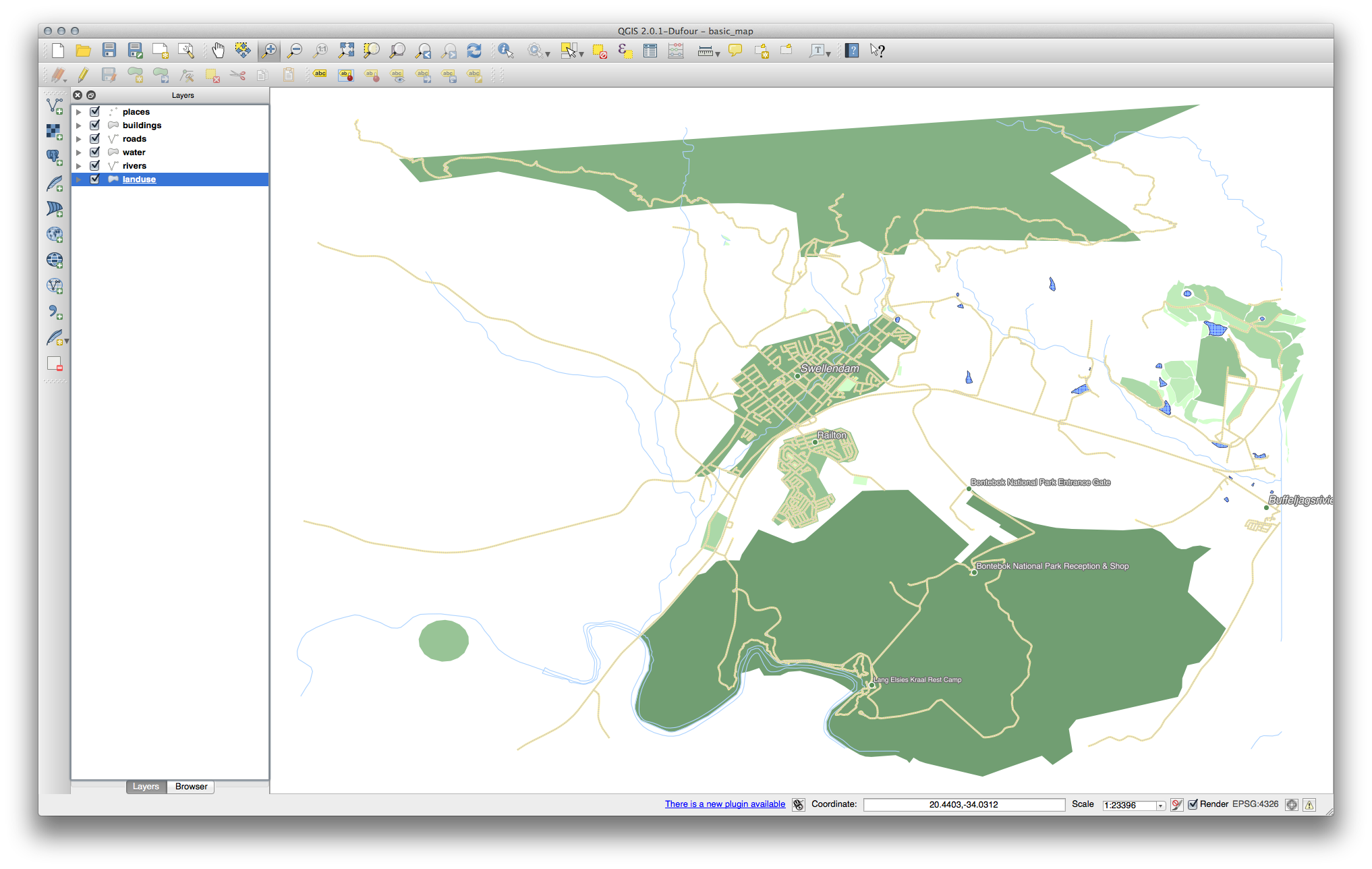
Los ajustes utilizados pueden no ser los mismos, pero con los valores Clases = 6 y Modo = Natural Breaks(Jenks) (y usando los mismos colores, por supuesto), el mapa se verá así:
21.8. Results For Creando un nuevo conjunto de datos vector¶
21.8.1. Digitalizar¶
La simbología no importa, pero los resultados deberían verse más o menos como esto:
21.8.2. Topología: Herramienta de agregar anillo¶
La forma exacta no importa, pero debería estar recibiendo un agujero en medio de su rasgo, como la siguiente:
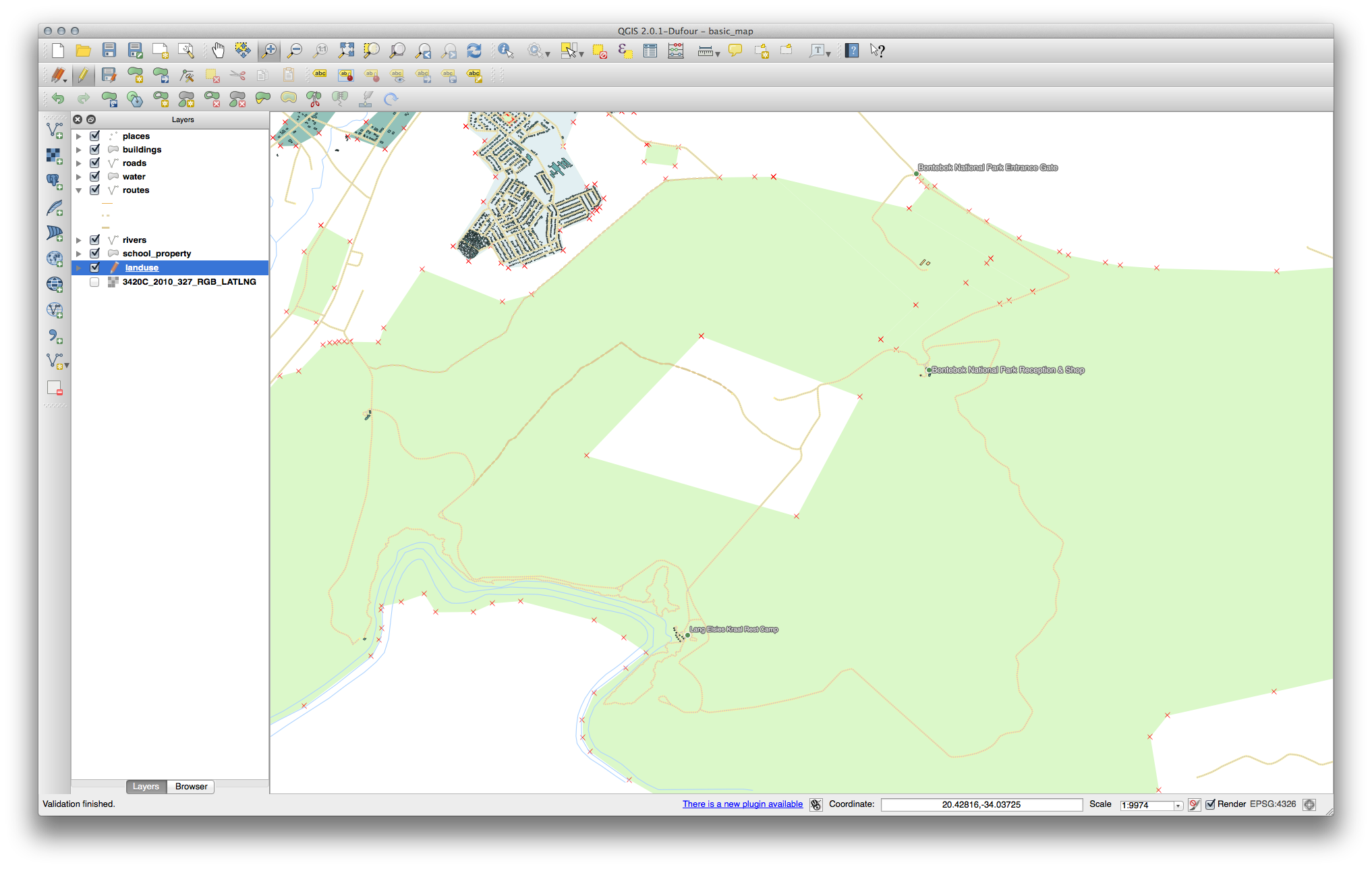
Deshacer su edición antes de continuar con el ejercicio con la siguiente herramienta.
21.8.3. Topología: Herramienta de agregar parte¶
Primero selecciona el Bontebok National Park:
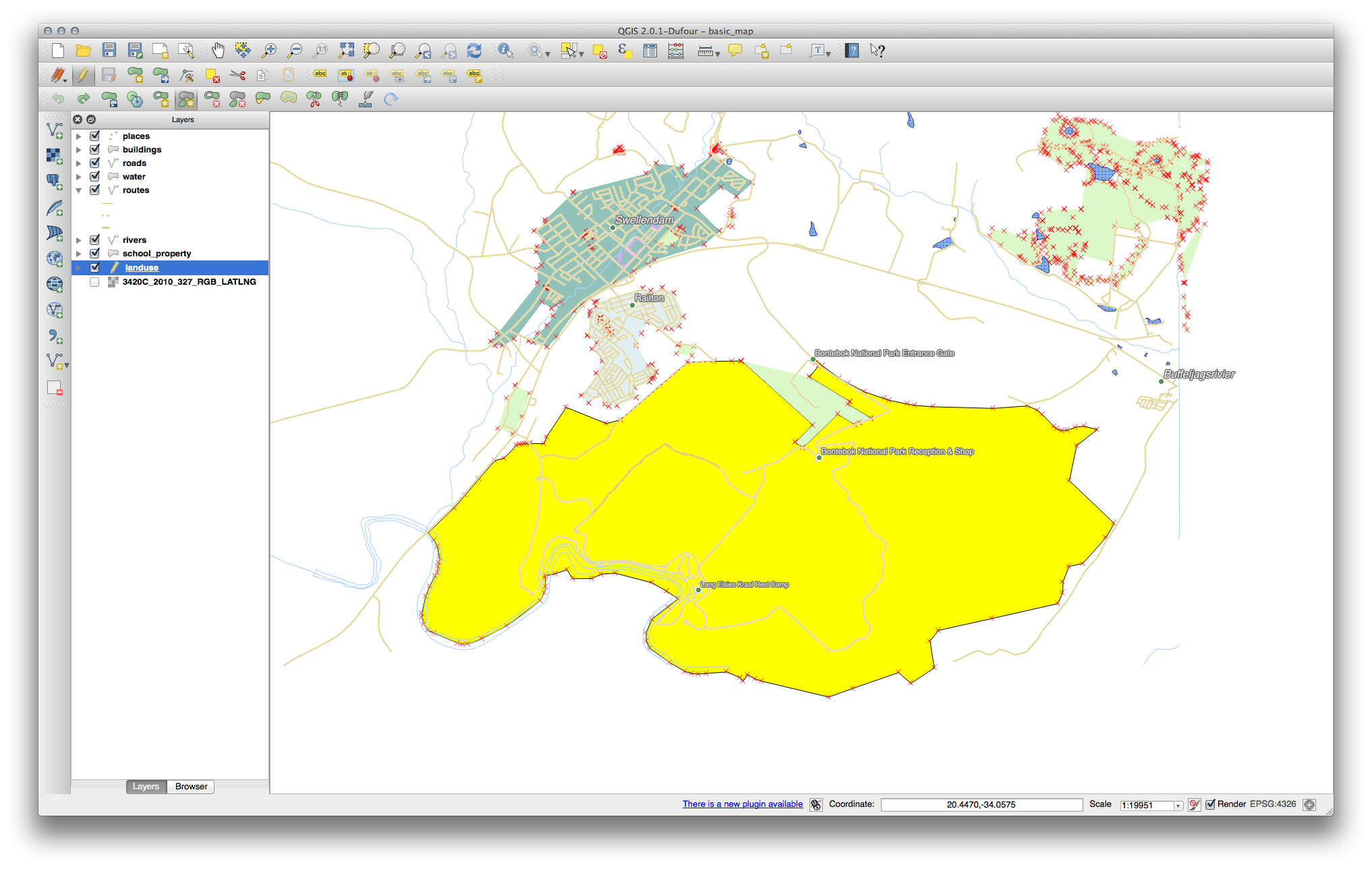
Ahora agregar su nueva parte:
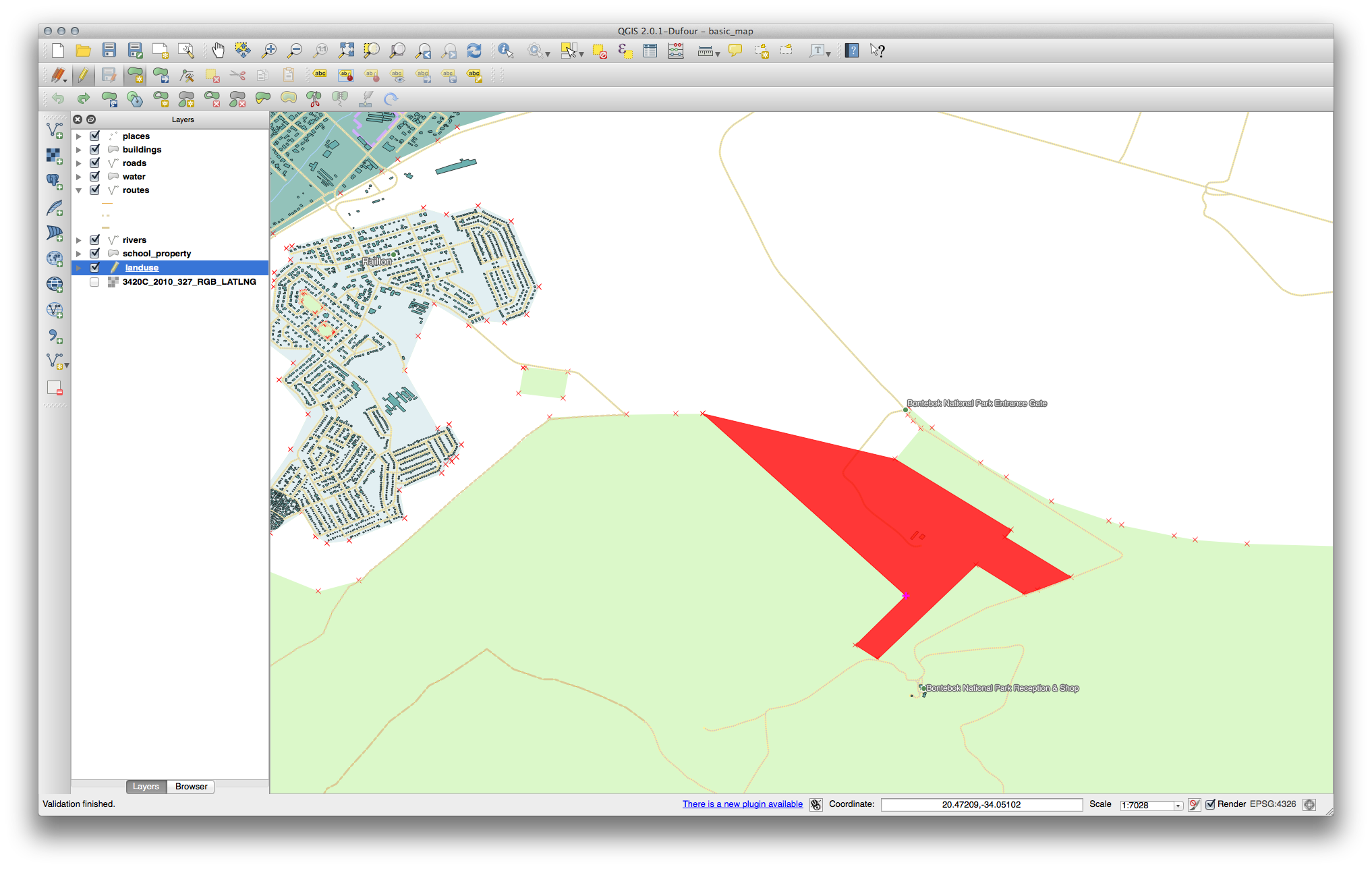
Deshacer su edición antes de continuar con el ejercicio con la siguiente herramienta.
21.8.4. Unir objetos espaciales¶
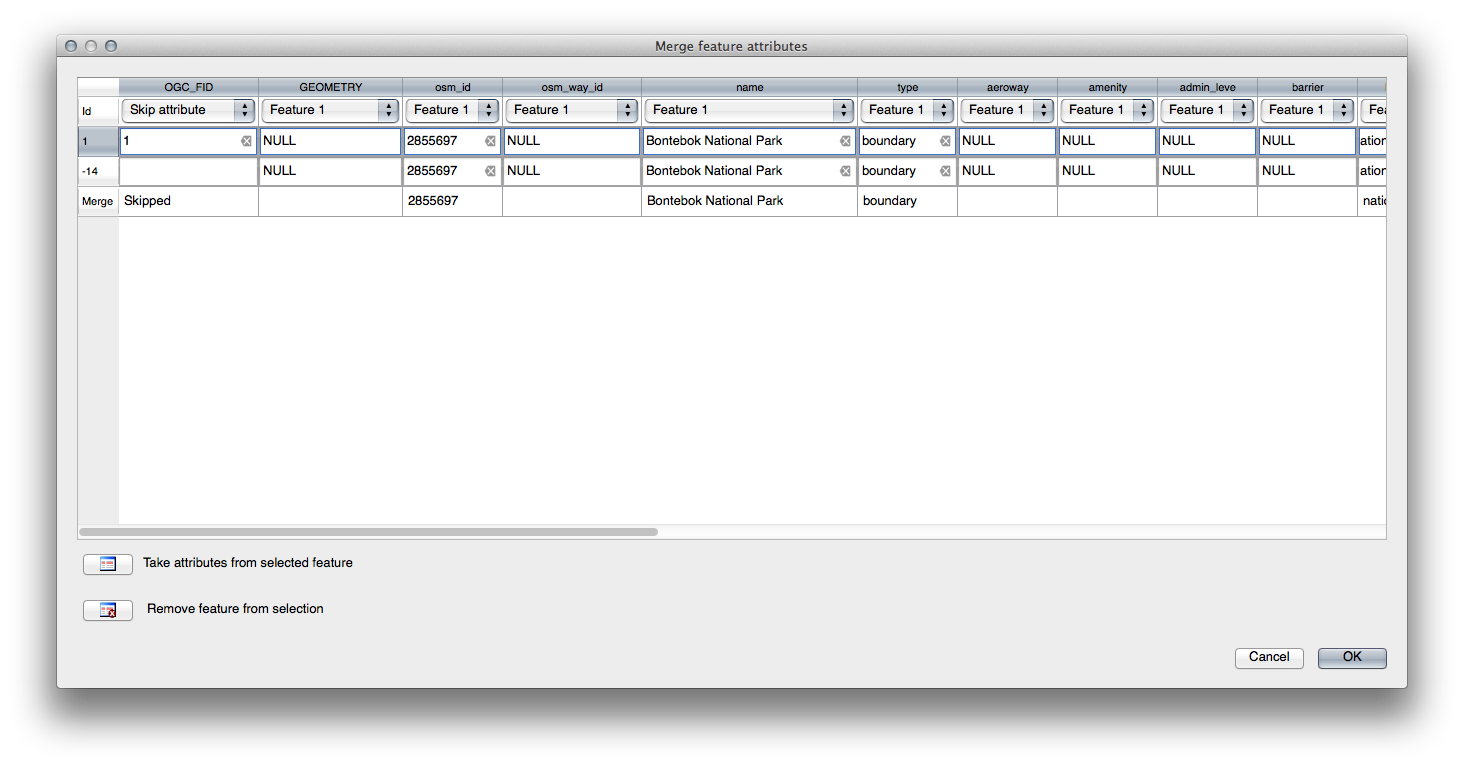
Use la herramienta Merge Selected Features, para estar seguro, primero seleccione los poligonos que desee unir.
Use el rasgo con el OGC_FID de 1 como la fuente de sus atributos (clic en la entrada correspondiente de la ventana de dialogo, después clic en el botón Tomar los atributos del rasgo seleccionado):
Nota
- Si estas usando diferente conjunto de datos, es altamente probable que su
Polígono original OGC_FID no será 1. Solo tiene que elegir el rasgo que tiene un OGC_FID.
Nota
Usando la herramienta Unir atributos de los rasgos seleccionados mantendrá las distintas geometrías, pero les dará los mismo atributos.
21.8.5. Formas¶
Para el TIPO, hay obviamente un cantidad límite de tipos que una carretera puede tener, si revisa la tabla de atributos de la capa, verá que están predefinidos.
Establecer el widget a Valor del mapa y clic Cargar datos de la capa.
Seleccionar Carreteras in el Etiqueta desplegable y autopista para ambos las opciones de Valor y Descripción:
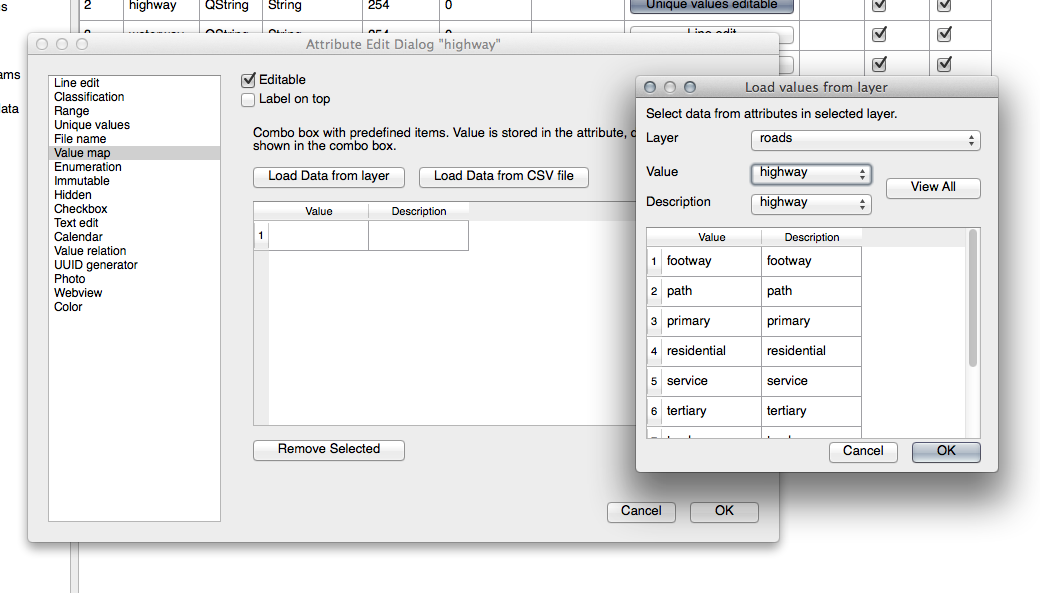
Clic tres veces en Ok.
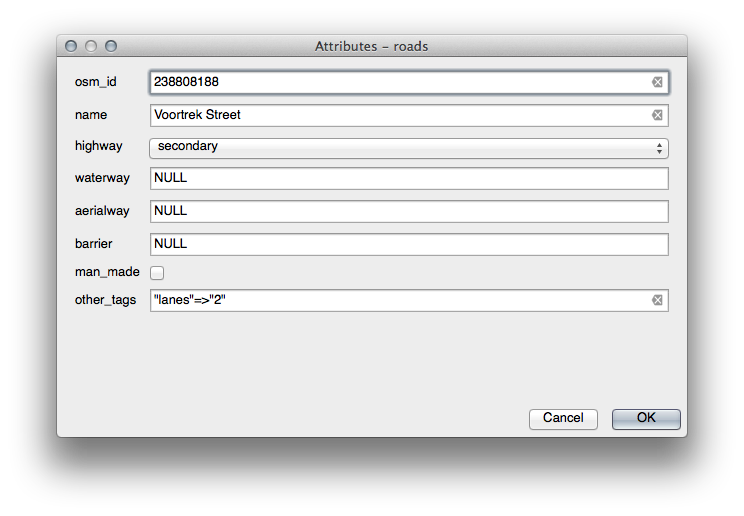
Si usa la herramienta Identificación en una calle mientras esta activo el modo edición, la ventana de dialogo que deberías ver será como esto:
21.9. Results For Análisis Vector¶
21.9.1. Extract Your Layers from OSM Data¶
For the purpose of this exercise, the OSM layers which we are interested in are multipolygons and lines. The multipolygons layer contains the data we need in order to produce the houses, schools and restaurants layers. The lines layer contains the roads dataset.
The Query Builder is found in the layer properties:

Using the Query Builder against the multipolygons layer, create the following queries for the houses, schools, restaurants and residential layers:
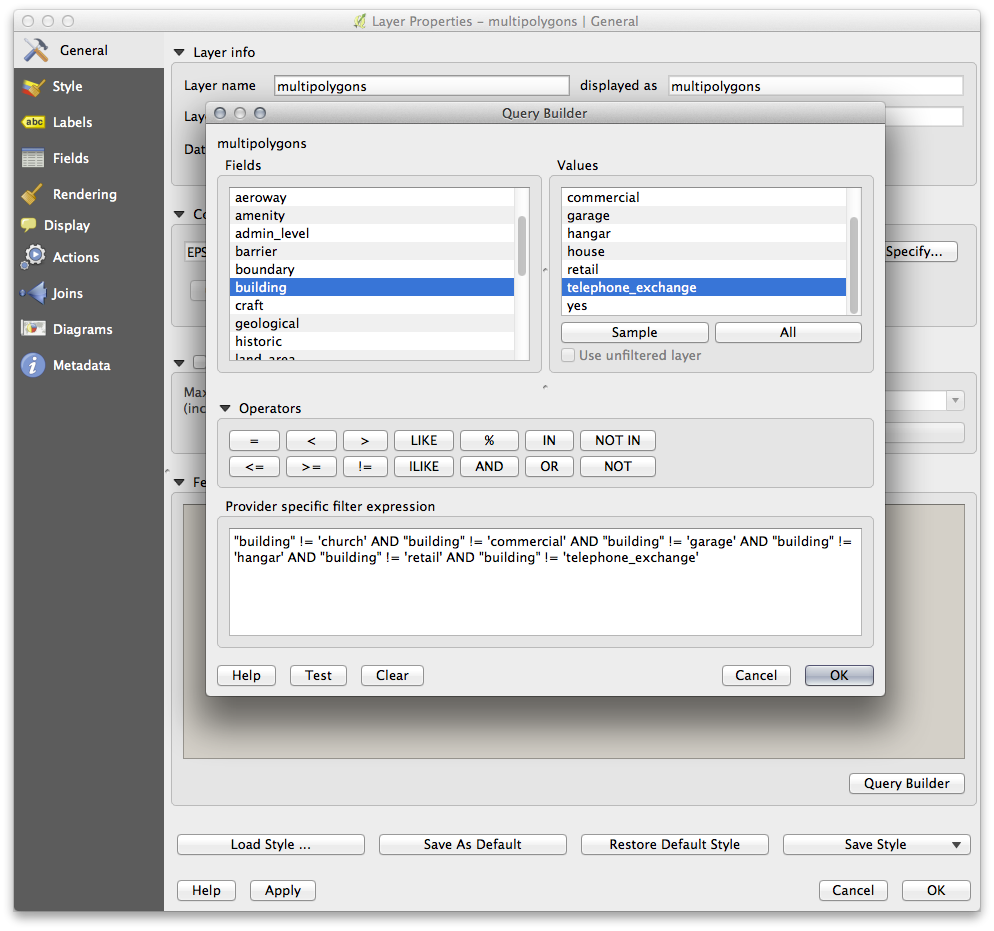
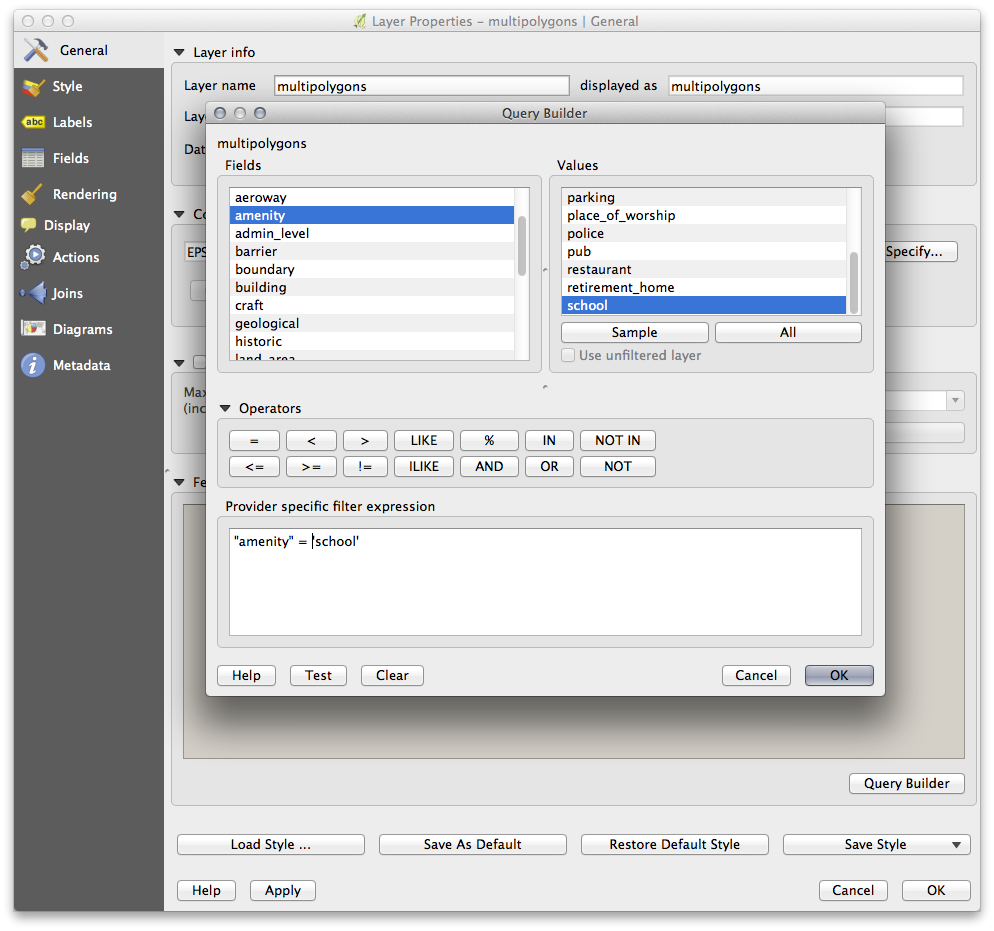
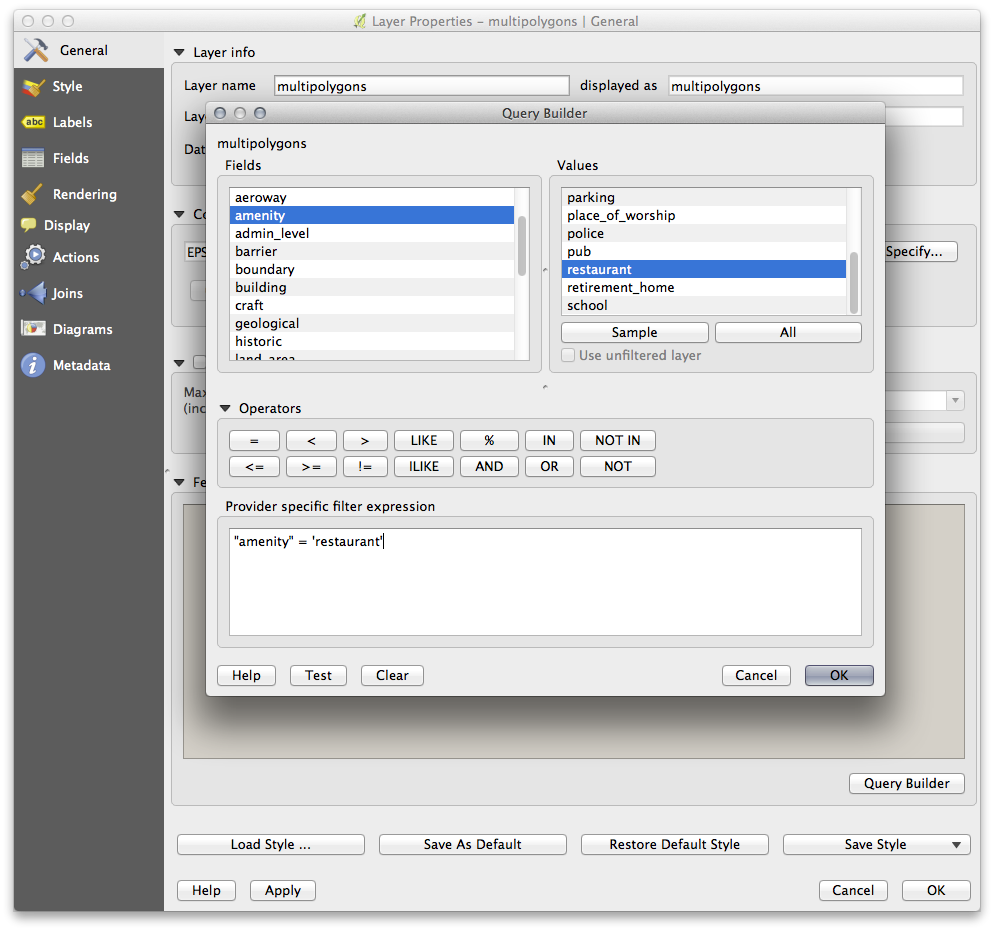
Once you have entered each query, click OK. You’ll see that the map updates to show only the data you have selected. Since you need to use again the multipolygons data from the OSM dataset, at this point, you can use one of the following methods:
- Rename the filtered OSM layer and re-import the layer from osm_data.osm, OR
- Duplicate the filtered layer, rename the copy, clear the query and create your new query in the Query Builder.
Nota
Although OSM’s building field has a house value, the coverage in your area - as in ours - may not be complete. In our test region, it is therefore more accurate to exclude all buildings which are defined as anything other than house. You may decide to simply include buildings which are defined as house and all other values that have not a clear meaning like yes.
To create the roads layer, build this query against OSM’s lines layer:
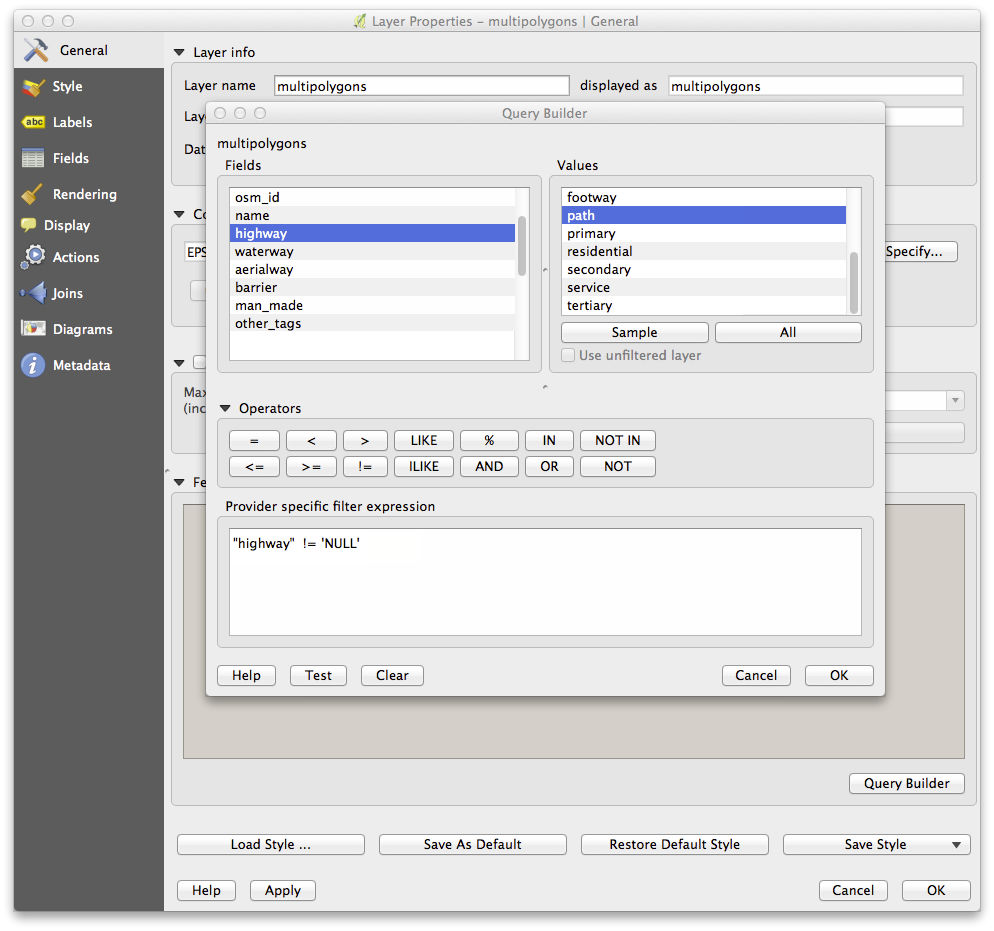
You should end up with a map which looks similar to the following:
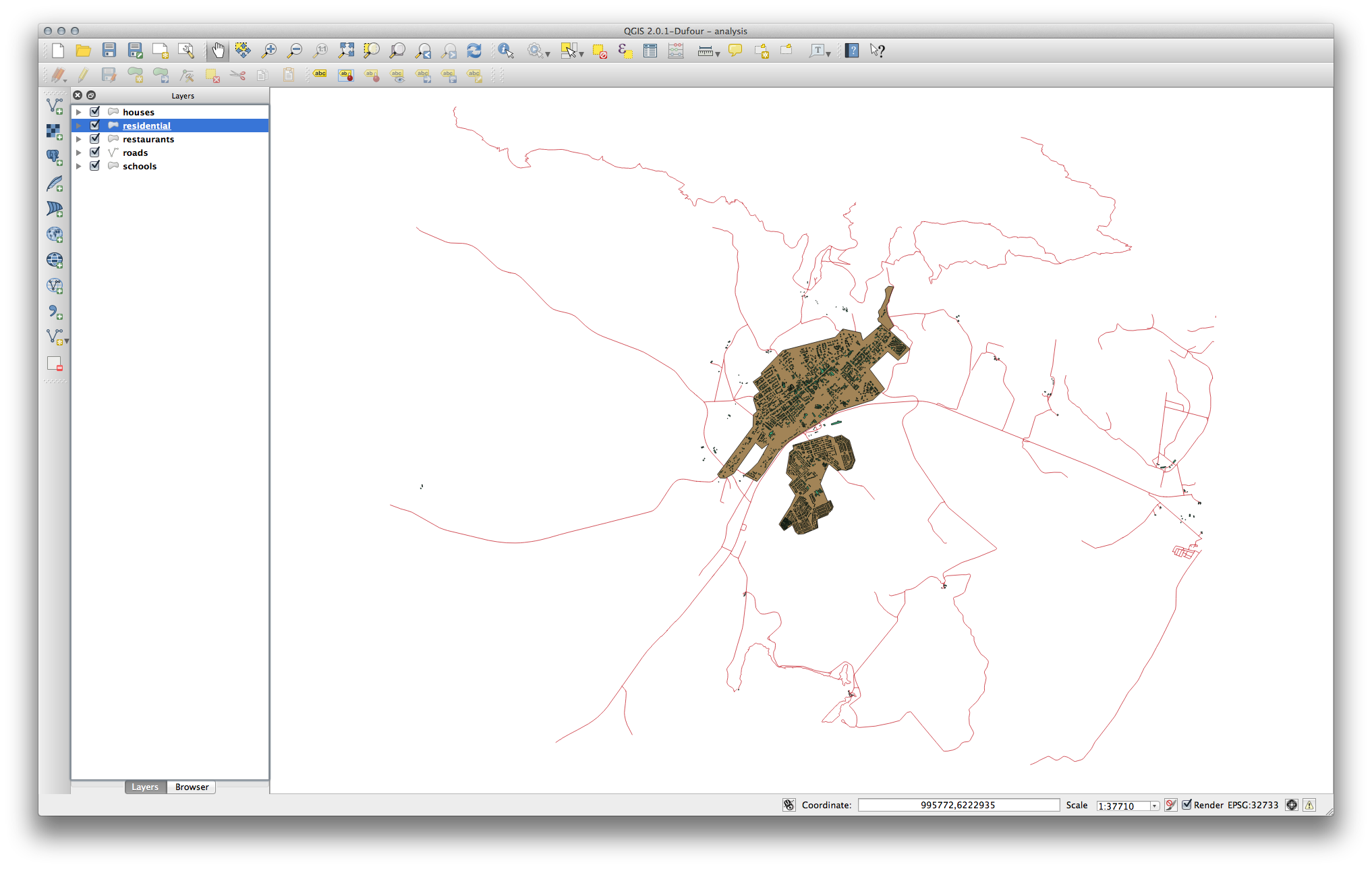
21.9.2. Distancia desde institutos¶
Su diálogo de buffer debería parecerse a esto:
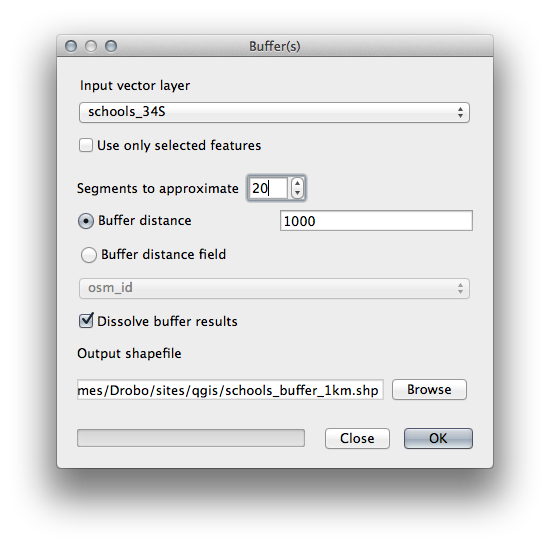
The Buffer distance is 1000 meters (i.e., 1 kilometer).
The Segments to approximate value is set to 20. This is optional, but it’s recommended, because it makes the output buffers look smoother. Compare this:
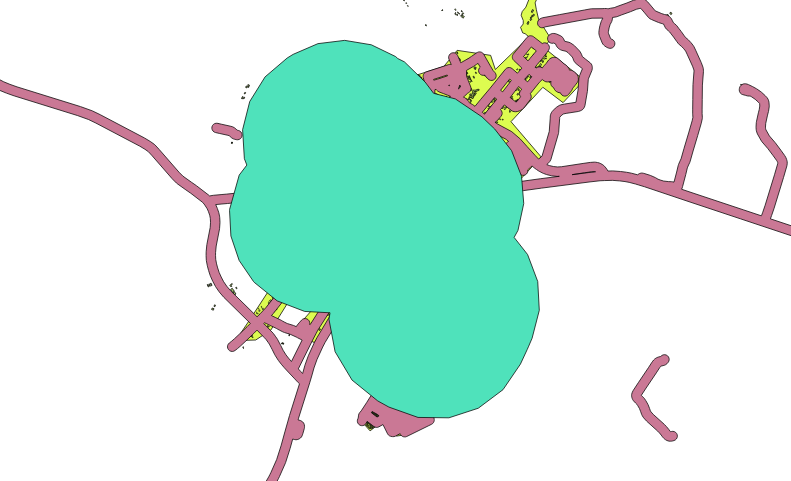
Com isso:
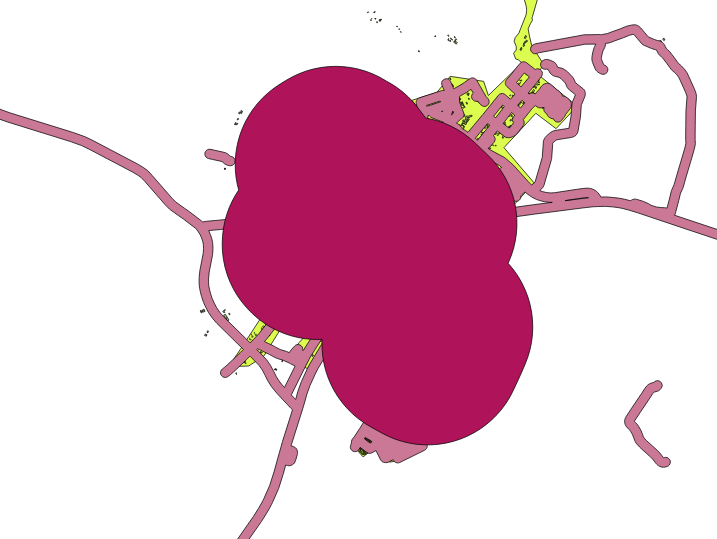
The first image shows the buffer with the Segments to approximate value set to 5 and the second shows the value set to 20. In our example, the difference is subtle, but you can see that the buffer’s edges are smoother with the higher value.
21.9.3. Distancia de restaurantes¶
To create the new houses_restaurants_500m layer, we go through a two step process:
Primero, crear un buffer de 500m alrededor de los restaurantes y agregar la capa al mapa:
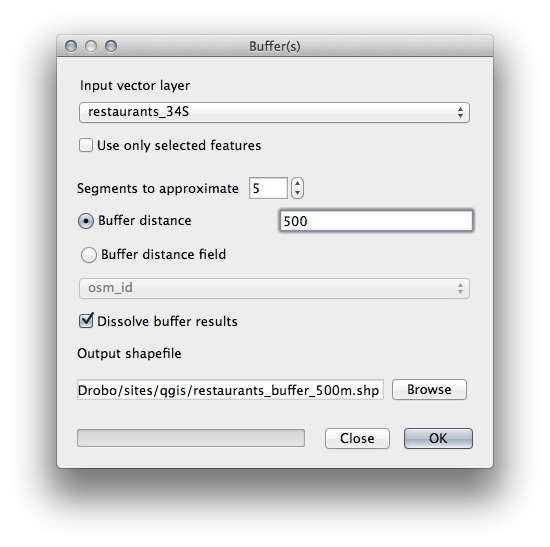
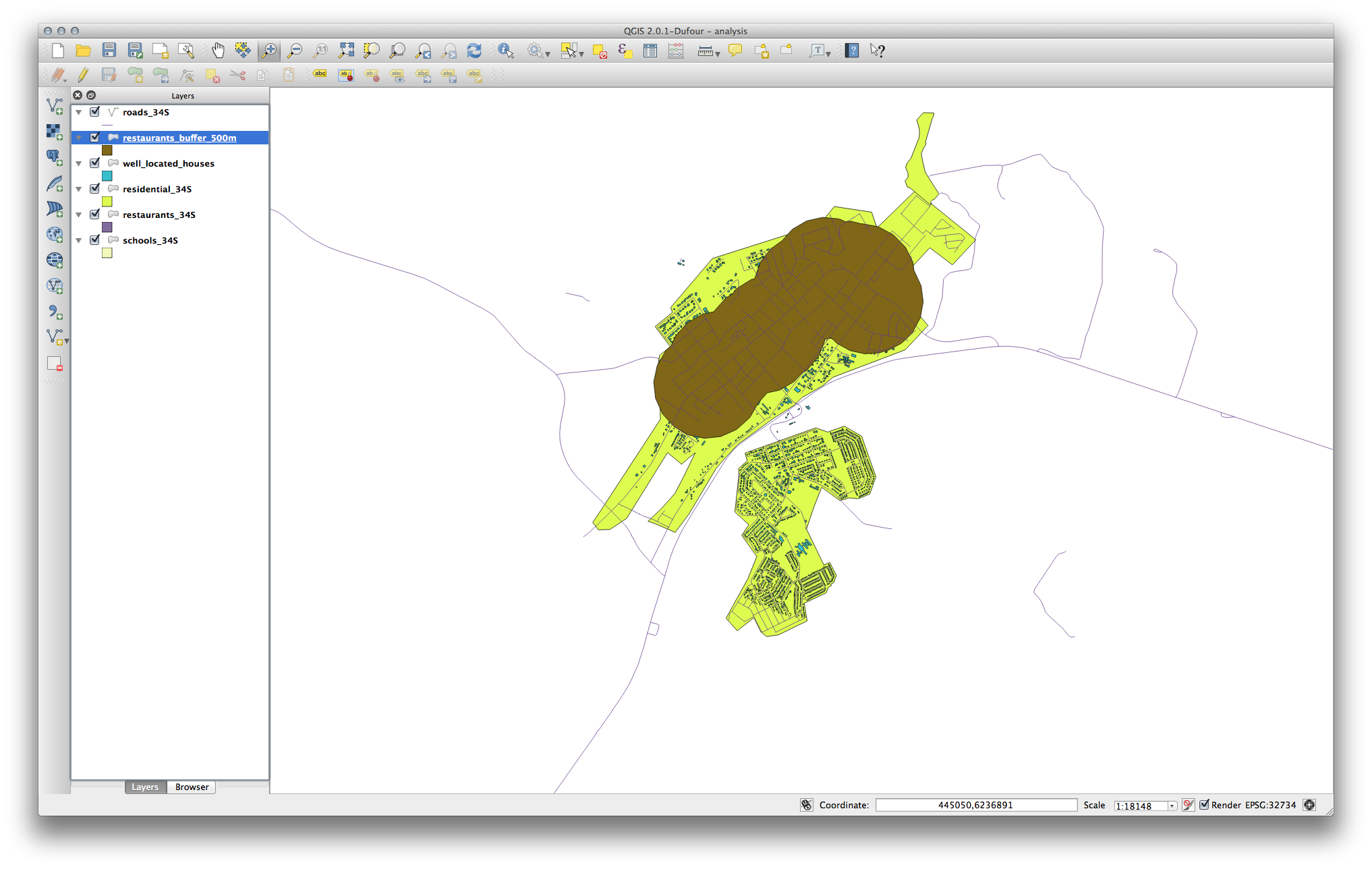
Next, select buildings within that buffer area:
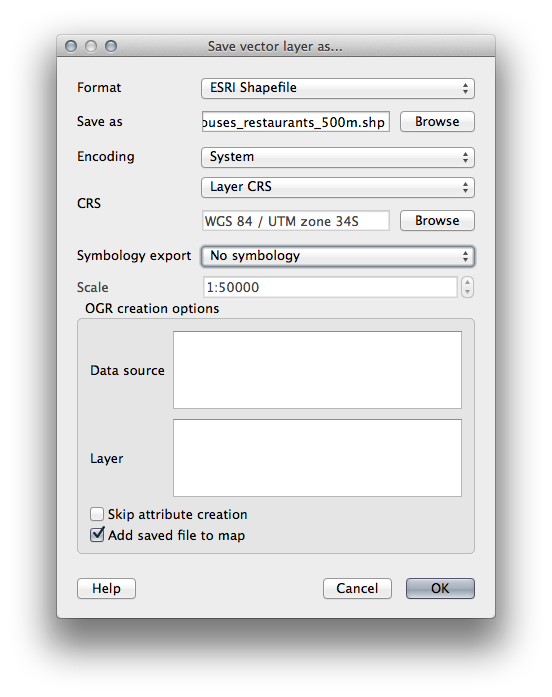
Now save that selection to our new houses_restaurants_500m layer:
Su mapa debe mostrar solo aquellos edificios que estén a menos de 50m de la carretera, 1 km de la escuela y 500m de un restaurante:

21.10. Results For Análisis Raster¶
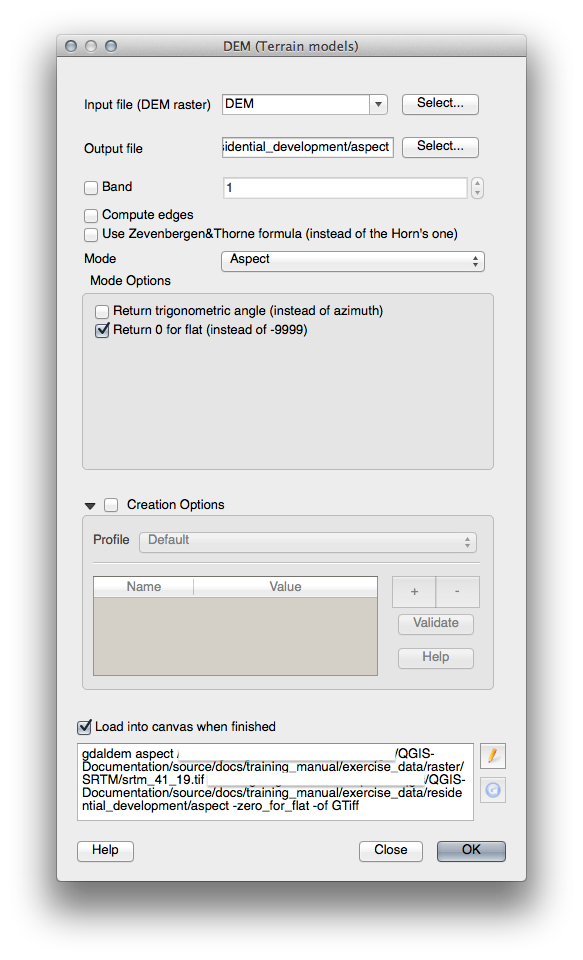

21.10.2. Calcular pendiente (menos de 2 y 5 grados)¶
Establezca su dialogo Calculadora Raster como esto:
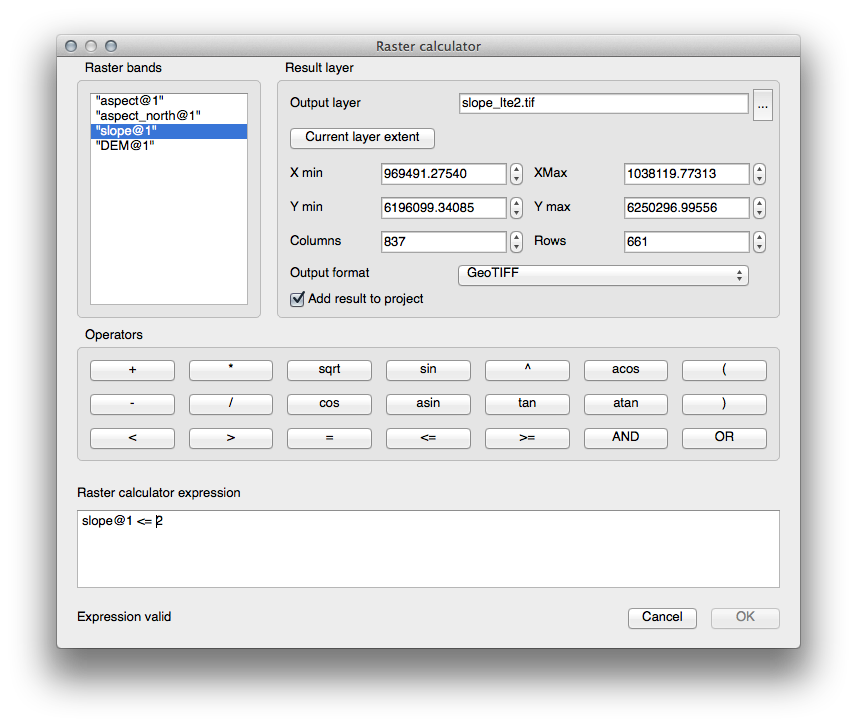
For the 5 degree version, replace the 2 in the expression and file name with 5.
Sus resultados:
2 grados:
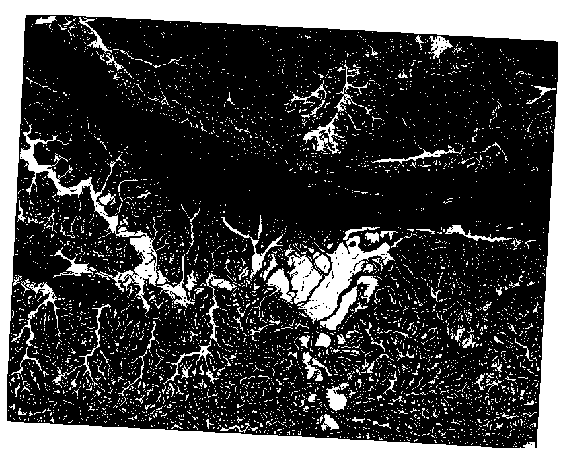
5 grados:

21.11. Results For Completando el Análisis¶
21.11.1. de Raster a Vector¶
- Open the Query Builder by right-clicking on the all_terrain layer in the Layers list, select the General tab.
Después construir la consulta "suitable" = 1.
Clic OK para filtrar todos los polígonos que no cumplan con esa condición.
Cuando vea el raster original, el área debe sobreponerse perfectamente:
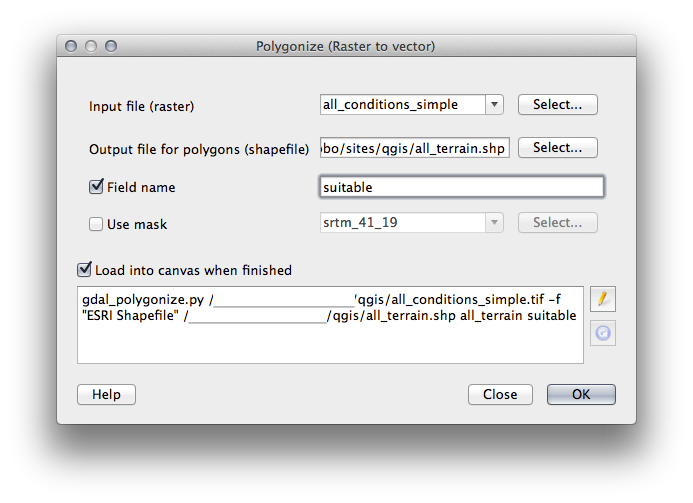
- You can save this layer by right-clicking on the all_terrain layer in the Layers list and choosing Save As..., then continue as per the instructions.
21.11.2. Revisando los resultados¶
Podrá notar que algunos de los edificios en su capa nueva_solución han sido “cortados” por la herramienta Intersectar. Esto muestra que sólo parte del edificio -y por lo tanto solamente parte de la propiedad- se ubica en un terreno adecuado. Podemos entonces con seguridad eliminar esos edificios de nuestro Conjunto de datos.
21.11.3. Afinando el Análisis¶
Por el momento, su análisis deberá verse más o menos así:
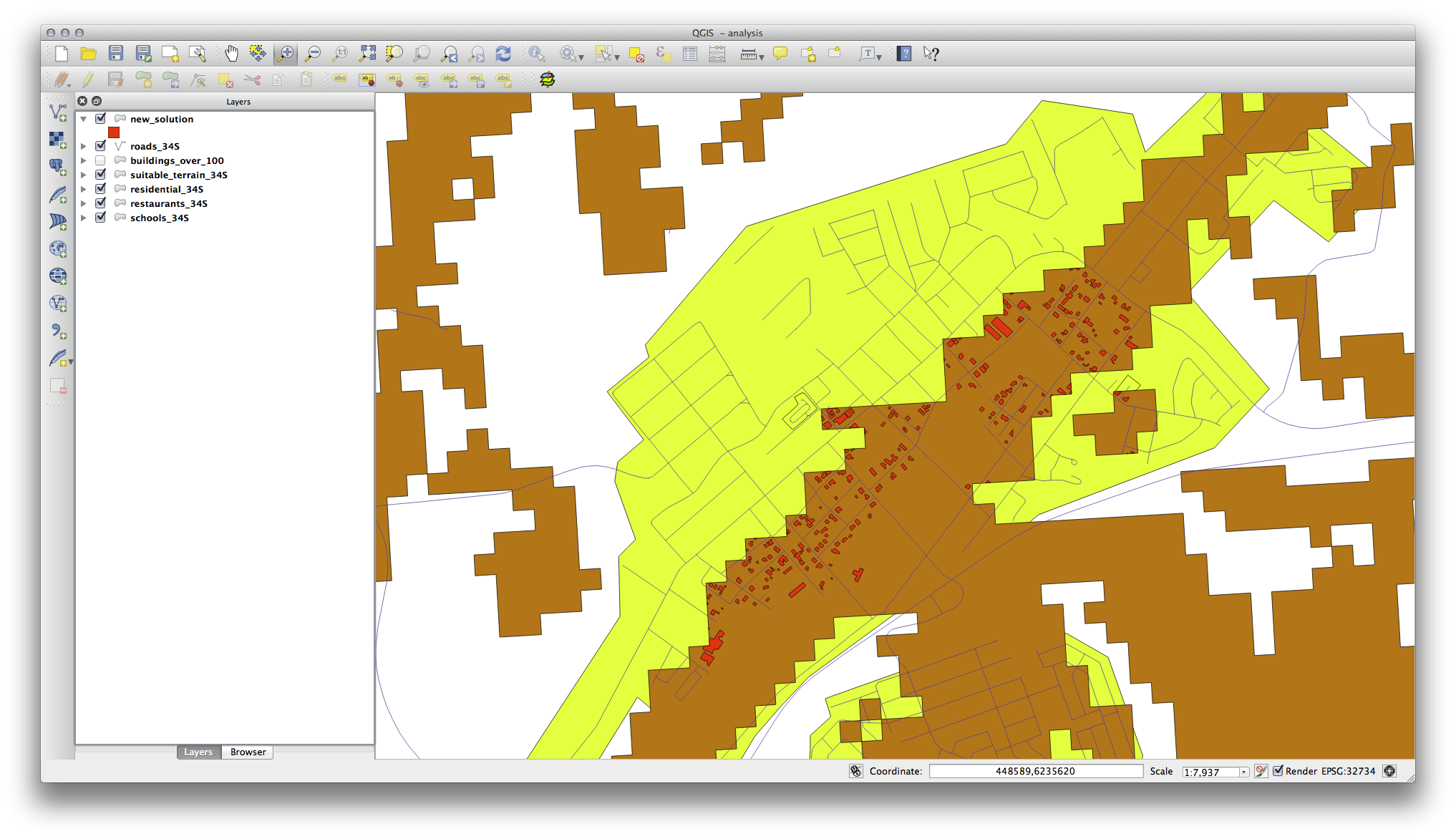
Considera un área circular, con 100 metros a la redonda

Si es más grande que 100 metros de radio, entonces extraer 100 metros de su tamaño (en todas las direcciones) resultará en que una parte de el quede sobrante en el medio.
Por lo tanto, puede ejecutar un buffer interior de 100 metros en su capa vectorial existente terreno_apto. En el resultado de la aplicación de la función buffer, lo que sea que quede en la capa original representará áreas en donde hay terreno apto más allá de los 100.
Para demostrar:
Ir a Vector ‣ Herramientas de Geoprocesamiento ‣ Buffer(s) para abrir el diálogo de Buffer(s).
Configúralo así:
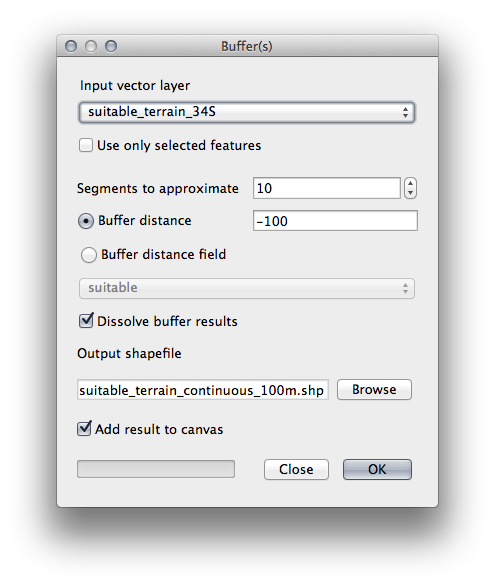
Use la capa terreno_apto con 10 segmentos y una distancia de buffer de -100. (La distancia es automáticamente reconocida en metros debido a que su mapa está usando un SRC proyectado).
Guarda la capa resultante en datos_ejercicio/desarrollo_residencial/ como terreno_apto_continuos100m.shp.
Si es necesario, mueva la nueva capa encima de su capa original terreno_apto.
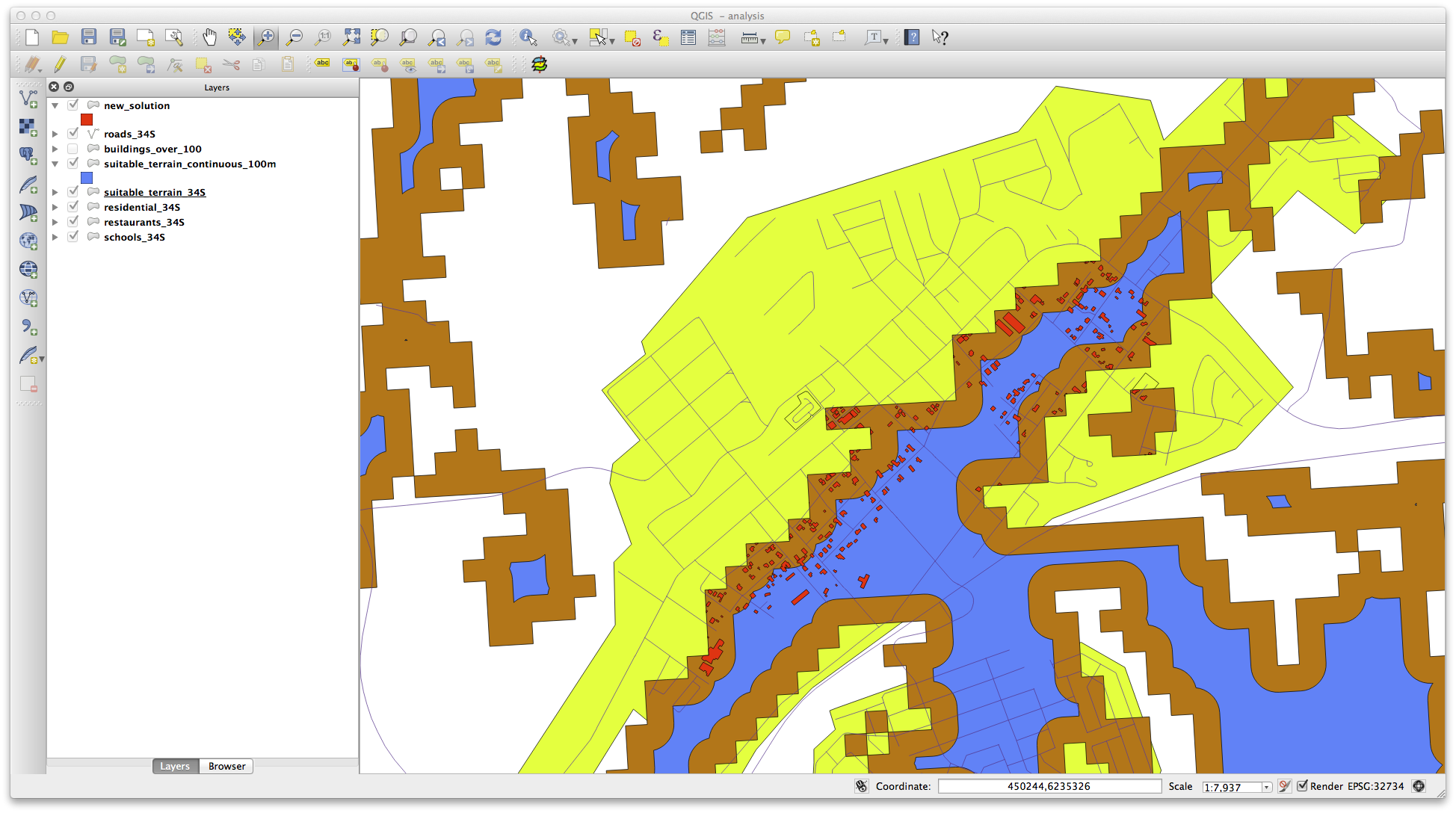
Sus resultados se verán más o menos así:
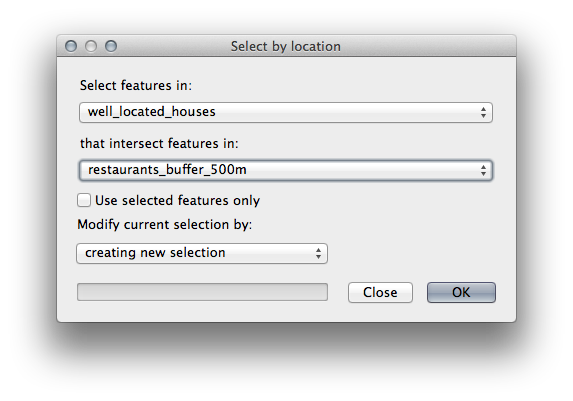
Ahora utilice la herramienta Selección por ubicación (Vector ‣ Herramientas de investigación ‣ Selección por ubicación).
Configurar de la siguiente manera:
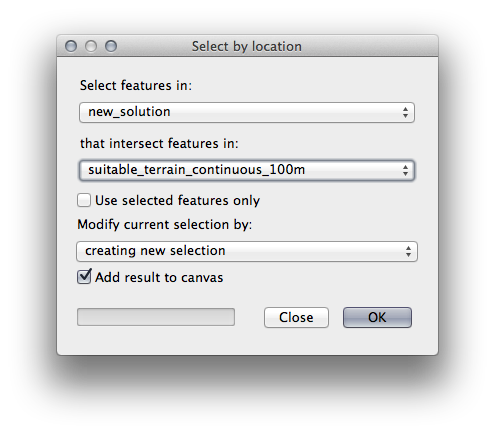
Seleccione elementos en nueva_solución que intersecte elementos de terreno_apto_continuos100m.shp.
Este es el resultado:

Los edificios en color amarillo están seleccionados. Aunque algunos de los edificios caen parcialmente afuera de la nueva capa terreno_apto_continuos100m.shp, caen bien dentro de la capa original terreno_apto y por lo tanto cumplen con todos nuestros requerimientos.
Guarde la selección en datos_ejercicio/desarrollo_residencial/ con el nombre respuesta_final.shp.
21.12. Results For WMS¶
21.12.1. Follow Along: Cargar otra Capa WMS¶
Su mapa debería verse así (puede que necesite re-ordenar las capas):
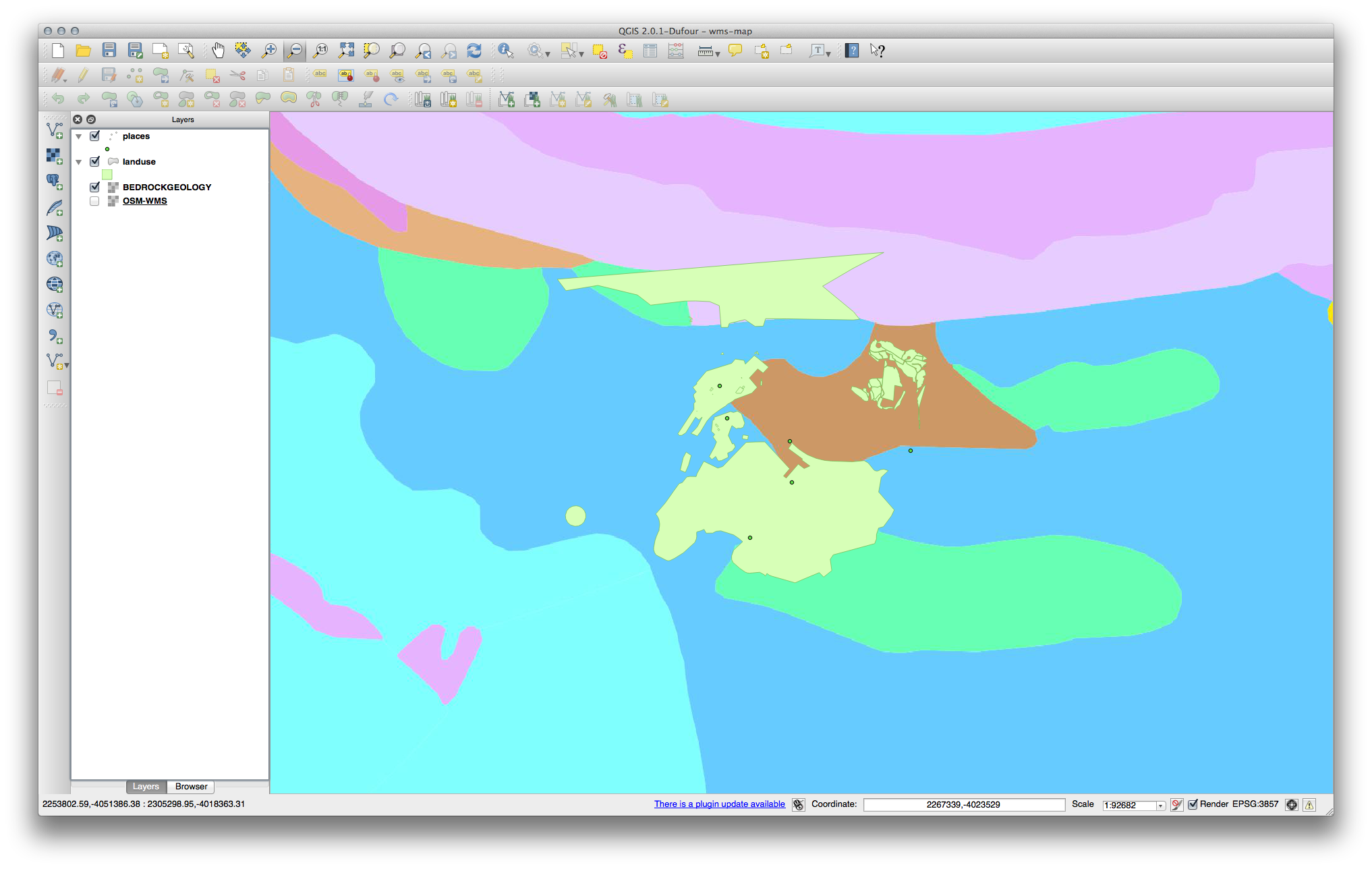
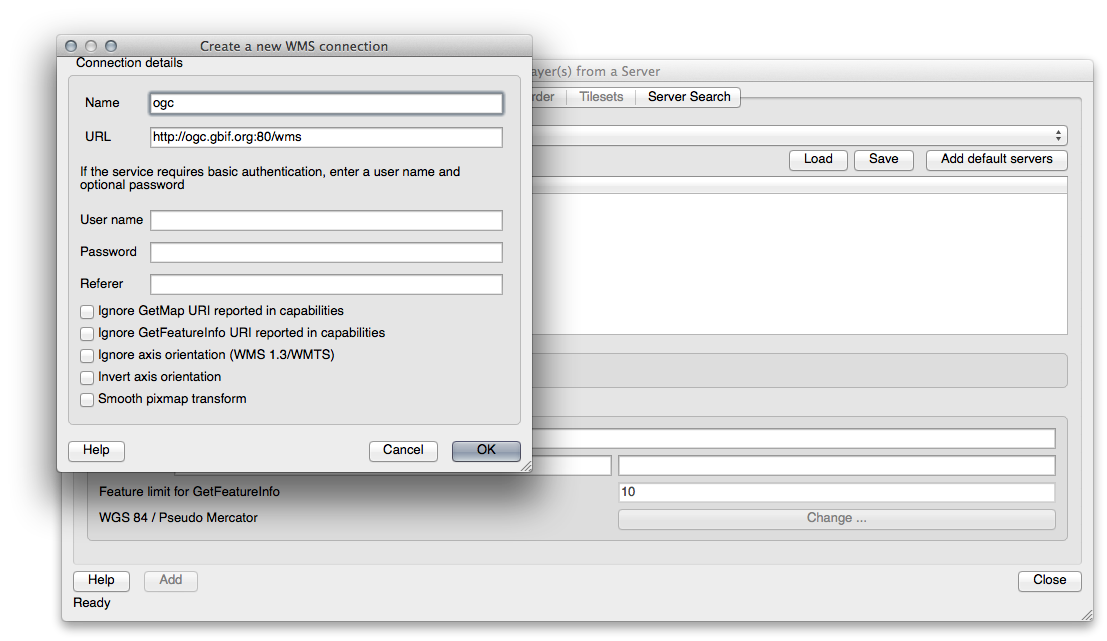
21.12.2. Agregando un Nuevo Servidor WMS¶
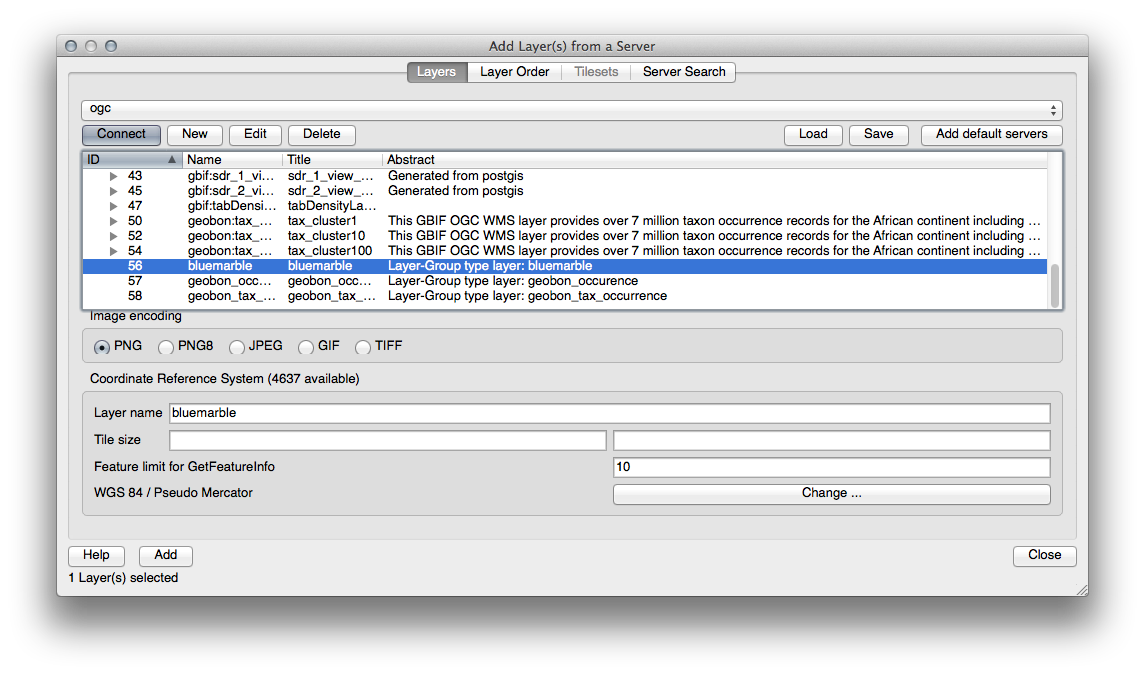
Utilice el mismo método que antes para agregar el nuevo servidor y la capa adecuada según como se encuentre alojada en el servidor:
Si realiza un acercamiento en el área Swellendam, notará que este conjunto de datos tiene una baja resolución.
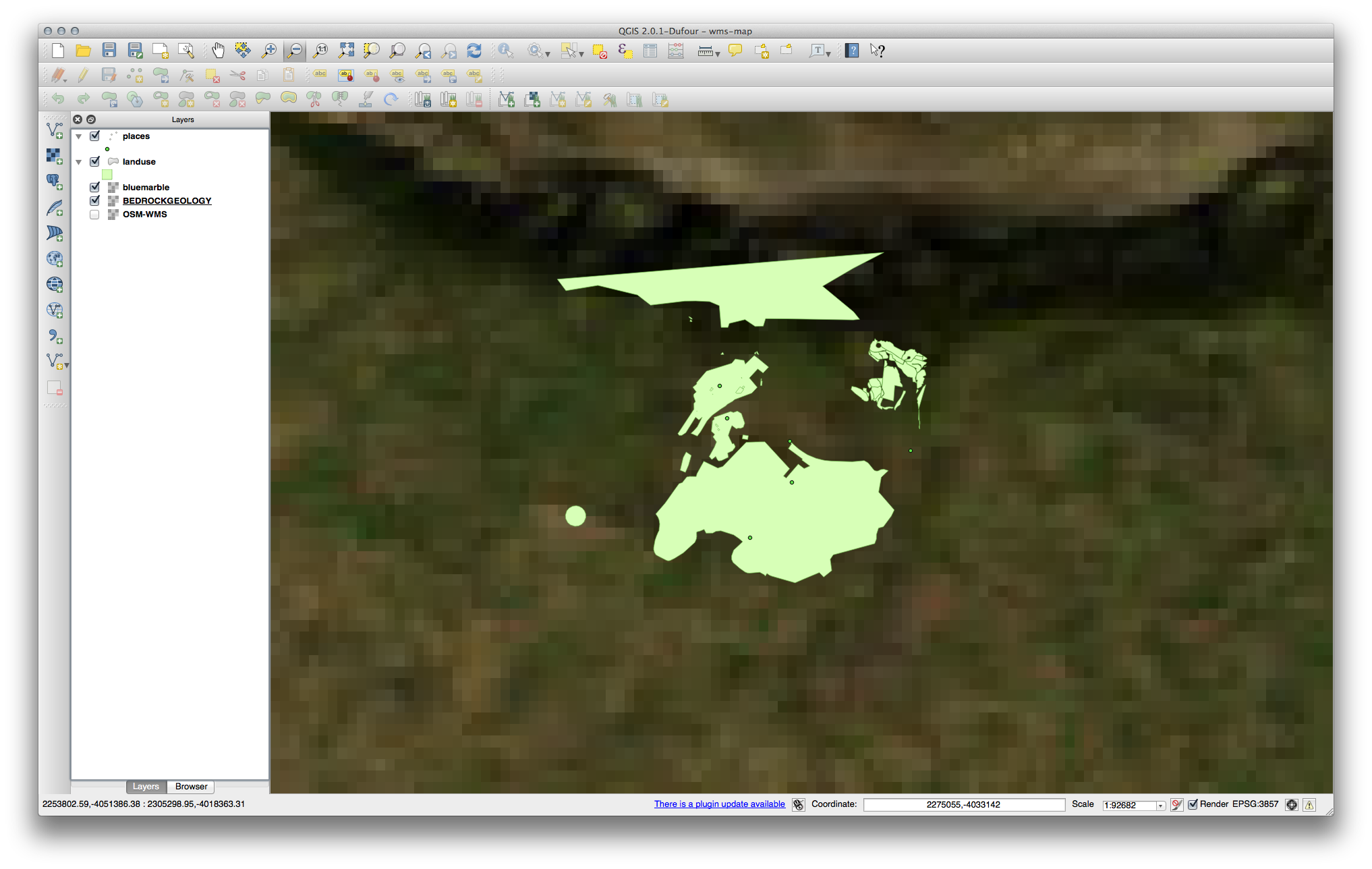
Por lo tanto, es mejor no usar este dato para el mapa actual. El dato de Blue Marble es más apropiado para las escalas nacionales y globales.
21.12.3. Agregando un Nuevo Servidor WMS¶
You may notice that many WMS servers are not always available. Sometimes this is temporary, sometimes it is permanent. An example of a WMS server that worked at the time of writing is the World Mineral Deposits WMS at http://apps1.gdr.nrcan.gc.ca/cgi-bin/worldmin_en-ca_ows. It does not require fees or have access constraints, and it is global. Therefore, it does satisfy the requirements. Keep in mind, however, that this is merely an example. There are many other WMS servers to choose from.
21.13. Results For Conceptos de Bases de Datos¶
21.13.1. Propiedades de la Tabla de Direcciones¶
Para nuestra tabla de direcciones teórica, podríamos querer almacenar las siguientes propiedades:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
Al crear la tabla para representar un objeto de dirección, crearemos columnas para representar cada una de estas propiedades y les estaríamos asignando nombres compatibles con SQL y posiblemente nombres cortos
house_number
street_name
suburb
city
postcode
country
21.13.2. Normalizando la Tabla de Personas¶
El mayor problema con la capa de gente es que hay solo un campo de dirección que contiene los datos de domicilio de las personas. Pensando en nuestra tabla teórica direccion anteriormente en esta lección, sabemos que una dirección esta compuesta por varias propiedades. Mediante el almacenamiento de todas estas propiedades en un solo campo, con esto haremos mucho mas difícil la actualización y la consulta de nuestros datos. Por lo tanto tenemos que dividir el campo de dirección en varias propiedades. Esto nos daría una tabla que tenga las siguiente estructura:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
Nota
En la siguiente sección, aprenderemos acerca de relaciones de llave foránea, que podrán ser usados en este ejemplo para mejorar aún más la estructura de nuestra base de datos.
21.13.3. Además normalización de la tabla de Personas¶
Actualmente nuestra tabla de personas se ve así:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
La columna street_id representa una relacion ‘uno a muchos’ entre el objeto personas y el objeto relacionado calle, que esta en la tabla de calles.
Una forma para normalizar aún más la tabla es dividir el nombre del campo en nombre y apellido:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
Podemos crear también tablas independientes para nombre pueblo o ciudad y país, enlazándolos a nuestra tabla de personas a través de una relación de ‘uno a muchos’:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
Un diagrama de ER para representar esto sería así:
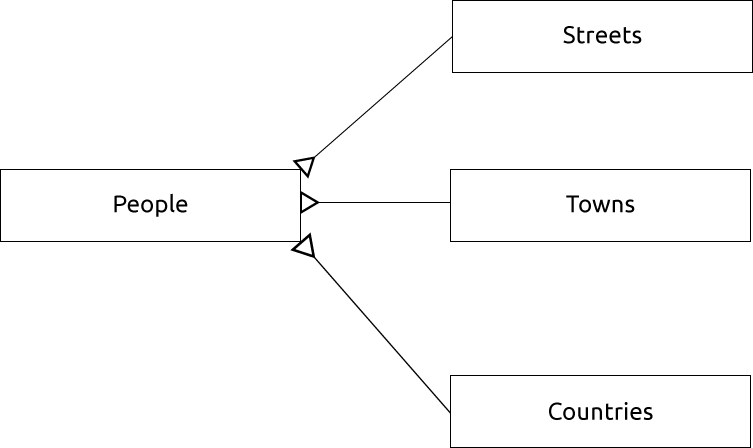
21.13.4. Crear una tabla de Personas¶
El SQL necesario para crear la tabla correcta de personas es:
create table people (id serial not null primary key,
name varchar(50),
house_no int not null,
street_id int not null,
phone_no varchar null );
O esquema para a tabela (digite \d people) será parecido com o seguinte:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Nota
Para fines de ilustración, hemos omitido a propósito la restricción del fkey.
21.13.5. El comando DROP¶
El motivo del comando DROP no funcionaría en este caso, porque la tabla personas tiene un restricción de llave foránea para la tabla calles. Esto significa que dropping (o eliminar) la tabla de calles dejaría a la tabla de personas con las referencias a calles de datos no existentes.
Nota
Es posible para ‘fuerza’ la tabla de calles para ser eliminado mediante el uso del comando CASCADE, pero también se eliminaría la tabla de personas y alguna otra que tenga relación con la tabla calles. ¡Utilizar con precaución!
21.13.6. Insertar una nueva calle¶
El comando SQL, que debe usar se ve así (puede reemplazar el nombre de la calle con uno de su elección):
insert into streets (name) values ('Low Road');
21.13.7. Agregar una nueva persona con relación de llave foránea¶
Aquí esta la sentencia SQL correcta:
insert into streets (name) values('Main Road');
insert into people (name,house_no, street_id, phone_no)
values ('Joe Smith',55,2,'072 882 33 21');
Si se fija en la tabla de calles nuevamente (utilizando una sentencia select como antes), vera que el id de la entidad Carretera Principal es 2.
Eso es por qué podríamos solo introducir el numero 2 arriba. Aunque no estemos viendo Carretera principal escrito completamente en la entrada de arriba, la base de datos podrá estar asociada a street_id con el valor de 2.
Nota
Se você já adicionou um novo objeto Estrada, você pode achar que o novo Estrada Principal tem o ID 3 não 2.
21.13.8. Regresar Nombre de calles¶
Aquí esta la sentencia SQL correcta que debe usar:
select count(people.name), streets.name
from people, streets
where people.street_id=streets.id
group by streets.name;
Resultado:
count | name
------+-------------
1 | Low Street
2 | High street
1 | Main Road
(3 rows)
Nota
Você vai notar que temos prefixado nomes dos campos com nomes de tabela (por exemplo pessoas.name e streets.name). Isso precisa ser feito sempre que o nome do campo (ou seja, não exclusivo em todas as tabelas no banco de dados) for ambíguo.
21.14. Results For Consultas Espaciales¶
21.14.1. Las unidades usadas en Consultas Espaciales¶
Las unidades usadas para el ejemplo de consulta son grados, porque el SRC que la capa esta usando es WGS84. Este es un SRC Geografico, que significa que las unidades están en grados. Un proyecto SRC, como la proyección UTM que esta en metros.
Recuerde que cuando escriba la consulta, necesita saber en que unidades esta el SRC de la capa. Esto te permitirá escribir una consulta que regrese los resultados que tu esperas.
21.14.2. Creando un índice espacial¶
CREATE INDEX cities_geo_idx
ON cities
USING gist (the_geom);
21.15. Results For Construcion de geometría¶
21.15.1. Creando linestrings¶
alter table streets add column the_geom geometry;
alter table streets add constraint streets_geom_point_chk check
(st_geometrytype(the_geom) = 'ST_LineString'::text OR the_geom IS NULL);
insert into geometry_columns values ('','public','streets','the_geom',2,4326,
'LINESTRING');
create index streets_geo_idx
on streets
using gist
(the_geom);
21.15.2. “Enlazando tablas”¶
delete from people;
alter table people add column city_id int not null references cities(id);
(capturar ciudades en QGIS)
insert into people (name,house_no, street_id, phone_no, city_id, the_geom)
values ('Faulty Towers',
34,
3,
'072 812 31 28',
1,
'SRID=4326;POINT(33 33)');
insert into people (name,house_no, street_id, phone_no, city_id, the_geom)
values ('IP Knightly',
32,
1,
'071 812 31 28',
1,F
'SRID=4326;POINT(32 -34)');
insert into people (name,house_no, street_id, phone_no, city_id, the_geom)
values ('Rusty Bedsprings',
39,
1,
'071 822 31 28',
1,
'SRID=4326;POINT(34 -34)');
Si recibe el siguiente mensaje de error:
ERROR: insert or update on table "people" violates foreign key constraint
"people_city_id_fkey"
DETAIL: Key (city_id)=(1) is not present in table "cities".
entonces significa que mientras experimentaba con la creación de polígonos para la tabla de ciudades, debe haber eliminado algunos de ellos y empezar de nuevo. Vea las entradas de su tabla de ciudades y use cualquier id que exista.
21.16. Results For Modelo de características simples¶
21.16.1. Llenar tablas¶
create table cities (id serial not null primary key,
name varchar(50),
the_geom geometry not null);
alter table cities
add constraint cities_geom_point_chk
check (st_geometrytype(the_geom) = 'ST_Polygon'::text );
21.16.2. Llenar la tabla Geometria_Columnas¶
insert into geometry_columns values
('','public','cities','the_geom',2,4326,'POLYGON');
21.16.3. Agregar geometría¶
select people.name,
streets.name as street_name,
st_astext(people.the_geom) as geometry
from streets, people
where people.street_id=streets.id;
Resultado:
name | street_name | geometry
--------------+-------------+---------------
Roger Jones | High street |
Sally Norman | High street |
Jane Smith | Main Road |
Joe Bloggs | Low Street |
Fault Towers | Main Road | POINT(33 -33)
(5 rows)
Como puede ver, nuestra limitación permite agregar nulos en la base de datos.