Importante
La traducción es un esfuerzo comunitario puede unirse. Esta página está actualmente traducida en |progreso de traducción|.
17.10. La calculadora ráster. Valores sin datos
Nota
En esta lección, veremos cómo utilizar la calculadora ráster para realizar algunas operaciones en capas ráster. También explicaremos que son valores sin datos y cómo la calculadora y otros algoritmos tratan con ellos
La calculadora ráster es una de los algoritmos más poderosos que encontrará. Es un algoritmo muy flexible y versátil que se puede utilizar para muchos cálculos diferentes y que pronto se convertirá en una parte importante de tu caja de herramientas.
En esta lección, vamos a realizar algunos cálculos con la calculadora ráster, la mayoría de ellas bastante simples. Esto nos permitirá ver cómo se utilizan y cómo tratar con algunas situaciones particulares que podríamos encontrar. Entender que es importante para después obtener el resultado esperado al utilizar la calculadora, y también entender ciertas técnicas que se aplicada comúnmente con él.
Abra el proyecto QGIS correspondiente para la lección y verá que contiene varias capas ráster.
Ahora abra la caja de texto y abra el diálogo correspondiente para la calculadora ráster.
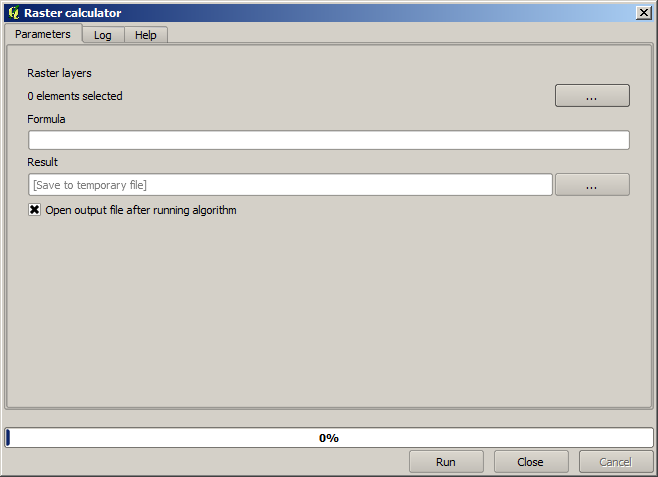
Nota
La interfaz es diferente en versiones recientes.
El diálogo contiene 2 parámetros.
Las capas a utilizar para el análisis. Esta es una entrada múltiple que significa que se pueden seleccionar tantas capas como desee. Haga clic sobre el botón del lado derecho y seleccione las capas que desee utilizar en el diálogo que aparecerá.
La formula a aplicar. La formula utiliza las capas seleccionadas en el parámetro anterior, las cuales se nombran utilizando las letras del alfabeto (
a, b, c...) og1, g2, g3...como nombre de variables. Es decir, la formulaa + 2 * bes la misma queg1 + 2 * g2y calcular la suma del valor en la primera capa más dos veces el valor de la segunda capa. El orden de las capas es el mismo orden que se ve en el cuadro de diálogo de selección.
Advertencia
La calculadora es sensible a mayúsculas.
Para empezar, cambiemos las unidades del MDT de metros a pies. La formula que necesitamos es la siguiente:
h' = h * 3.28084
Seleccione el MDT en el campo de capas y escriba en el campo de formula a * 3.28084.
Advertencia
Para los usuarios no ingleses: utilice siempre «.», not «,».
Haga clic en Ejecutar para ejecutar el algoritmo. Se obtendrá una capa que tiene la misma apariencia de la capa de entrada, pero con valores diferentes. La capa de entrada que nosotros utilizamos tiene valores validos en todas sus celdas, por lo que el último parámetro no tiene efecto en absoluto.
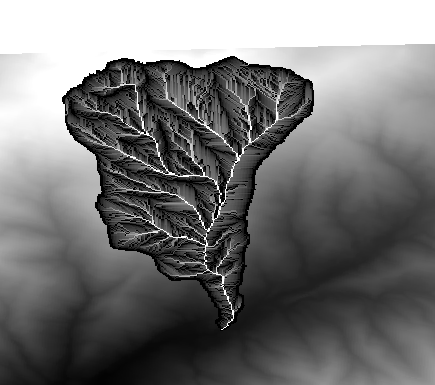
Ahora vamos a realizar otro calculo, esta vez sobre la capa accflow. Esta capa contiene valores de flujo acumulado, un parámetro hidrológico. Contienen esos valores sólo dentro de la zona de una determinada cuenta, con valores de no datos fuera de él. Como se puede ver, la presentación no es muy informativa, debido a la forma en que los valores son distribuidos. Utilice el algoritmo de acumulación de flujo dará lugar a una representación mucho más informativa. Podemos calcular eso utilizando la calculadora ráster.
Abra el diálogo del algoritmo de nuevo, seleccione la capa accflow como la única capa de entrada, e introduzca la siguiente formula: log(a).
Aquí esta la capa que se obtendrá.
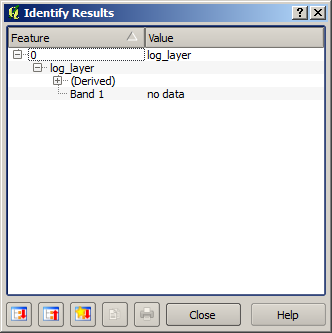
Si se selecciona la herramienta Identificar objetos espaciales para conocer el valor de una capa en un punto dado, seleccione la capa que acabamos de crear, y haga clic en un punto fuera de la cuenca, verá que contiene un no - valor de datos.
Para el siguiente ejercicio vamos a utilizar dos capas en lugar de una, y vamos a obtener un MDT con valores de elevación validos sólo dentro de la cuenca definida en la segunda capa. Abra el diálogo de la calculadora y seleccione ambas capas del proyecto en el campo de capas de entrada. Introduzca la siguiente formula en el campo correspondiente:
a/a * b
a se refiere a la capa de flujo acumulado (ya que es el primero en aparecer en la lista) y b se refiere al MDT. Lo que estamos haciendo en la primera parte de la formula aquí es dividir la capa de flujo acumulado por si mismo, lo que resultará en un valor de 1 dentro de la cuenca, y un no - valor de dato fuera. Luego multiplicamos por el MDT, para obtener el valor de la elevación en esas celdas dentro de la cuenca (DEM * 1 = DEM) y sin dato fuera (DEM * no_data = no_data)
Aquí esta la capa resultante.

Esta técnica se utiliza con frecuencia para los valores de mascara en una capa ráster, y es útil cuando desea realizar cálculos para una región distinta a la región rectangular arbitraria que es utilizado por capa ráster. Por ejemplo, un histograma de elevación de una capa ráster no tiene mucho significado. Si en su lugar se calcula utilizando sólo los valores correspondientes a una cuenca (como en él caso anterior), el resultado que se obtiene es una significativa que en realidad le da información sobre la configuración de la cuenca.
There are other interesting things about this algorithm that we have just run, apart from the no–data values and how they are handled. If you have a look at the extents of the layers that we have multiplied (you can do it double-clicking on the names of the layers in the table of contents and looking at the properties), you will see that they are not the same, since the extent covered by the flow accumulation layer is smaller that the extent of the full DEM.
Eso significa que las capas no coinciden, y que no se pueden multiplicar directamente sin necesidad de homogeneizar los tamaños y extensión volviendo a muestrear una o ambas capas. Sin embargo, no hemos hecho nada. QGIS se hizo cargo de esta situación y automáticamente vuelve a muestrear las capas de entrada cuando sea necesario. La extensión de salida es la extensión de cobertura mínima calculada a partir de las capas de entrada, y el tamaño de célula mínimo de sus tamaños de celdas.
En este caso (y en la mayoría), esto produce el resultado deseado, pero siempre debe estar al tanto de las operaciones adicionales que se están produciendo, ya que podrían afectar el resultado. En los casos en que no esté disponible el funcionamiento podría no ser el deseado, remuestreo manual debe ser aplicado con antelación. En capítulos posteriores, veremos más sobre el comportamiento de los algoritmos cuando se utilizan múltiples capas ráster.
Vamos a terminar esta lección con otro ejercicio de enmascaramiento. Vamos a calcular la pendiente en todas las zonas con una elevación entre 1000 y 1500 metros.
En este caso, no tenemos una capa para utilizar como máscara, pero podemos crearla utilizando la calculadora.
Ejecute la calculadora utilizando el MDT como única capa de entrada y la siguiente fórmula.
ifelse(abs(a-1250) < 250, 1, 0/0)
Como puede ver, podemos utilizar la calculadora no sólo para hacer operaciones algebraicas sencillas, si no también para ejecutar un cálculo más complejo que involucre las sentencias condicionales, como la anterior.
El resultado fue un valor de 1 dentro del rango con el que deseamos trabajar, y sin datos en celdas fuera de él.

Los valores sin datos vienen de la expresión 0/0. Dado que es un valor indeterminado, SAGA añadirá un valor NaN (No es un número), que en realidad es manejado como un valor sin datos. Con este pequeño truco se puede establecer un valor sin dato sin necesidad de conocer que valor sin dato es de la celda.
Ahora sólo hay que multiplicarlo por la capa de pendiente que se incluyó en el proyecto, y se obtendrá el resultado esperado.
Todo eso se puede hacer en una operación sencilla con la calculadora. Dejamos como ejercicio para el lector.