중요
번역은 여러분이 참여할 수 있는 커뮤니티 활동입니다. 이 페이지는 현재 96.06% 번역되었습니다.
6.4. 수업: 공간 통계
참고
이 수업은 Linfiniti와 (남아프리카공화국 케이프 페닌슐라 기술대학교의) 시디크 모탈라(Siddique Motala)가 기고했습니다.
공간 통계는 여러분이 지정한 벡터 데이터셋에서 어떤 일이 일어나고 있는지 분석하고 이해할 수 있게 해줍니다. QGIS는 공간 통계를 위한 유용한 도구들을 많이 가지고 있습니다.
이 수업의 목표: Processing Toolbox 에 있는 QGIS의 공간 통계 도구들을 사용하는 방법을 이해하기.
6.4.1. ★☆☆ 따라해보세요: 테스트 데이터셋 생성하기
작업할 데이터셋을 얻기 위해 랜덤한 포인트들의 집합을 생성할 것입니다.
이를 위해, 그 안에 포인트들을 생성하고자 하는 영역을 정의하는 폴리곤 데이터셋이 필요할 것입니다.
도로들이 커버하는 영역을 사용하겠습니다.
새 프로젝트를 시작하십시오.
roads데이터셋은 물론,exercise_data/raster/SRTM/폴더에 있는srtm_41_19(표고 데이터)도 추가하십시오.참고
STRM DEM 레이어의 좌표계가
roads레이어의 좌표계와 다를 수도 있습니다. QGIS가 두 레이어를 단일 좌표계로 재투영하고 있는 겁니다. 다음 예제들에서는 이런 차이가 문제되지는 않지만, (이전 강의에서 배운대로) 재투영하고 싶다면 마음대로 하십시오.Processing 툴박스를 여십시오.
도구를 사용, Geometry Type 을
Convex Hull로 선택해서 모든 도로가 감싸고 있는 영역을 생성하십시오.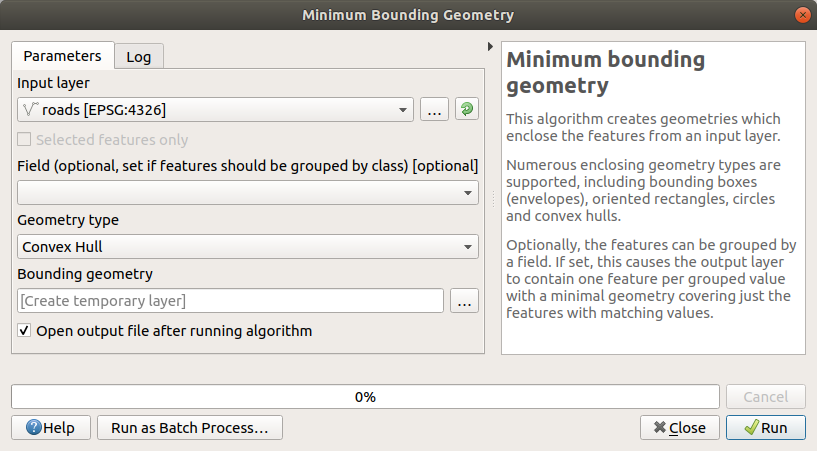
여러분도 알고 있듯이, 산출물을 지정하지 않는 경우 공간 처리(Processing) 프레임워크는 임시 레이어를 생성합니다. 레이어를 즉시 또는 나중에 저장할지는 여러분의 선택입니다.
랜덤한 포인트 생성하기
도구를 사용, 최단 거리를
0.0으로 설정해서 이 영역에 랜덤한 포인트들을 100개 생성하십시오: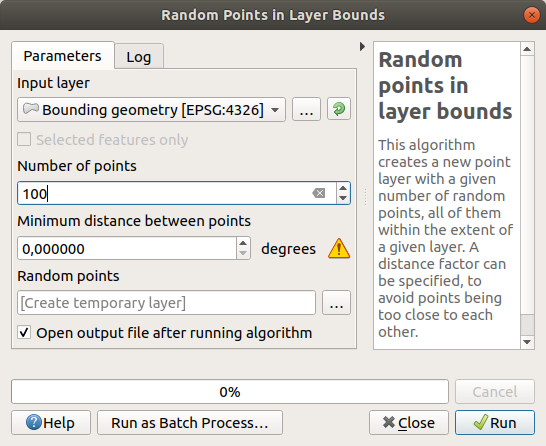
참고
노란색 경고 표시는 해당 파라미터가 거리와 관련이 있다는 것을 나타냅니다. 이 알고리즘이
Bounding geometry레이어가 지리 좌표계를 사용하고 있다는 사실을 상기시켜주는 것입니다. 이 예제의 경우 이 파라미터를 사용하지 않을 것이기 때문에 무시해도 괜찮습니다.
필요한 경우, 생성한 랜덤 포인트들을 범례 최상단으로 옮겨서 더 잘 보이게 하십시오:
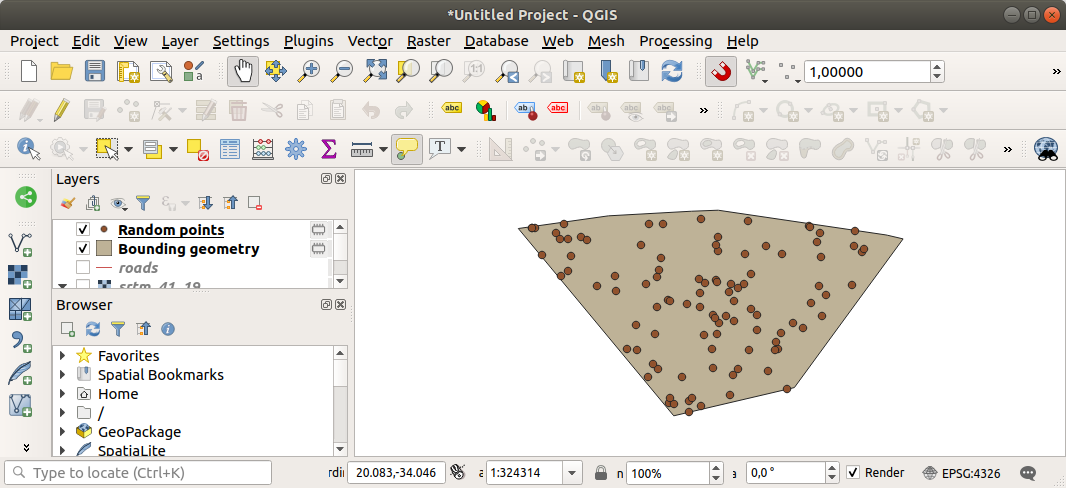
데이터 샘플링하기
래스터로부터 샘플 데이터셋을 생성하려면, 알고르짐을 사용해야 할 것입니다. 이 도구는 포인트 위치에서 래스터를 샘플링해서 래스터가 보유한 밴드 개수에 따라 새 필드(들)에 래스터 값들을 추가합니다.
Sample raster values 알고리즘 대화창을 여십시오.
Random_points를 샘플링 포인트들을 담고 있는 레이어로 선택하고, SRTM 레이어를 값을 가져올 밴드로 선택하십시오. 새 필드의 기본 이름은rvalue_N으로, 이때N이 래스터 밴드의 번호입니다. 원하는 경우 그 앞의 접두어를 변경해도 됩니다.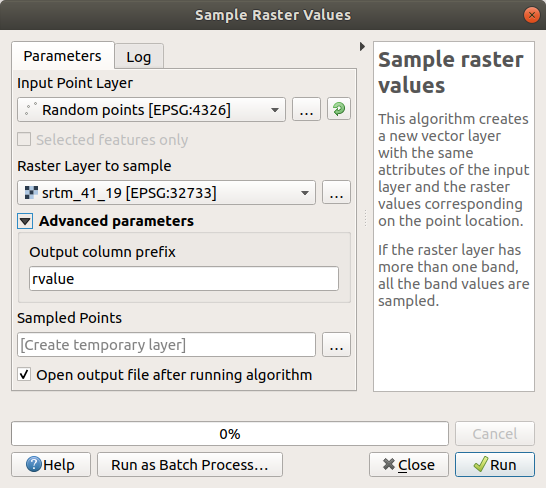
Run 버튼을 누르십시오.
이제 Sampled Points 레이어의 속성 테이블에서 래스터 파일에서 나온 샘플링된 데이터를 확인할 수 있습니다. 이 데이터는 여러분이 선택한 이름을 가진 새 필드에 있을 것입니다.
다음과 비슷한 샘플 레이어가 보일 겁니다:
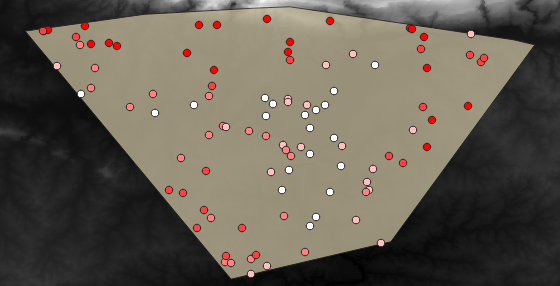
이 샘플 포인트들은 고도가 높을수록 빨간색이 진해지도록 rvalue_1 필드를 사용해서 범주화되었습니다.
나머지 통계 예제들에 이 샘플 레이어를 사용하게 될 것입니다.
6.4.2. ★☆☆ 따라해보세요: 기본 통계
이제 이 레이어에 대한 기본적인 통계를 내보겠습니다.
Attributes Toolbar 에 있는
 Show statistical summary 아이콘을 클릭하십시오. 새 패널이 열릴 것입니다.
Show statistical summary 아이콘을 클릭하십시오. 새 패널이 열릴 것입니다.나타난 대화창에서,
Sampled Points레이어를 소스로 지정하십시오.필드 콤보박스에서
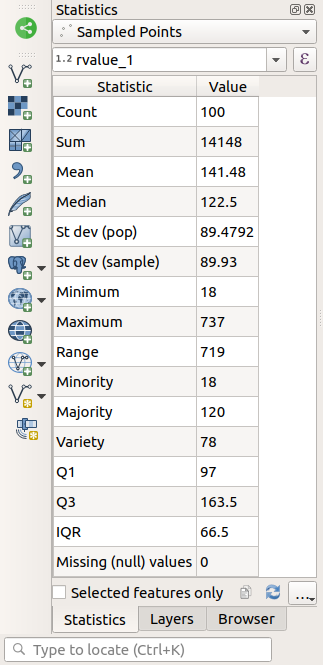
rvalue_1필드를 선택하십시오. 여러분은 이 필드에 대한 통계를 계산하게 될 것입니다.Statistics 패널이 계산된 통계로 자동 업데이트될 것입니다:
참고
 Copy Statistics To Clipboard 버튼을 클릭하면 값들을 복사해서, 통계 결과를 스프레드시트로 붙여넣을 수 있습니다.
Copy Statistics To Clipboard 버튼을 클릭하면 값들을 복사해서, 통계 결과를 스프레드시트로 붙여넣을 수 있습니다.작업이 종료되었으면 Statistics 패널을 닫으십시오.
다음과 같은 많은 통계를 낼 수 있습니다:
- 개수
샘플/값의 개수입니다.
- 합계
값들을 모두 더한 값입니다.
- 평균
평균값은 그저 값들의 합을 값들의 개수로 나눈 값입니다.
- 중앙값(median)
모든 값들을 최소에서 최대로 나열했을 때, 그 중앙에 있는 (또는 값들의 개수가 짝수인 경우 중앙에 있는 두 값의 평균) 값을 값들의 중앙값이라 합니다.
- 표준 편차 (모집단)
표준 편차입니다. 값들이 얼마나 중앙값에 가까이 모여 있는지를 나타냅니다. 표준 편차가 작을수록 값들이 중앙값에 더 가까이 모이는 경향이 있습니다.
- 최소값(minimum)
가장 작은 값입니다.
- 최대값(maximun)
가장 큰 값입니다.
- 범위
최소값과 최대값의 차입니다.
- Q1
데이터의 제1 사분위수(quartile)입니다.
- Q3
데이터의 제3 사분위수(quartile)입니다.
- 누락 (NULL) 값
누락된 값들의 개수입니다.
6.4.3. ★☆☆ 따라해보세요: 포인트들 사이의 거리에 대한 통계 계산하기
새 임시 포인트 레이어를 생성하십시오.
편집 모드로 들어가서, 다른 포인트들 사이 어딘가에 포인트를 3개 디지타이즈하십시오.
아니면, 이전과 마찬가지로 랜덤 포인트 생성 방법을 사용하지만 이번에는 포인트를 3개 만 지정하십시오.
Save your new layer as
distance_pointsin the format you prefer.
두 레이어에 있는 포인트들 사이의 거리에 대한 통계를 생성하려면:
도구를 여십시오.
입력 레이어를
distance_points레이어로, 대상 레이어를Sampled Points레이어로 선택하십시오.레이어들의
id필드를 유일한 필드 참조(unique field reference)로 설정하십시오.Output matrix type 옵션을 Summary distance matrix 로 변경하십시오.
Use only the nearest (k) target points 의 값을
2로 설정하십시오.원하는 경우 산출 레이어를 파일로 저장할 수도 있고, 또는 그냥 알고리즘을 실행한 다음 나중에 임시 산출 레이어를 저장할 수도 있습니다.
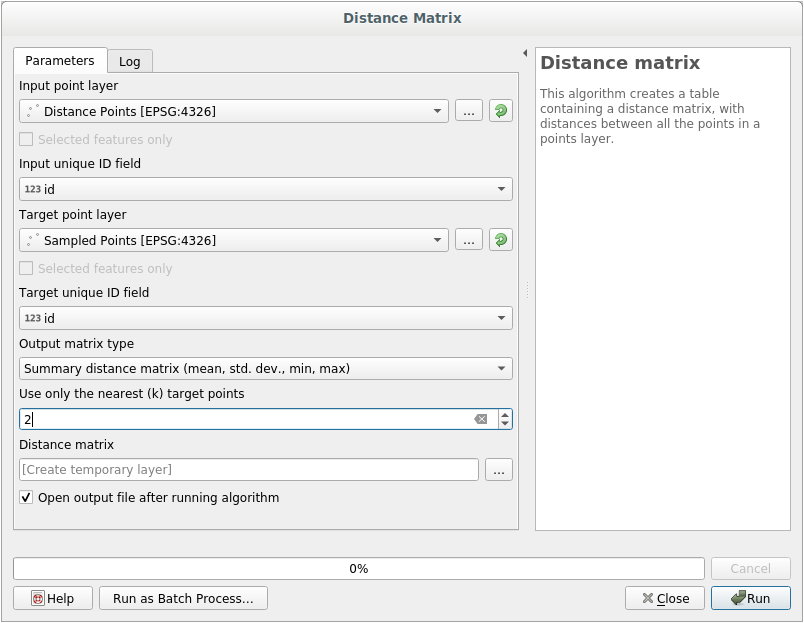
Run 을 클릭해서 거리 행렬 레이어를 생성하십시오.
Open the attribute table of the generated layer: values refer to the distances between the
distance_pointsfeatures and their two nearest points in theSampled Pointslayer: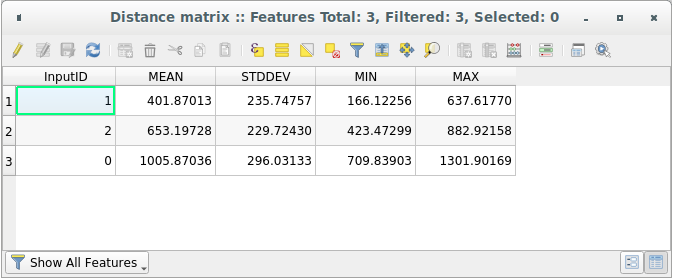
거리 행렬(Distance Matrix) 도구는 이 파라미터들을 사용해서 대상 레이어의 최근접 포인트 2개를 기준으로 입력 레이어의 각 포인트에 대한 거리 통계를 계산합니다. 산출 레이어의 필드들은 계산된 거리에 대한 평균, 표준 편차, 최소값 및 최대값을 담고 있습니다.
심화 테스트를 해보려면, Output matrix type 옵션 또는 대상 포인트 개수를 수정해보세요.
6.4.4. ★☆☆ 따라해보세요: 최근접 이웃 분석 (레이어 내부)
포인트 레이어 하나의 최근접 이웃 분석을 하려면:
도구를 선택하십시오.
In the dialog that appears, select the
Random pointslayer and click Run.결과물이 공간 처리 Result Viewer 패널에 나타날 것입니다.
파란색 링크를 클릭해서 결과물이 담긴
html페이지를 여십시오: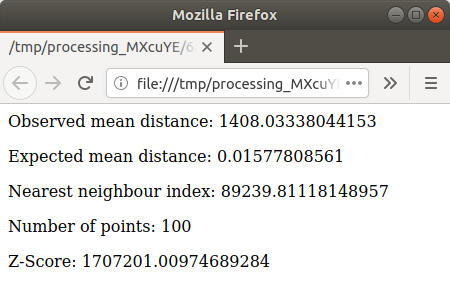
6.4.5. ★☆☆ 따라해보세요: 평균 좌표
데이터셋의 평균 좌표를 얻으려면,
도구를 실행하십시오.
In the dialog that appears, specify
Random pointsas Input layer, and leave the optional choices unchanged.Run 을 클릭합니다.
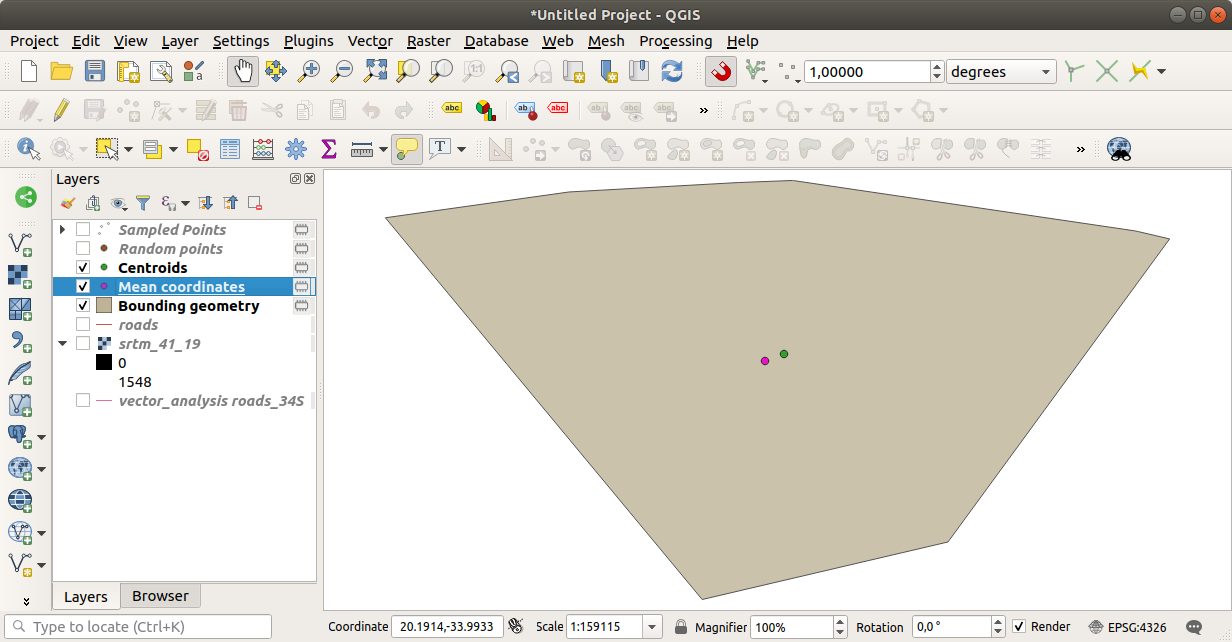
이 결과물을 랜덤한 샘플을 생성하는 데 쓰인 폴리곤의 중심 좌표와 비교해봅시다.
도구를 실행하십시오.
대화창이 열리면, 입력 레이어를
Bounding geometry로 선택하십시오.
여러분도 알 수 있듯이, 평균 좌표(분홍색 포인트)와 연구 영역의 중심(녹색 포인트)이 반드시 일치하지는 않습니다.
중심점(centroid)은 레이어의 무게 중심(barycenter)인 반면 (정사각형의 무게 중심은 정사각형의 중심입니다) 평균 좌표는 모든 노드 좌표들의 평균을 나타냅니다.
6.4.6. ★☆☆ 따라해보세요: 이미지 히스토그램
데이터셋의 히스토그램은 데이터셋의 값들의 분포를 보여줍니다. QGIS에서 이를 보여주는 가장 간단한 방법은 이미지 히스토그램을 사용하는 것으로, 모든 이미지 레이어(래스터 데이터셋)의 Layer Properties 대화창에서 할 수 있습니다.
Layers 패널에서
srtm_41_19레이어를 오른쪽 클릭하십시오.항목을 선택하십시오.
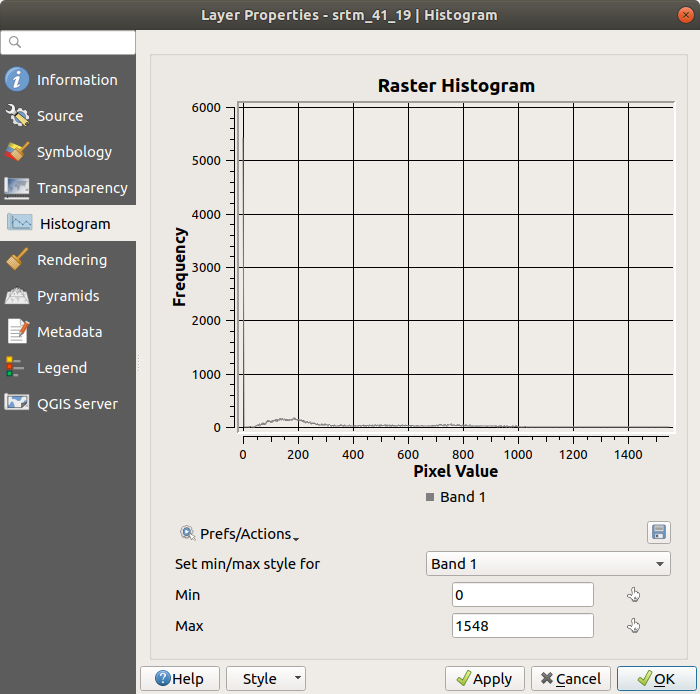
Histogram 탭을 선택하십시오. 그래프를 생성하려면 Compute Histogram 버튼을 클릭해야 할 수도 있습니다. 래스터 값들의 빈도 분포(frequency distribution)를 보여주는 그래프를 보게 될 것입니다.
 Save plot 버튼을 누르면 이 그래프를 이미지로 내보낼 수 있습니다.
Save plot 버튼을 누르면 이 그래프를 이미지로 내보낼 수 있습니다.Information 탭에서 레이어에 대한 더 상세한 정보를 볼 수 있습니다. (평균값과 최대값은 추정치로, 정확하지 않을 수도 있습니다.)
평균값이 332.8 (추정치는 324.3) 그리고 최대값이 1699 (추정치는 1548)입니다! 히스토그램을 확대해볼 수 있습니다. 0 값을 가진 픽셀들이 아주 많기 때문에, 히스토그램이 수직 방향으로 눌려 있는 것처럼 보입니다. 0 의 최고점(peak)을 제외한 모든 것을 볼 수 있도록 확대하면 더 자세한 내용을 볼 수 있습니다:
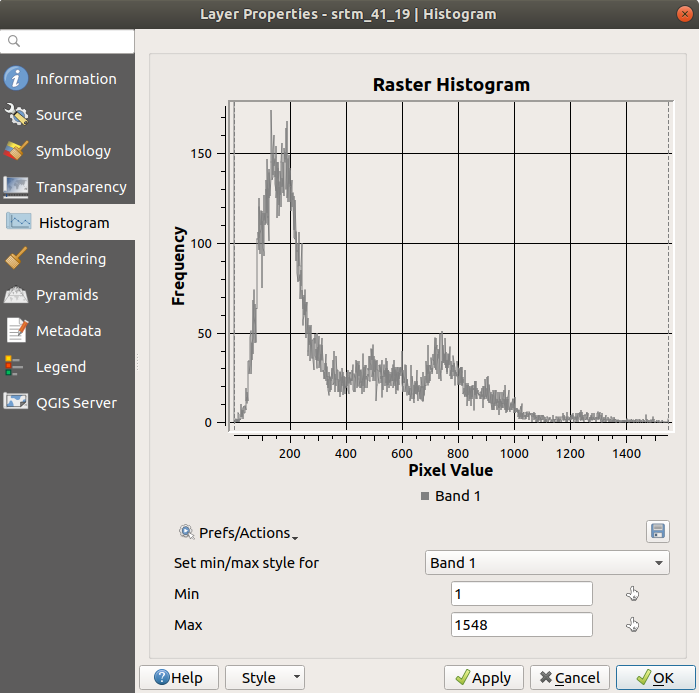
참고
평균값과 최대값이 앞에서 말한 값들과 동일하지 않을 경우, 최대값/최소값 계산 때문일 수 있습니다. Symbology 탭을 열어서 Min / Max Value Settings 메뉴를 펼친 다음,  Min / max 를 선택하고 Apply 를 클릭하십시오.
Min / max 를 선택하고 Apply 를 클릭하십시오.
히스토그램은 값들의 분포를 보여줄 뿐, 모든 값들이 그래프 상에 반드시 가시화되지는 않는다는 사실을 명심하십시오.
6.4.7. ★☆☆ 따라해보세요: 공간 보간
Let’s say you have a collection of sample points from which you would
like to extrapolate data.
For example, you might have access to the Sampled points
dataset we created earlier, and would like to have some idea of what
the terrain looks like.
먼저, Processing Toolbox 에서 도구를 실행하십시오.
Point layer 를
Sampled points로 선택하십시오.Weighting power 를
5.0으로 설정하십시오.Advanced parameters 에서, Z value from field 를
rvalue_1으로 설정하십시오.마지막으로 Run 을 클릭한 다음 처리 과정이 종료될 때까지 기다리십시오.
대화창을 닫습니다.
다음 그림은 원본 데이터셋(왼쪽)과 샘플 포인트들로부터 구성한 데이터셋(오른쪽)을 비교한 것입니다. 샘플 포인트들의 위치의 랜덤한 특성 때문에 실제와 다르게 보일 수 있습니다.
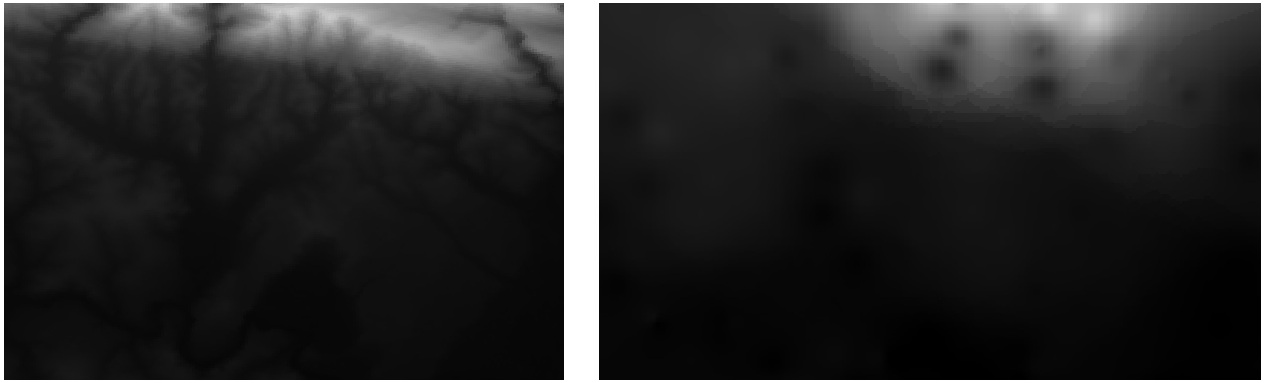
보시다시피 샘플 포인트 100개만으로는 지형을 상세하게 표현하기에 충분하지 않습니다. 매우 일반적인 인상을 주기는 하지만 오해를 불러올 수도 있습니다.
6.4.8. ★★☆ 혼자서 해보세요: 다른 보간법들
앞에서 배운 처리 과정을 사용해서 랜덤 포인트 10,000개 집합을 생성하십시오.
참고
포인트 개수가 정말로 클 경우, 처리 시간이 길어질 수 있습니다.
이 포인트들을 사용해서 원본 DEM을 샘플링하십시오.
이 데이터셋에 Grid (IDW with nearest neighbor searching) 도구를 사용하십시오.
Power 와 Smoothing 을 각각
5.0과2.0으로 설정하십시오.
결과물은 (여러분의 랜덤 포인트 위치에 따라) 다음과 비슷하게 보일 것입니다:

샘플 포인트들의 밀도가 더 높기 때문에, 지형을 더 잘 표현합니다. 기억해두세요 — 샘플이 클수록 결과물도 좋아집니다.
6.4.9. 결론
QGIS는 데이터셋의 공간 통계 속성을 분석하기 위한 도구들을 많이 가지고 있습니다.
6.4.10. 다음은 무엇을 배우게 될까요?
이제 벡터 분석에 대해 배웠으니, 래스터로 무엇을 할 수 있는지 배워보는 것은 어떨까요? 다음 강의에서는 래스터에 대해 배울 것입니다!