Belangrijk
Vertalen is een inspanning van de gemeenschap waaraan u deel kunt nemen. Deze pagina is momenteel voor 100.00% vertaald.
15.1. Les: Introductie voor databases
Laten we, voordat we PostgreSQL gebruiken, onze basis vaststellen door algemene theorie over databases te behandelen. U hoeft geen voorbeeldcode in te voeren; het is er alleen ter illustratie.
Het doel voor deze les: Fundamentele concepten voor databases begrijpen.
15.1.1. Wat is een database?
Een database bestaat uit een georganiseerde verzameling gegevens voor één of meer doeleinden, gewoonlijk in digitale vorm. - Wikipedia
Een database management system (DBMS) bestaat uit software die werkt op databases, opslag, toegang, beveiliging, back-up en andere faciliteiten verschaft. - Wikipedia
15.1.2. Tabellen
In relationele databases en platte databases, is een tabel een verzameling gegevenselementen (waarden) die is georganiseerd met behulp van een model van verticale kolommen (die worden geïdentificeerd door hun naam) en horizontale rijen. Een tabel heeft een gespecificeerd aantal kolommen, maar kunnen elk willekeurig aantal rijen hebben. Elke rij wordt geïdentificeerd door de waarden die verschijnen in een bepaalde subset van kolommen die wordt geïdentificeerd als een kandidaat-sleutel. - Wikipedia
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
In databases van SQL staat een tabel ook bekend als een relatie.
15.1.3. Kolommen / Velden
Een kolom is een verzameling gegevenswaarden van een bepaald eenvoudig type, één voor elke rij van de tabel. De kolommen verschaffen de structuur waarin de rijen overeenkomstig worden samengesteld. De term veld wordt vaak uitwisselbaar gebruik met kolom, hoewel velen het meer correct vinden om veld (of veldwaarde) te gebruiken om specifiek te verwijzen naar het enkele item dat bestaat op de kruising van één rij en één kolom. - Wikipedia
Een kolom:
| name |
+-------+
| Tim |
| Horst |
Een veld:
| Horst |
15.1.4. Records
Een record is de informatie die is opgeslagen in een rij van een tabel. Elk record zal een veld hebben voor elk van de kolommen in de tabel.
2 | Horst | 88 <-- one record
15.1.5. Datatypen
Datatypen beperken het soort informatie dat kan worden opgeslagen in een kolom. - Tim en Horst
er bestaan vele soorten datatypen. Laten we focussen op de meest voorkomende:
String- om tekstgegevens in de vorm van vrije tekst op te slaanInteger- om gehele getallen op te slaanReal- om decimale getallen op te slaanDate- om de verjaardag van Horst op te slaan zodat niemand die vergeetBoolean- om eenvoudige waarden ja/nee op te slaan
U kunt de database vertellen om u ook toe te staan niets in een veld op te slaan. Als er niets in een veld staat, dan wordt naar de veldinhoud verwezen als een ‘null’-waarde:
insert into person (age) values (40);
select * from person;
Resultaat:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
Er zijn nog veel meer datatypen die u kunt gebruiken - bekijk de handleiding van PostgreSQL!
15.1.6. Een adresdatabase modelleren
Laten we een eenvoudig geval bekijken om te zien hoe een database is opgebouwd. We willen een adresdatabase maken.
★☆☆ Probeer zelf:
Schrijf de eigenschappen op waaruit een eenvoudig adres bestaat en die we zouden willen opslaan in onze database.
Antwoord
Voor onze theoretische tabel met adressen willen we misschien de volgende eigenschappen opslaan:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
Bij het maken van de tabel om een object adres weer te geven, zouden we kolommen maken om elk van deze eigenschappen weer te geven en we zouden ze benoemen met voor SQL begrijpelijke en mogelijk afgekorte namen:
house_number
street_name
suburb
city
postcode
country
Structuur van een adres
De eigenschappen die een adres beschrijven zijn de kolommen. Het type informatie dat wordt opgeslagen in elke kolom is het datatype. In het volgende gedeelte zullen we onze conceptuele adrestabel analyseren om te zien hoe we het beter kunnen maken!
15.1.7. Database theorie
Het proces van het maken van een database omvat het maken van een model van de echte wereld; concepten uit de echte wereld nemen en die in de database weer te geven als entiteiten.
15.1.8. Normalisatie
Eén van de belangrijkste ideeën in een database is om duplicatie / herhaling van gegevens te vermijden. Het proces van het verwijderen van herhaling uit een database wordt Normalisatie genoemd.
Normalisatie is een systematische manier om er voor te zorgen dat een structuur van een database geschikt is voor bevragingen van algemene aard en vrij van bepaalde ongewenste karakteristieken - afwijkingen bij invoegen, bijwerken en verwijderen - die zouden kunnen leiden tot verlies van de integriteit van gegevens. - Wikipedia
Er bestaan verschillende ‘vormen’ van normalisatie.
Laten we eens naar een eenvoudig voorbeeld kijken:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Veronderstel dat u veel vrienden heeft met dezelfde straatnaam of stad. Elke keer dat deze gegevens worden gedupliceerd, nemen zij ruimte in. Erger nog, als een naam van een stad wijzigt, moet u veel werk uitvoeren om uw database bij te werken.
15.1.9. ★☆☆ Probeer zelf:
Ontwerp de bovenstaande theoretische tabel people opnieuw om duplicatie te verminderen en de structuur van de gegevens te normaliseren.
U kunt hier meer lezen over normalisatie van databases
Antwoord
Het belangrijkste probleem met de tabel people is dat er één enkel adresveld is dat het gehele adres van een persoon bevat. Denkend aan onze theoretische tabel address eerder in deze les, weten we dat een adres bestaat uit veel verschillende eigenschappen. Door deze eigenschappen op te slaan in één enkel veld, maken we het veel moeilijker om onze gegevens bij te werken en te bevragen. We moeten daarom het adresveld splitsen in de verscheidene eigenschappen. Dat zou ons een tabel geven die de volgende structuur heeft:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
In het volgende gedeelte zult u leren over de relatie Foreign Key die in dit voorbeeld kan worden gebruikt om de structuur van onze database verder te verbeteren.
15.1.10. Indexen
Een index voor een database is een gegevensstructuur die de snelheid van bewerkingen voor het ophalen van gegevens uit een databasetabel verhoogt. - Wikipedia
Veronderstel dat u een tekstboek aan het lezen bent en zoekt naar de uitleg over een concept - en dat het tekstboek geen index heeft! U zult met lezen moeten beginnen bij het voorblad en u geheel door het boek moeten werken totdat u de informatie vindt die u nodig heeft. De index aan het einde van het boek helpt u om snel naar de pagina met de relevante informatie te springen:
create index person_name_idx on people (name);
Zoekacties op namen zullen nu sneller zijn:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. Reeksen
Een reeks is een generator voor unieke nummers. Het wordt normaal gesproken gebruikt om een unieke identificatie te maken voor een kolom in een tabel.
In dit voorbeeld is id een reeks - het nummer wordt opgehoogd, elke keer als een record aan de tabel wordt toegevoegd:
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. Entiteit Relaties Diagrammen
In een genormaliseerde database heeft u gewoonlijk vele relaties (tabellen). Het entiteit-relatie diagram (ER Diagram) wordt gebruikt om de logische afhankelijkheden tussen de relaties te ontwerpen. Denk aan onze niet genormaliseerde tabel people eerder in deze les:
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Met weinig werk kunnen we die splitsen in twee tabellen, waarbij we de noodzaak om de straatnaam te herhalen voor mensen die in dezelfde straat wonen verwijderen:
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
en:
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
We kunnen dan de twee tabellen koppelen met behulp van de ‘sleutels’ streets.id en people.streets_id.
Als we een ER Diagram tekenen voor deze twee tabellen zou het er ongeveer zo uitzien:

Het ER Diagram helpt ons om ‘één tot veel’-relaties uit te drukken. In dit geval geeft het pijlsymbool aan dat in één straat veel mensen zouden kunnen leven.
★★☆ Probeer zelf:
Ons model people heeft nog steeds enige problemen met normalisatie - probeer eens of u het verder kunt normaliseren en geef uw gedachten weer door middel van een ER Diagram.
Antwoord
Onze tabel people ziet er momenteel zo uit:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
De kolom street_id geeft een ‘een-tot-veel’-relatie weer tussen het object people en het daaraan gerelateerde object straat, die in de tabel streets staat.
Een manier om de tabel verder te normaliseren is om het veld met de naam te splitsen in first_name en last_name:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
We kunnen ook afzonderlijke tabellen maken voor de stads- of dorpsnaam en het land, en ze te koppelen aan onze tabel people via ‘een-tot-veel’-relaties:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
Een ER-diagram om dit weer te geven zou er zo uitzien:
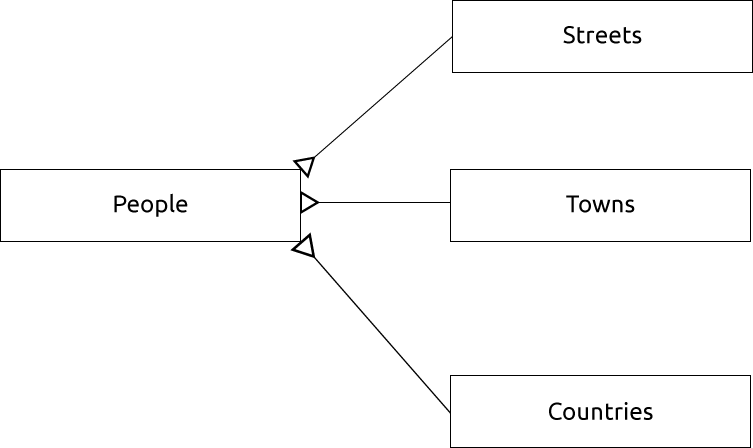
15.1.13. Beperkingen, Primaire sleutels en Vreemde sleutels
Een beperking voor een database wordt gebruikt om er voor te zorgen dat de gegevens in een relatie overeenkomt met de weergave van het model over hoe die gegevens zouden moeten worden opgeslagen. Een beperking op uw postcode zou er, bijvoorbeeld, voor kunnen zorgen dat de getallen vallen tussen 1000 en 9999.
Een Primaire sleutel zijn één of meer veldwaarden die een record uniek maken. Gewoonlijk wordt de primaire sleutel id genoemd en is een reeks.
Een vreemde sleutel wordt gebruikt om te verwijzen naar een uniek record in een andere tabel (met behulp van de primaire sleutel van de andere tabel).
In ER Diagrammen wordt de koppeling tussen tabellen gewoonlijk gebaseerd op het koppelen van Vreemde sleutels aan Primaire sleutels.
Als we naar ons voorbeeld people kijken geeft de definitie van de tabel weer dat de kolom street een vreemde sleutel is die verwijst naar de primaire sleutel van de tabel streets:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. Transacties
Bij het toevoegen, wijzigen of verwijderen van gegevens in een database, is het altijd belangrijk dat de database in een goede status wordt achtergelaten als er iets fout gaat. De meeste databases verschaffen een mogelijkheid, genaamd ondersteuning voor transacties. Transacties stellen u in staat om een positie vast te stellen voor het terugdraaien waarnaar u kunt terugkeren als de aanpassingen aan de database niet gingen zoals was gepland.
Neem een scenario waar u een boekhoudsysteem heeft. U moet fondsen van de ene rekening transfereren en toevoegen aan de andere rekening. De reeks stappen zou als volgt zijn:
verwijder R20 van Joe
voeg R20 toe aan Anne
Als er iets misgaat gedurende het proces (bijv. stroomuitval), zal de transactie worden teruggedraaid.
15.1.15. Conclusie
Databases stellen u in staat gegevens op een gestructureerde manier te beheren met behulp van eenvoudige codestructuren.
15.1.16. Wat volgt?
Laten we, nu we hebben gekeken naar hoe databases in theorie werken, een nieuwe database maken om de theorie die we hebben behandeld te implementeren.