Viktigt
Översättning är en gemenskapsinsats du kan gå med i. Den här sidan är för närvarande översatt till 90.91%.
15.1. Lektion: Introduktion till databaser
Innan vi använder PostgreSQL, låt oss se till att vi är på plats genom att täcka allmän databasteori. Du behöver inte ange någon av exempelkoden; den är bara där för illustrationssyfte.
Målet för den här lektionen: Att förstå grundläggande databaskoncept.
15.1.1. Vad är en databas?
En databas består av en organiserad samling data för ett eller flera användningsområden, vanligtvis i digital form. - Wikipedia
Ett databashanteringssystem (DBMS) består av programvara som driver databaser och tillhandahåller lagring, åtkomst, säkerhet, backup och andra funktioner. - Wikipedia (på engelska)
15.1.2. Tabeller
I relationsdatabaser och flatfilsdatabaser är en tabell en uppsättning dataelement (värden) som är organiserade med hjälp av en modell med vertikala kolumner (som identifieras av sitt namn) och horisontella rader. En tabell har ett visst antal kolumner, men kan ha ett valfritt antal rader. Varje rad identifieras av de värden som förekommer i en viss delmängd av kolumnen som har identifierats som en kandidatnyckel. - Wikipedia
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
I SQL-databaser kallas en tabell också för en relation.
15.1.3. Kolumner / fält
En kolumn är en uppsättning datavärden av en viss enkel typ, en för varje rad i tabellen. Kolumnerna ger den struktur enligt vilken raderna är uppbyggda. Termen fält används ofta synonymt med kolumn, även om många anser att det är mer korrekt att använda fält (eller fältvärde) för att specifikt hänvisa till det enda objekt som finns i skärningspunkten mellan en rad och en kolumn. - Wikipedia
En kolumn:
| name |
+-------+
| Tim |
| Horst |
Textfält
| Horst |
15.1.4. Poster
En post är den information som lagras i en tabellrad. Varje post har ett fält för var och en av kolumnerna i tabellen.
2 | Horst | 88 <-- one record
15.1.5. Datatyper
Datatyper begränsar vilken typ av information som kan lagras i en kolumn. - Tim och Horst
Det finns många olika typer av datatyper. Låt oss fokusera på de vanligaste:
String- för att lagra data i form av fritextInteger- för lagring av hela talReal- för lagring av decimaltalDate- för att lagra Horsts födelsedag så att ingen glömmerBoolean- för att lagra enkla sanna/falska värden
Du kan tala om för databasen att du även kan lagra ingenting i ett fält. Om det inte finns något i ett fält kallas fältinnehållet för ett ”null”-värde:
insert into person (age) values (40);
select * from person;
Resultat:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
Det finns många fler datatyper du kan använda - kolla PostgreSQL-manualen!
15.1.6. Modellering av en adressdatabas
Låt oss använda en enkel fallstudie för att se hur en databas är uppbyggd. Vi vill skapa en adressdatabas.
★☆☆ Prova själv:
Skriv ner de egenskaper som en enkel adress består av och som vi skulle vilja lagra i vår databas.
Svar
För vår teoretiska adresstabell kanske vi vill lagra följande egenskaper:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
När vi skapar tabellen för att representera ett adressobjekt skapar vi kolumner för att representera var och en av dessa egenskaper och vi namnger dem med SQL-kompatibla och eventuellt förkortade namn:
house_number
street_name
suburb
city
postcode
country
Adresstruktur
De egenskaper som beskriver en adress är kolumnerna. Den typ av information som lagras i varje kolumn är dess datatyp. I nästa avsnitt ska vi analysera vår konceptuella adresstabell för att se hur vi kan göra den bättre!
15.1.7. Databasteori
Processen att skapa en databas innebär att man skapar en modell av den verkliga världen; man tar begrepp från den verkliga världen och representerar dem i databasen som entiteter.
15.1.8. Normalisering
En av huvudtankarna med en databas är att undvika dataduplicering/redundans. Processen att ta bort redundans från en databas kallas normalisering.
Normalisering är ett systematiskt sätt att säkerställa att en databasstruktur är lämplig för allmänna sökningar och fri från vissa oönskade egenskaper - anomalier vid införande, uppdatering och radering - som kan leda till förlust av dataintegritet. - Wikipedia
Det finns olika typer av ”formulär” för normalisering.
Låt oss ta en titt på ett enkelt exempel:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Tänk dig att du har många vänner med samma gatunamn eller stad. Varje gång dessa data dupliceras tar det plats. Ännu värre är att om ett stadsnamn ändras måste du göra en massa arbete för att uppdatera din databas.
15.1.9. ★☆☆ Prova själv:
Redesign the theoretical people table above to reduce duplication and to
normalise the data structure.
Du kan läsa mer om normalisering av databaser här <https://en.wikipedia.org/wiki/Database_normalization>`_
Svar
The major problem with the people table is that there is a single address
field which contains a person’s entire address. Thinking about our theoretical
address table earlier in this lesson, we know that an address is made up of
many different properties. By storing all these properties in one field, we make
it much harder to update and query our data. We therefore need to split the
address field into the various properties. This would give us a table which has
the following structure:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
I nästa avsnitt kommer du att lära dig mer om Foreign Key-relationer som kan användas i det här exemplet för att ytterligare förbättra databasens struktur.
15.1.10. Index
Ett databasindex är en datastruktur som gör det snabbare att hämta data från en databastabell. - Wikipedia
Föreställ dig att du läser en lärobok och letar efter förklaringen till ett begrepp - och läroboken har inget index! Du måste börja läsa på ett uppslag och sedan arbeta dig igenom hela boken tills du hittar den information du behöver. Indexet längst bak i boken hjälper dig att snabbt komma till sidan med den relevanta informationen:
create index person_name_idx on people (name);
Nu kommer sökningar på namn att gå snabbare:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. Sekvenser
En sekvens är en generator för unika nummer. Den används normalt för att skapa en unik identifierare för en kolumn i en tabell.
I det här exemplet är id en sekvens - numret ökas varje gång en post läggs till i tabellen:
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. Diagrammering av entitetsrelationer
In a normalised database, you typically have many relations (tables). The
entity-relationship diagram (ER Diagram) is used to design the logical
dependencies between the relations. Consider our non-normalised people table
from earlier in the lesson:
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Med lite arbete kan vi dela upp den i två tabeller, vilket gör att vi inte behöver upprepa gatunamnet för personer som bor på samma gata:
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
och..:
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
We can then link the two tables using the ’keys’ streets.id and
people.streets_id.
Om vi ritar ett ER-diagram för dessa två tabeller skulle det se ut ungefär så här:

ER-diagrammet hjälper oss att uttrycka ”en till många”-relationer. I det här fallet visar pilsymbolen att det kan bo många människor på en gata.
★★☆ Prova själv:
Vår modell ”människor” har fortfarande vissa normaliseringsproblem - försök att se om du kan normalisera den ytterligare och visa dina tankar med hjälp av ett ER-diagram.
Svar
Our people table currently looks like this:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
The street_id column represents a ’one to many’ relationship between the
people object and the related street object, which is in the streets table.
Ett sätt att ytterligare normalisera tabellen är att dela upp namnfältet i förnamn och efternamn:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
We can also create separate tables for the town or city name and country,
linking them to our people table via ’one to many’ relationships:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
Ett ER-diagram för att representera detta skulle se ut så här:
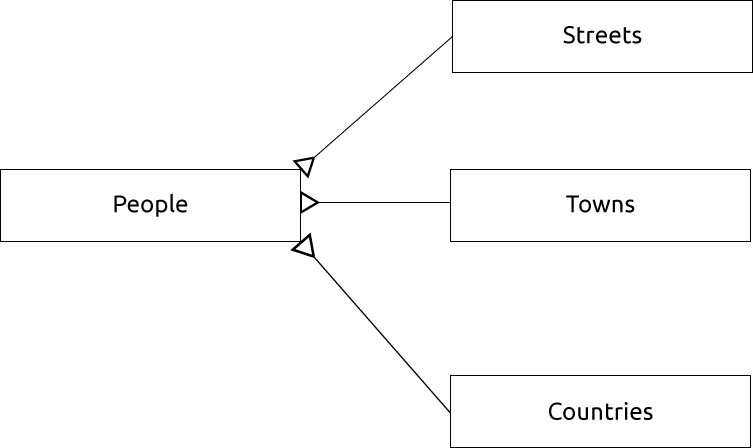
15.1.13. Begränsningar, primärnycklar och främmande nycklar
A database constraint is used to ensure that data in a relation matches the
modeller’s view of how that data should be stored. For example a constraint on
your postal code could ensure that the number falls between 1000 and
9999.
En primärnyckel är ett eller flera fältvärden som gör en post unik. Vanligtvis kallas primärnyckeln id och är en sekvens.
En Foreign key används för att hänvisa till en unik post i en annan tabell (med hjälp av den andra tabellens primärnyckel).
I ER-diagram är kopplingen mellan tabeller normalt baserad på Foreign keys som länkar till Primary keys.
Om vi tittar på vårt exempel med personer visar tabelldefinitionen att kolumnen street är en främmande nyckel som refererar till den primära nyckeln i tabellen streets:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. Transaktioner
När man lägger till, ändrar eller tar bort data i en databas är det alltid viktigt att databasen lämnas i ett bra skick om något går fel. De flesta databaser har en funktion som kallas transaktionsstöd. Med hjälp av transaktioner kan du skapa en rollback-position som du kan återgå till om dina ändringar i databasen inte gick som planerat.
Ta ett scenario där du har ett redovisningssystem. Du behöver överföra pengar från ett konto och lägga till dem på ett annat. Sekvensen av steg skulle se ut så här:
ta bort R20 från Joe
lägg till R20 till Anne
Om något går fel under processen (t.ex. strömavbrott) kommer transaktionen att rullas tillbaka.
15.1.15. Sammanfattningsvis
Med databaser kan du hantera data på ett strukturerat sätt med hjälp av enkla kodstrukturer.
15.1.16. Vad händer härnäst?
Nu när vi har tittat på hur databaser fungerar i teorin, låt oss skapa en ny databas för att implementera den teori vi har gått igenom.