Important
Traducerea este un efort al comunității, la care puteți să vă alăturați. În prezent, această pagină este tradusă 55.00%.
17.23. Mai multe despre interpolare
Notă
Acest capitol prezintă alte cazuri practice de folosire a algoritmilor de interpolare.
Interpolarea este o tehnică obișnuită, acesta putând fi folosită pentru a demonstra mai multe tehnici care pot fi aplicate cu ajutorul cadrului de lucru Processing din QGIS. Această lecție utilizează unii algoritmi de interpolare care au fost deja prezentați, dar care utilizează o abordare diferită.
Datele pentru această lecție conțin, de asemenea, un strat de puncte, în acest caz, cu date de elevație. În general, îl vom interpola în același mod ca și în lecția anterioară, însă, de data aceasta, vom salva o parte din datele originale, pe care o vom utiliza în evaluarea calității procesului de interpolare.
First, we have to rasterize the points layer and fill the resulting no–data cells, but using just a fraction of the points in the layer. We will save 10% of the points for a later check, so we need to have 90% of the points ready for the interpolation. To do so, we could use the Split shapes layer randomly algorithm, which we have already used in a previous lesson, but there is a better way to do that, without having to create any new intermediate layer. Instead of that, we can just select the points we want to use for the interpolation (the 90% fraction), and then run the algorithm. As we have already seen, the rasterizing algorithm will use only those selected points and ignore the rest. The selection can be done using the Random selection algorithm. Run it with the following parameters.
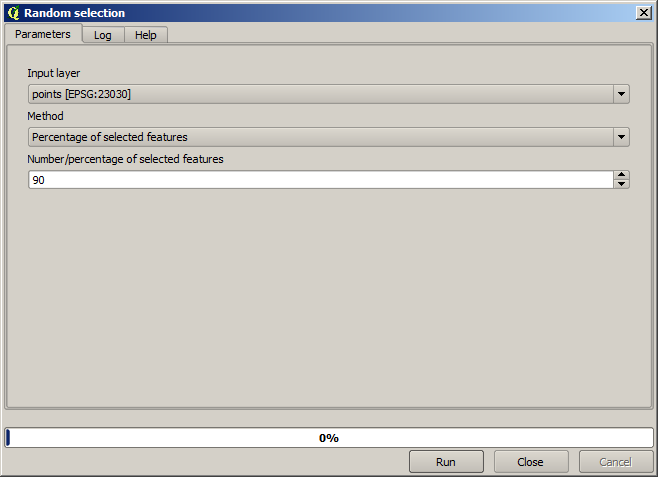
Se vor selecta 90% dintre punctele din stratul de rasterizat

Selecția este aleatoare, astfel încât selecția dvs. ar putea diferi de selecția arătată în imaginea de mai sus.
Now run the Rasterize algorithm to get the first raster layer, and then run the Close gaps algorithm to fill the no-data cells [Cell resolution: 100 m].

To check the quality of the interpolation, we can now use the points that are not selected. At this point, we know the real elevation (the value in the points layer) and the interpolated elevation (the value in the interpolated raster layer). We can compare the two by computing the differences between those values.
Din moment ce vom folosi punctele care nu sunt selectate, în primul rând, haideți să inversăm selecția.

The points contain the original values, but not the interpolated ones. To add them in a new field, we can use the Add raster values to points algorithm
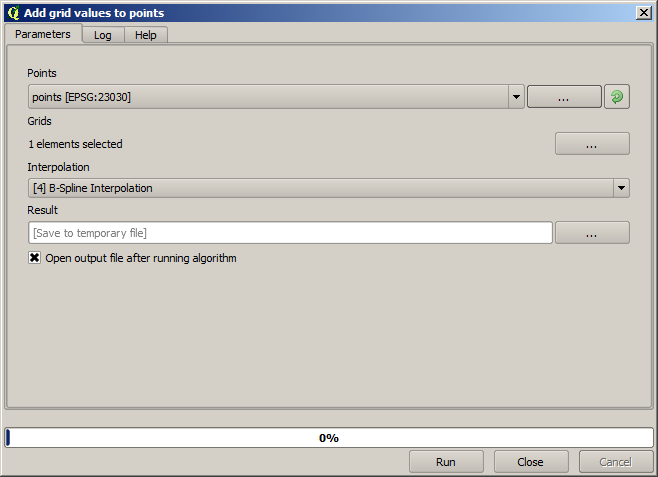
The raster layer to select (the algorithm supports multiple raster, but we just need one) is the resulting one from the interpolation. We have renamed it to interpolate and that layer name is the one that will be used for the name of the field to add.
Acum avem un strat vectorial care conține ambele valori, cu punctele care nu au fost utilizate pentru interpolare.
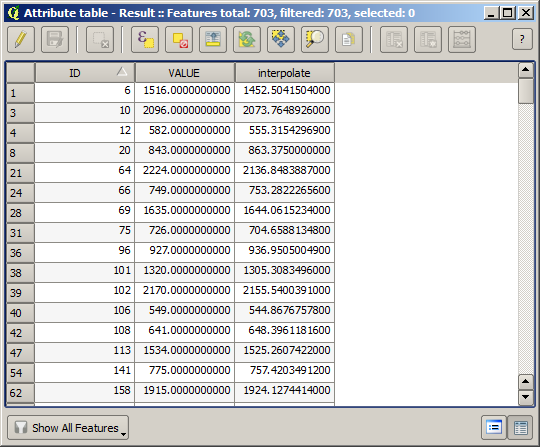
Now, we will use the fields calculator for this task. Open the Field calculator algorithm and run it with the following parameters.
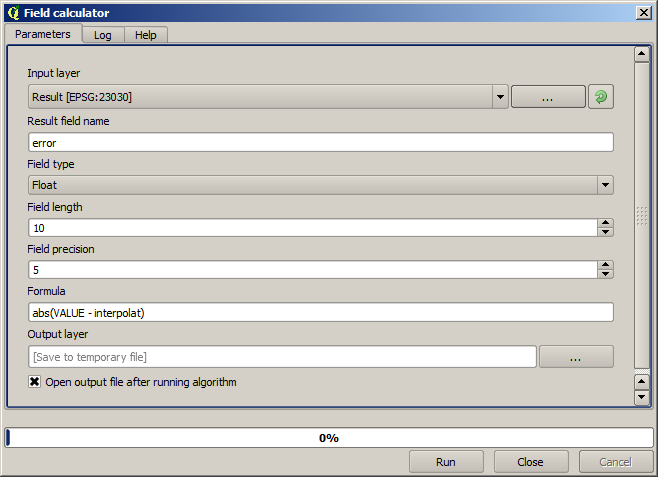
If your field with the values from the raster layer has a different name, you should modify the above formula accordingly. Running this algorithm, you will get a new layer with just the points that we haven’t used for the interpolation, each of them containing the difference between the two elevation values.
Reprezentând stratul în conformitate cu acea valoare, vom avea o primă idee despre locația celor mai mari discrepanțe.
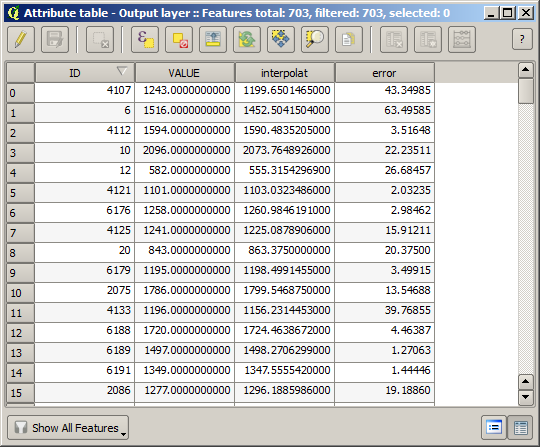
Interpolând acel strat veți obține un strat raster cu eroarea estimată în toate punctele din zona interpolată.
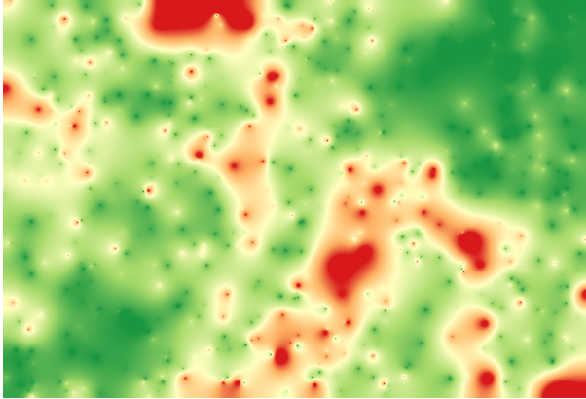
You can also get the same information (difference between original point values and interpolated ones) directly with .
Your results might differ from these ones, since there is a random component introduced when running the random selection, at the beginning of this lesson.