Important
La traduction est le fruit d’un effort communautaire auquel vous pouvez vous joindre. Cette page est actuellement traduite à 89.70%.
24.1.29. Table vecteur
24.1.29.1. Ajouter un champ auto-incrémenté
Ajoute un nouveau champ entier à une couche vecteur, avec une valeur séquentielle pour chaque entité.
Ce champ peut être utilisé comme ID unique pour les entités de la couche. Le nouvel attribut n’est pas ajouté à la couche d’entrée mais une nouvelle couche est générée à la place.
La valeur de départ initiale pour la série incrémentielle peut être spécifiée. Facultativement, la série incrémentielle peut être basée sur des champs de regroupement et un ordre de tri pour les entités peut également être spécifié.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
La couche vecteur d’entrée. |
Nom du champ |
|
[Chaîne de caractères] Par défaut : “AUTO” |
Nom du champ avec valeurs d’incrémentation automatique |
Valeurs de départ à Optionnel |
|
[numérique : entier] Par défaut : 0 |
Choisissez le numéro initial du compte incrémentiel |
Modulus value Optionnel |
|
[numérique : entier] Par défaut : 0 |
Specifying an optional modulus value will restart the count to START
whenever the field value reaches the modulus value. |
Regrouper les valeurs par Optionnel |
|
[champ : tout type] [liste] |
Sélectionnez le ou les champs de regroupement: au lieu d’un seul comptage exécuté pour la couche entière, un décompte séparé est traité pour chaque valeur renvoyée par la combinaison de ces champs. |
Expression de tri Optionnel |
|
[expression] |
Utilisez une expression pour trier les entités de la couche de manière globale ou si elles sont définies, en fonction des champs groupés. |
Trier par ordre croissant |
|
[booléen] Par défaut : Vrai |
Lorsqu’une |
Trier les valeurs nulles en premier |
|
[booléen] Par défaut : Faux |
Lorsqu’une |
Incrémenté |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer with the auto increment field. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Incrémenté |
|
[identique à l’entrée] |
Couche vecteur avec champ d’incrémentation automatique |
Code Python
ID de l’algorithme : native:addautoincrementalfield
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.29.2. Ajouter un champ à la table des attributs
Ajoute un nouveau champ à une couche vecteur.
Le nom et les caractéristiques de l’attribut sont définis en paramètre.
Le nouvel attribut n’est pas ajouté à la couche d’entrée mais une nouvelle couche est générée à la place.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
La couche d’entrée |
Nom du champ |
|
[Chaîne de caractères] |
Nom du nouveau champ |
Type de champ |
|
[énumération] Par défaut : 0 |
Type du nouveau champ. Vous pouvez choisir entre:
|
Longueur de champ |
|
[numérique : entier] Par défaut : 10 |
Longueur du champ |
Précision de champ |
|
[numérique : entier] Par défaut : 0 |
Précision du champ. Utile avec le type de champ Flottant. |
Field alias Optionnel
|
|
[Chaîne de caractères] |
Set a name to use as alias for the field. Not supported by all format types. |
Field comment Optionnel
|
|
[Chaîne de caractères] |
Store a comment describing the field. Not supported by all format types. |
Ajout |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Ajout |
|
[identique à l’entrée] |
Couche vecteur avec nouveau champ ajouté |
Code Python
ID de l’algorithme : native:addfieldtoattributestable
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.29.3. Ajouter un champ d’index de valeur unique
Prend une couche vecteur et un attribut et ajoute un nouveau champ numérique.
Les valeurs de ce champ correspondent aux valeurs de l’attribut spécifié, donc les entités ayant la même valeur pour l’attribut auront la même valeur dans le nouveau champ numérique.
Cela crée un équivalent numérique de l’attribut spécifié, qui définit les mêmes classes.
Le nouvel attribut n’est pas ajouté à la couche d’entrée mais une nouvelle couche est générée à la place.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
La couche d’entrée. |
Champ de classe |
|
[champ : tout type] |
Les entités qui ont la même valeur pour ce champ obtiendront le même index. |
Nom du champ de sortie |
|
[Chaîne de caractères] Par défaut : “NUM_FIELD” |
Nom du nouveau champ contenant les index. |
Couche avec champ d’index |
|
[identique à l’entrée] Par défaut : |
Vector layer with the numeric field containing indexes. One of:
L’encodage du fichier peut également être modifié ici. |
Resume de la classe |
|
[vecteur : table] Par défaut : |
Specify the table to contain the summary of the class field mapped to the corresponding unique value. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche avec champ d’index |
|
[identique à l’entrée] |
Couche vecteur avec le champ numérique contenant les index. |
Resume de la classe |
|
[vecteur : table] |
Table avec récapitulatif du champ de classe mappé à la valeur unique correspondante. |
Code Python
ID de l’algorithme : native:adduniquevalueindexfield
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.29.4. Ajouter les champs X/Y à la couche
Ajoute des champs X et Y (ou latitude/longitude) à une couche de points. Les champs X/Y peuvent être calculés dans un SCR différent de celui de la couche (par exemple en créant des champs de latitude/longitude pour une couche dans un SCR projeté).
 Permet la modification de la couche source pour des entités de type point
Permet la modification de la couche source pour des entités de type point
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : point] |
La couche d’entrée. |
Système de coordonnées |
|
[scr] Par défaut : « EPSG:4326 » |
Système de référence de coordonnées à utiliser pour les champs x et y générés. |
Préfixe de champ Optionnel |
|
[Chaîne de caractères] |
Préfixe à ajouter aux nouveaux noms de champs pour éviter les collisions de noms avec les champs de la couche d’entrée. |
Champs ajoutés |
|
[vecteur : point] Par défaut : |
Specify the output layer. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Champs ajoutés |
|
[vecteur : point] |
La couche de sortie - identique à la couche d’entrée mais avec deux nouveaux champs doubles, |
Code Python
Algorithm ID: native:addxyfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.29.5. Calculateur de champ avancée Python
Ajoute un nouvel attribut à une couche vecteur, avec des valeurs résultant de l’application d’une expression à chaque entité.
L’expression est définie comme une fonction Python.
Avertissement
This algorithm is a potential security risk if executed with unchecked inputs, and may result in system damage or data leaks.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
Couche vectorielle en entrée |
Nom du champ de résultat |
|
[Chaîne de caractères] Par défaut : “NewField” |
Nom du nouveau champ |
Type de champ |
|
[énumération] Par défaut : 0 |
Type du nouveau champ. Un des:
|
Longueur de champ |
|
[numérique : entier] Par défaut : 10 |
Longueur du champ |
Précision de champ |
|
[numérique : entier] Par défaut : 3 |
Précision du champ. Utile avec le type de champ Flottant. |
Expression globale Optionnel |
|
[Chaîne de caractères] |
Le code de la section d’expression globale ne sera exécuté qu’une seule fois avant que la calculatrice ne commence à parcourir toutes les entités de la couche d’entrée. Par conséquent, c’est le bon endroit pour importer les modules nécessaires ou pour calculer les variables qui seront utilisées dans les calculs ultérieurs. |
Formule |
|
[Chaîne de caractères] |
La formule Python à évaluer. Exemple: Pour calculer l’aire d’une couche de polygones en entrée, vous pouvez ajouter: value = $geom.area()
To access an existing field use its name enclosed in the angle brackets. For example, to uppercase values of the « address » field: value = <address>.upper()
|
Calculé |
|
[identique à l’entrée] Par défaut : |
Spécifiez la couche vecteur avec le nouveau champ calculé. Un des:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Calculé |
|
[identique à l’entrée] |
Couche vecteur avec le nouveau champ calculé |
Code Python
ID de l’algorithme : qgis:advancedpythonfieldcalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.29.6. Supprimer champ (s)
Prend une couche vecteur et en génère une nouvelle qui a les mêmes caractéristiques mais sans les colonnes sélectionnées.
Voir aussi
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
Couche vecteur d’entrée à partir de laquelle supprimer les champs |
Champs à supprimer |
|
[champ : tout type] [liste] |
Le ou les champs à supprimer |
Champs restants |
|
[identique à l’entrée] Par défaut : |
Specify the output vector layer with the remaining fields. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Champs restants |
|
[identique à l’entrée] |
Couche vecteur avec les champs restants |
Code Python
ID de l’algorithme : native:deletecolumn
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.29.7. Exploser un champ HStore
Crée une copie de la couche d’entrée et ajoute un nouveau champ pour chaque clé unique du champ HStore.
La liste des champs attendue est une liste facultative séparée par des virgules. Si cette liste est spécifiée, seuls ces champs sont ajoutés et le champ HStore est mis à jour. Par défaut, toutes les clés uniques sont ajoutées.
The PostgreSQL HStore
is a simple key-value store used in PostgreSQL and GDAL (when reading
an OSM file
with the other_tags field.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : géométrie] |
Couche vectorielle en entrée |
Champ HStore |
|
[champ : tout type] |
Le ou les champs à supprimer |
Liste attendue des champs séparés par une virgule Optionnel |
|
[Chaîne de caractères] Par défaut : “” |
Liste de champs séparés par des virgules à extraire. Le champ HStore sera mis à jour en supprimant ces clés. |
Eclaté |
|
[identique à l’entrée] Par défaut : |
Spécifiez la couche vectorielle de sortie. Un des:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Eclaté |
|
[identique à l’entrée] |
Couche vectorielle de sortie |
Code Python
ID de l’algorithme : native:explodehstorefield
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.29.8. Extraire le champ binaire
Extrait le contenu d’un champ binaire et les enregistrent dans des fichiers individuels. Les noms de fichiers peuvent être générés à l’aide de valeurs tirées d’un attribut de la table source ou basés sur une expression plus complexe.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
Couche vecteur d’entrée contenant les données binaires |
Champ binaire |
|
[champ : tout type] |
Champ contenant les données binaires |
Nom du fichier |
|
[expression] |
Texte basé sur un champ ou une expression pour nommer chaque fichier de sortie |
Dossier de destination |
|
[répertoire] Par défaut : |
Folder in which to store the output files. One of:
|
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Dossier |
|
[répertoire] |
Répertoire contenant les fichiers de sortie. |
Code Python
ID de l’algorithme : native:extractbinary
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.29.9. Calculatrice de champ
Ouvre la calculatrice de champs (voir Expressions). Vous pouvez utiliser toutes les expressions et fonctions prises en charge.
Une nouvelle couche est créée avec le résultat de l’expression.
La calculatrice de champs est très utile lorsqu’il est utilisé dans Le modeleur.
Note
This algorithm uses ellipsoid based measurements and respects the current ellipsoid settings.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
La couche sur laquelle calculer |
Nom du champ de sortie |
|
[Chaîne de caractères] |
Le nom du champ pour les résultats |
Type de champ de sortie |
|
[énumération] Par défaut : 0 |
Le type du champ. Un des:
|
Longueur du champ de sortie |
|
[numérique : entier] Par défaut : 0 |
La longueur du champ de résultat (minimum 0) |
Précision de champ |
|
[numérique : entier] Par défaut : 0 |
La précision du champ de résultat (minimum 0, maximum 15) |
Créer un nouveau champ |
|
[booléen] Par défaut : Vrai |
Le champ de résultat doit-il être un nouveau champ |
Formule |
|
[expression] |
La formule à utiliser pour calculer le résultat |
Calculé |
|
[identique à l’entrée] Par défaut : |
Spécification de la couche de sortie.
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Calculé |
|
[identique à l’entrée] |
Couche de sortie avec les valeurs de champ calculées |
Code Python
ID de l’algorithme : native:fieldcalculator
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.29.10. Refactoriser les champs
Permet de modifier la structure de la table attributaire d’une couche vecteur.
Les champs peuvent être modifiés dans leur type et leur nom, à l’aide d’un mappage de champs.
La couche d’origine n’est pas modifiée. Une nouvelle couche est générée, qui contient une table d’attributs modifiée, selon le mappage des champs fournis.
Note
When using a template layer with constraints on fields, the information is displayed in the widget with a coloured background and tooltip. Treat this information as a hint during configuration. No constraints will be added on an output layer nor will they be checked or enforced by the algorithm.
The Refactor fields algorithm allows to:
Modifier les noms et types de champs
Ajouter et supprimer des champs
Réorganiser les champs
Calculer de nouveaux champs en fonction des expressions
Charger la liste des champs à partir d’une autre couche
Note
This algorithm uses ellipsoid based measurements and respects the current ellipsoid settings.
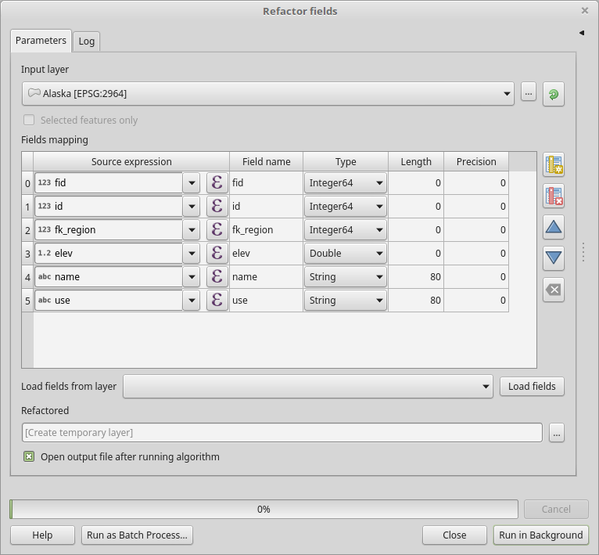
Fig. 24.178 Boîte de dialogue des champs de refactorisation
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
La couche à modifier |
Mapper les champs |
|
[liste] |
Liste des champs de sortie avec leurs définitions. Le tableau intégré répertorie tous les champs de la couche source et vous permet de les modifier:
Pour chacun des champs que vous souhaitez réutiliser, vous devez remplir les options suivantes:
|
Refactorisé |
|
[identique à l’entrée] Par défaut : |
Spécification de la couche de sortie. Une des options suivantes:
L’encodage du fichier peut également être modifié ici. |





Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Refactorisé |
|
[identique à l’entrée] |
Couche de sortie avec champs refactorisés |
Code Python
ID de l’algorithme : native:refactorfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.29.11. Rename field
Renomme un champ existant à partir d’une couche vecteur.
La couche originale n’est pas modifiée. Une nouvelle couche est générée lorsque la table d’attributs contient le champ renommé.
Voir aussi
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
La couche de vecteur d’entrée |
Champ à renommer |
|
[champ : tout type] |
Le champ à modifier |
Nouveau nom de champ |
|
[Chaîne de caractères] |
Le nouveau nom du champ |
Renommé |
|
[identique à l’entrée] Par défaut : |
Spécification de la couche de sortie. Une des options suivantes:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Renommé |
|
[identique à l’entrée] |
Couche de sortie avec le champ renommé |
Code Python
Algorithm ID: native:renametablefield
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.29.12. Retain fields
Takes a vector layer and generates a new one that retains only the selected fields. All other fields will be dropped.
Voir aussi
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
La couche de vecteur d’entrée |
Fields to retain |
|
[champ : tout type] [liste] |
List of fields to keep in the layer |
Retained fields |
|
[identique à l’entrée] Par défaut : |
Spécification de la couche de sortie. Une des options suivantes:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Retained fields |
|
[identique à l’entrée] |
Output layer with the retained fields |
Code Python
ID de l’algorithme : native:retainfields
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.
24.1.29.13. Texte vers décimal
Modifie le type d’un attribut donné dans une couche vecteur, convertissant un attribut de texte contenant des chaînes numériques en un attribut numérique (par exemple, 1 à 1.0).
L’algorithme crée une nouvelle couche vecteur afin que la source ne soit pas modifiée.
Si la conversion n’est pas possible, la colonne sélectionnée aura des valeurs NULL.
Paramètres
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Couche en entrée |
|
[vecteur : tout type] |
La couche vecteur d’entrée. |
Attribut texte à convertir en flottant |
|
[champ : chaîne de caractères] |
Champ de chaîne de la couche d’entrée à convertir en champ flottant. |
Nombre flottant à partir de texte |
|
[identique à l’entrée] Par défaut : |
Specify the output layer. One of:
L’encodage du fichier peut également être modifié ici. |
Les sorties
Etiquette |
Nom |
Type |
Description |
|---|---|---|---|
Nombre flottant à partir de texte |
|
[identique à l’entrée] |
Couche vecteur de sortie avec le champ de chaîne converti en champ flottant |
Code Python
ID de l’algorithme : qgis:texttofloat
import processing
processing.run("algorithm_id", {parameter_dictionary})
L”id de l’algorithme est affiché lors du survol du nom de l’algorithme dans la boîte à outils Traitements. Les nom et valeur de chaque paramètre sont fournis via un dictionnaire de paramètres. Voir Utiliser les algorithmes du module de traitements depuis la console Python pour plus de détails sur l’exécution d’algorithmes via la console Python.