Importante
A tradução é um esforço comunitário você pode contribuir. Esta página está atualmente traduzida em 73.68%.
17.22. Interpolação
Nota
Este capítulo mostra como interpolar dados de pontos e mostrará outro exemplo real de análise espacial.
Nesta lição iremos interpolar dados de pontos para obter uma camada raster. Antes disso, iremos realizar a preparação dos dados, e depois de interpolar faremos outros processamentos para modificar a camada resultante, para termos então uma rotina completa de análise.
Abra os dados de exemplo para esta lição, que deve ser semelhante a este.

Os dados correspondem aos dados de rendimento de colheita, como produzido por uma colheitadeira moderna, e nós o usaremos para obter uma camada raster de rendimento de colheita. Não planejamos fazer nenhuma análise adicional com essa camada, mas apenas usá-la como uma camada de fundo para identificar facilmente as áreas mais produtivas e também aquelas onde a produtividade pode ser melhorada.
The first thing to do is to clean–up the layer, since it contains redundant points. These are caused by the movement of the harvester, in places where it has to do a turn or it changes its speed for some reason. The Points filter algorithm will be useful for this. We will use it twice, to remove points that can be considered outliers both in the upper and lower part of the distribution.
Para a primeira execução, usar os seguintes valores de parâmetro.
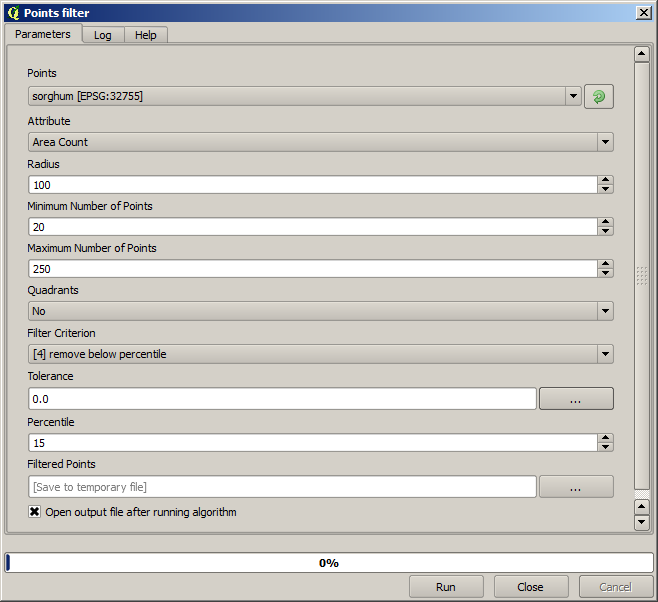
Agora para o próximo, use a configuração mostrada abaixo.
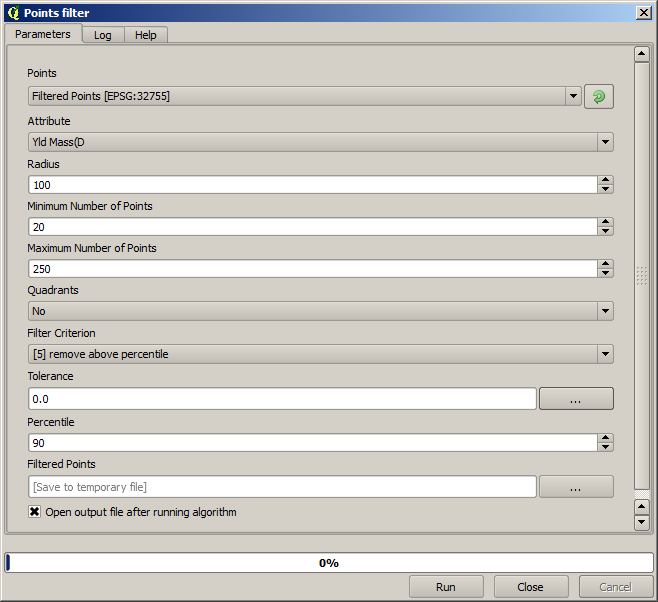
Observe que não estamos usando a camada original como entrada, mas sim a camada de saída da execução anterior.
A camada final filtrada, com um conjunto reduzido de pontos, deve ser semelhante à original, mas irá conter um número menor de pontos. Você pode verificar isso comparando suas tabelas de atributos.
Now let’s rasterize the layer using the Rasterize algorithm.
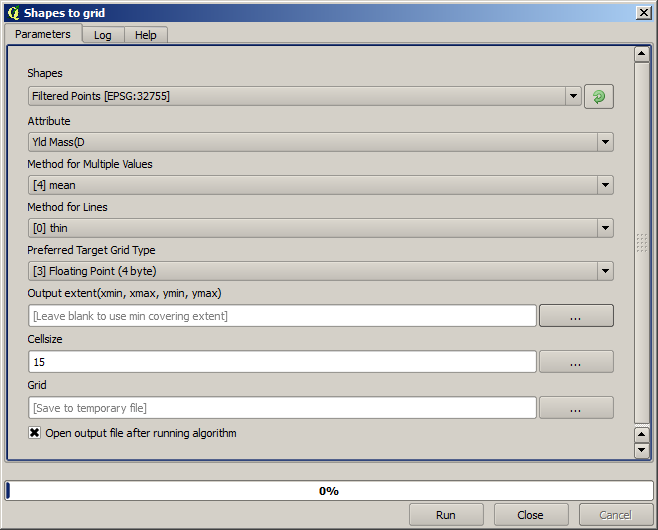
The Filtered points layer refers to the resulting one of the second filter.
It has the same name as the one produced by the first filter, since the name
is assigned by the algorithm, but you should not use the first one. Since we
will not be using it for anything else, you can safely remove it from your
project to avoid confusion, and leave just the last filtered layer.
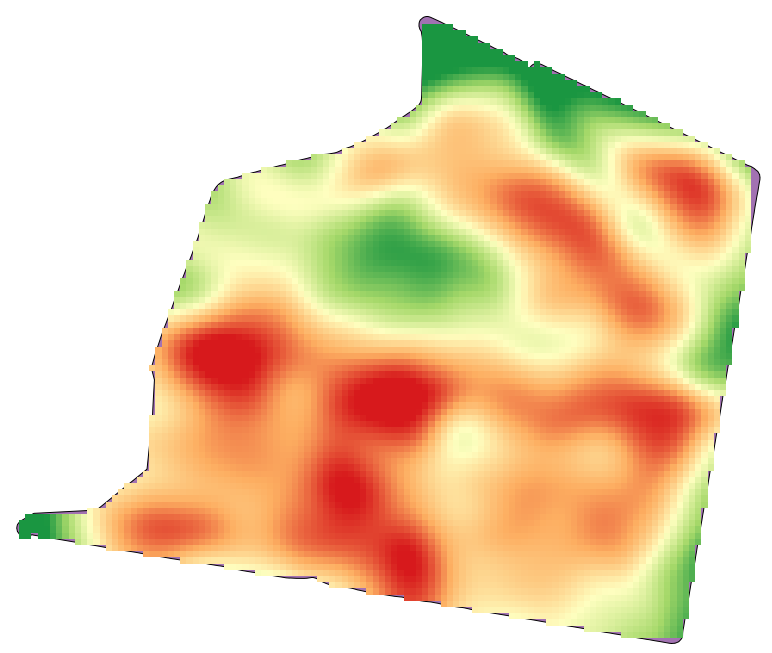
A camada raster resultante se parece com isso.

It is already a raster layer, but it is missing data in some of its cells. It only contain valid values in those cells that contained a point from the vector layer that we have just rasterized, and a no–data value in all the other ones. To fill the missing values, we can use the Close gaps algorithm.
A camada sem valores no-data é assim.

Para restringir a área coberta pelos dados apenas para a região onde o rendimento da safra foi medido, podemos recortar a camada raster com a camada de limites fornecida.

And for a smoother result (less accurate but better for rendering in the background as a support layer), we can apply a Gaussian filter to the layer.
Com os parâmetros acima, você obterá o seguinte resultado