25.1.17. Vector general
25.1.17.1. Assign projection
Assigns a new projection to a vector layer.
It creates a new layer with the exact same features and geometries as the input one, but assigned to a new CRS. The geometries are not reprojected, they are just assigned to a different CRS.
This algorithm can be used to repair layers which have been assigned an incorrect projection.
Attributes are not modified by this algorithm.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layer |
|
[vector: any] |
Vector layer with wrong or missing CRS |
Assigned CRS |
|
[crs] Default: |
Select the new CRS to assign to the vector layer |
Assigned CRS Optional |
|
[same as input] Default: |
Specify the output layer containing only the duplicates. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Assigned CRS |
|
[same as input] |
Vector layer with assigned projection |
Python code
Algorithm ID: native:assignprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.2. Batch Nominatim geocoder
Performs batch geocoding using the Nominatim service against an input layer string field. The output layer will have a point geometry reflecting the geocoded location as well as a number of attributes associated to the geocoded location.
Note
This algorithm is compliant with the usage policy of the Nominatim geocoding service provided by the OpenStreetMap Foundation.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layer |
|
[vector: any] |
Vector layer to geocode the features |
Address field |
|
[tablefield: string] |
Field containing the addresses to geocode |
Geocoded |
|
[vector: point] Default: |
Specify the output layer containing only the geocoded addresses. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Geocoded |
|
[vector: point] |
Vector layer with point features corresponding to the geocoded addresses |
Python code
Algorithm ID: native:batchnominatimgeocoder
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.3. Convert layer to spatial bookmarks
Creates spatial bookmarks corresponding to the extent of features contained in a layer.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: line, polygon] |
The input vector layer |
Bookmark destination |
|
[enumeration] Default: 0 |
Select the destination for the bookmarks. One of:
|
Name field |
|
[expression] |
Field or expression that will give names to the generated bookmarks |
Group field |
|
[expression] |
Field or expression that will provide groups for the generated bookmarks |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Count of bookmarks added |
|
[number] |
Python code
Algorithm ID: native:layertobookmarks
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.4. Convert spatial bookmarks to layer
Creates a new layer containing polygon features for stored spatial bookmarks. The export can be filtered to only bookmarks belonging to the current project, to all user bookmarks, or a combination of both.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Bookmark source |
|
[enumeration] [list] Default: [0,1] |
Select the source(s) of the bookmarks. One or more of:
|
Output CRS |
|
[crs] Default: |
The CRS of the output layer |
Output |
|
[vector: polygon] Default: |
Specify the output layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output |
|
[vector: polygon] |
The output (bookmarks) vector layer |
Python code
Algorithm ID: native:bookmarkstolayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.5. Create attribute index
Creates an index against a field of the attribute table to speed up queries. The support for index creation depends on both the layer’s data provider and the field type.
No outputs are created: the index is stored on the layer itself.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Select the vector layer you want to create an attribute index for |
Attribute to index |
|
[tablefield: any] |
Field of the vector layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Indexed layer |
|
[same as input] |
A copy of the input vector layer with an index for the specified field |
Python code
Algorithm ID: native:createattributeindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.6. Create spatial index
Creates an index to speed up access to the features in a layer based on their spatial location. Support for spatial index creation is dependent on the layer’s data provider.
No new output layers are created.
Default menu:
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Input vector layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Indexed layer |
|
[same as input] |
A copy of the input vector layer with a spatial index |
Python code
Algorithm ID: native:createspatialindex
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.7. Define Shapefile projection
Sets the CRS (projection) of an existing Shapefile format dataset to
the provided CRS.
It is very useful when a Shapefile format dataset is missing the
prj file and you know the correct projection.
Contrary to the Assign projection algorithm, it modifies the current layer and will not output a new layer.
Note
For Shapefile datasets, the .prj and .qpj files will
be overwritten - or created if missing - to match the provided CRS.
Default menu:
See also
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layer |
|
[vector: any] |
Vector layer with missing projection information |
CRS |
|
[crs] |
Select the CRS to assign to the vector layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
|
[same as input] |
The input vector layer with the defined projection |
Python code
Algorithm ID: qgis:definecurrentprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.8. Delete duplicate geometries
Finds and removes duplicated geometries.
Attributes are not checked, so in case two features have identical geometries but different attributes, only one of them will be added to the result layer.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layer |
|
[vector: any] |
The layer with duplicate geometries you want to clean |
Cleaned |
|
[same as input] Default: |
Specify the output layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Count of discarded duplicate records |
|
[number] |
Count of discarded duplicate records |
Cleaned |
|
[same as input] |
The output layer without any duplicated geometries |
Count of retained records |
|
[number] |
Count of unique records |
Python code
Algorithm ID: native:deleteduplicategeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.9. Delete duplicates by attribute
Deletes duplicate rows by only considering the specified field / fields. The first matching row will be retained, and duplicates will be discarded.
Optionally, these duplicate records can be saved to a separate output for analysis.
See also
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layer |
|
[vector: any] |
The input layer |
Fields to match duplicates by |
|
[tablefield: any] [list] |
Fields defining duplicates. Features with identical values for all these fields are considered duplicates. |
Filtered (no duplicates) |
|
[same as input] Default: |
Specify the output layer containing the unique features. One of:
The file encoding can also be changed here. |
Filtered (duplicates) Optional |
|
[same as input] Default: |
Specify the output layer containing only the duplicates. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Filtered (duplicates) Optional |
|
[same as input] Default: |
Vector layer containing the removed features.
Will not be produced if not specified (left as
|
Count of discarded duplicate records |
|
[number] |
Count of discarded duplicate records |
Filtered (no duplicates) |
|
[same as input] |
Vector layer containing the unique features. |
Count of retained records |
|
[number] |
Count of unique records |
Python code
Algorithm ID: native:removeduplicatesbyattribute
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.10. Detect dataset changes
Compares two vector layers, and determines which features are unchanged, added or deleted between the two. It is designed for comparing two different versions of the same dataset.
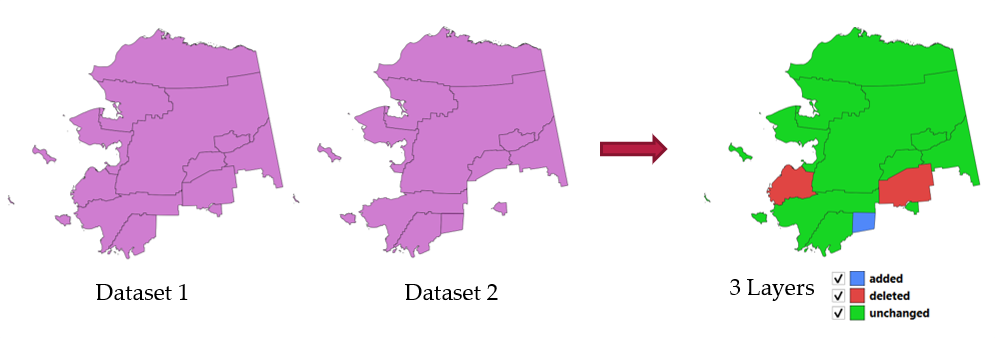
Fig. 25.44 Detect dataset change example
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Original layer |
|
[vector: any] |
The vector layer considered as the original version |
Revised layer |
|
[vector: any] |
The revised or modified vector layer |
Attributes to consider for match Optional |
|
[tablefield: any] [list] |
Attributes to consider for match. By default, all attributes are compared. |
Geometry comparison behavior Optional |
|
[enumeration] Default: 1 |
Defines the criteria for comparison. Options:
|
Unchanged features |
|
[vector: same as Original layer] |
Specify the output vector layer containing the unchanged features. One of:
The file encoding can also be changed here. |
Added features |
|
[vector: same as Original layer] |
Specify the output vector layer containing the added features. One of:
The file encoding can also be changed here. |
Deleted features |
|
[vector: same as Original layer] |
Specify the output vector layer containing the deleted features. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Unchanged features |
|
[vector: same as Original layer] |
Vector layer containing the unchanged features. |
Added features |
|
[vector: same as Original layer] |
Vector layer containing the added features. |
Deleted features |
|
[vector: same as Original layer] |
Vector layer containing the deleted features. |
Count of unchanged features |
|
[number] |
Count of unchanged features. |
Count of features added in revised layer |
|
[number] |
Count of features added in revised layer. |
Count of features deleted from original layer |
|
[number] |
Count of features deleted from original layer. |
Python code
Algorithm ID: native:detectvectorchanges
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.11. Drop geometries
Creates a simple geometryless copy of the input layer attribute table. It keeps the attribute table of the source layer.
If the file is saved in a local folder, you can choose between many file formats.
 Allows features in-place modification
Allows features in-place modification
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layer |
|
[vector: any] |
The input vector layer |
Dropped geometries |
|
[table] |
Specify the output geometryless layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Dropped geometries |
|
[table] |
The output geometryless layer. A copy of the original attribute table. |
Python code
Algorithm ID: native:dropgeometries
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.12. Execute SQL
Runs a simple or complex query with SQL syntax on the source
layer.
Input datasources are identified with input1, input2… inputN and
a simple query will look like SELECT * FROM input1.
Beside a simple query, you can add expressions or variables within the
SQL query parameter itself. This is particulary useful if this algorithm is
executed within a Processing model and you want to use a model input as a
parameter of the query. An example of a query will then be SELECT * FROM
[% @table %] where @table is the variable that identifies the model input.
The result of the query will be added as a new layer.
See also
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Additional input datasources (called input1, .., inputN in the query) |
|
[vector: any] [list] |
List of layers to query. In the SQL editor you can refer these layers with their real name or also with input1, input2, inputN depending on how many layers have been chosen. |
SQL query |
|
[string] |
Type the string of your SQL query, e.g.
|
Unique identifier field Optional |
|
[string] |
Specify the column with unique ID |
Geometry field Optional |
|
[string] |
Specify the geometry field |
Geometry type Optional |
|
[enumeration] Default: 0 |
Choose the geometry of the result. By default the algorithm will autodetect it. One of:
|
CRS Optional |
|
[crs] |
The CRS to assign to the output layer |
SQL Output |
|
[vector: any] Default: |
Specify the output layer created by the query. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
SQL Output |
|
[vector: any] |
Vector layer created by the query |
Python code
Algorithm ID: qgis:executesql
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.13. Export layers to DXF
NEW in 3.18
Exports layers to DXF file. For each layer, you can choose a field whose values are used to split features in generated destination layers in DXF output.
See also
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layers |
|
[vector: any][list] |
Input vector layers to export |
Symbology mode |
|
[enumeration] Default: 0 |
Type of symbology to apply to output layers. You can choose between:
|
Symbology scale |
|
[scale] Default: 1:1 000 000 |
Default scale of data export. |
Encoding |
|
[enumeration] |
Encoding to apply to layers. |
CRS |
|
[crs] |
Choose the CRS for the output layer. |
Use layer title as name |
|
[boolean] Default: False |
Name the output layer with the layer title (as set in QGIS) instead of the layer name. |
Force 2D |
|
[boolean] Default: False |
|
Export labels as MTEXT elements |
|
[boolean] Default: False |
Exports labels as MTEXT or TEXT elements |
DXF |
|
[file] Default: |
Specification of the output DXF file. One of:
|
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
DXF |
|
[file] |
|
Python code
Algorithm ID: native:dxfexport
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.14. Extract selected features
Saves the selected features as a new layer.
Note
If the selected layer has no selected features, the newly created layer will be empty.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Layer to save the selection from |
Selected features |
|
[same as input] Default: |
Specify the vector layer for the selected features. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Selected features |
|
[same as input] |
Vector layer with only the selected features, or no feature if none was selected. |
Python code
Algorithm ID: native:saveselectedfeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.15. Extract Shapefile encoding
Extracts the attribute encoding information embedded in a Shapefile.
Both the encoding specified by an optional .cpg file and
any encoding details present in the .dbf LDID header block are considered.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
ESRI Shapefile ( |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Shapefile encoding |
|
[string] |
Encoding information specified in the input file |
CPG encoding |
|
[string] |
Encoding information specified in any optional |
LDID encoding |
|
[string] |
Encoding information specified in |
Python code
Algorithm ID: native:shpencodinginfo
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.16. Find projection
Creates a shortlist of candidate coordinate reference systems, for instance for a layer with an unknown projection.
The area that the layer is expected to cover must be specified via the target area parameter. The coordinate reference system for this target area must be known to QGIS.
The algorithm operates by testing the layer’s extent in every known reference system and then listing any for which the bounds would be near the target area if the layer was in this projection.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Layer with unknown projection |
Target area for layer (xmin, xmax, ymin, ymax) |
|
[extent] |
The area that the layer covers. Available methods are:
|
CRS candidates |
|
[table] Default: |
Specify the table (geometryless layer) for the CRS suggestions (EPSG codes). One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
CRS candidates |
|
[table] |
A table with all the CRS (EPSG codes) of the matching criteria. |
Python code
Algorithm ID: qgis:findprojection
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.17. Flatten relationship
Flattens a relationship for a vector layer, exporting a single layer containing one parent feature per related child feature. This master feature contains all the attributes for the related features. This allows to have the relation as a plain table that can be e.g. exported to CSV.
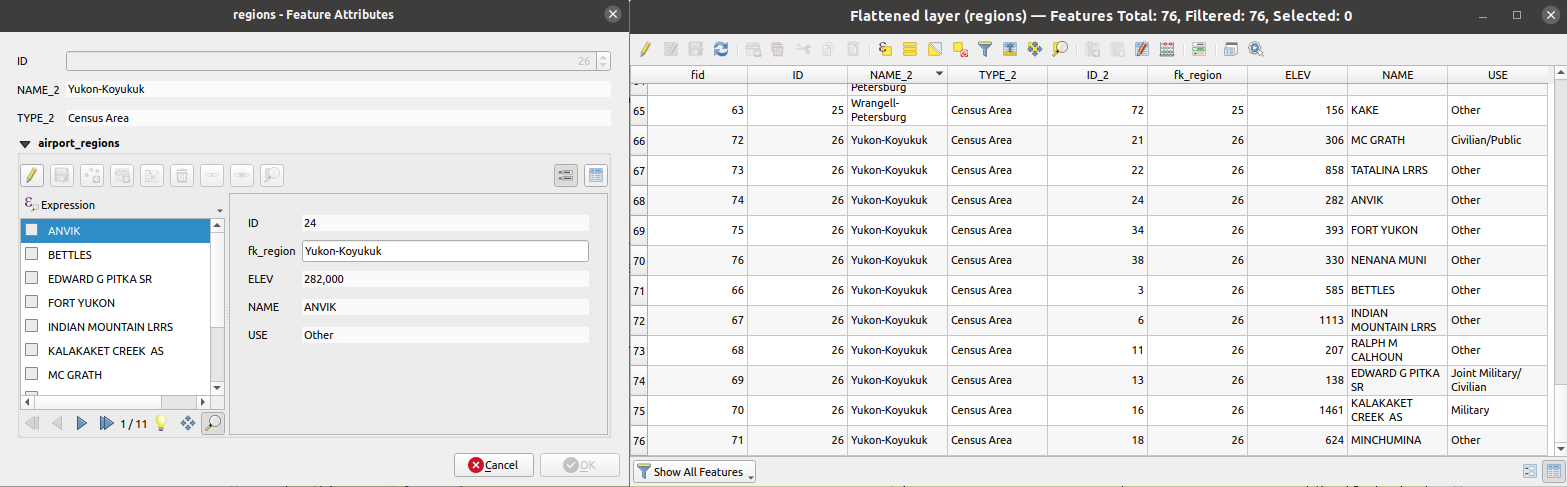
Fig. 25.45 Form of a region with related children (left) - A duplicate region feature for each related child, with joined attributes (right)
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Layer with the relationship that should be de-normalized |
Flattened Layer Optional |
|
[same as input] Default: |
Specify the output (flattened) layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Flattened layer |
|
[same as input] |
A layer containing master features with all the attributes for the related features |
Python code
Algorithm ID: native:flattenrelationships
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.18. Join attributes by field value
Takes an input vector layer and creates a new vector layer that is an extended version of the input one, with additional attributes in its attribute table.
The additional attributes and their values are taken from a second vector layer. An attribute is selected in each of them to define the join criteria.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Input vector layer. The output layer will consist of the features of this layer with attributes from matching features in the second layer. |
Table field |
|
[tablefield: any] |
Field of the source layer to use for the join |
Input layer 2 |
|
[vector: any] |
Layer with the attribute table to join |
Table field 2 |
|
[tablefield: any] |
Field of the second (join) layer to use for the join The type of the field must be equal to (or compatible with) the input table field type. |
Layer 2 fields to copy Optional |
|
[tablefield: any] [list] |
Select the specific fields you want to add. By default all the fields are added. |
Join type |
|
[enumeration] Default: 1 |
The type of the final joined layer. One of:
|
Discard records which could not be joined |
|
[boolean] Default: True |
Check if you don’t want to keep the features that could not be joined |
Joined field prefix Optional |
|
[string] |
Add a prefix to joined fields in order to easily identify them and avoid field name collision |
Joined layer |
|
[same as input] Default: |
Specify the output vector layer for the join. One of:
The file encoding can also be changed here. |
Unjoinable features from first layer |
|
[same as input] Default: |
Specify the output vector layer for unjoinable features from first layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Number of joined features from input table |
|
[number] |
|
Unjoinable features from first layer Optional |
|
[same as input] |
Vector layer with the non-matched features |
Joined layer |
|
[same as input] |
Output vector layer with added attributes from the join |
Number of unjoinable features from input table Optional |
|
[number] |
Python code
Algorithm ID: native:joinattributestable
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.19. Join attributes by location
Takes an input vector layer and creates a new vector layer that is an extended version of the input one, with additional attributes in its attribute table.
The additional attributes and their values are taken from a second vector layer. A spatial criteria is applied to select the values from the second layer that are added to each feature from the first layer.
Default menu:
See also
Join attributes by nearest, Join attributes by field value, Join attributes by location (summary)
Exploring spatial relations
Geometric predicates are boolean functions used to determine the spatial relation a feature has with another by comparing whether and how their geometries share a portion of space.
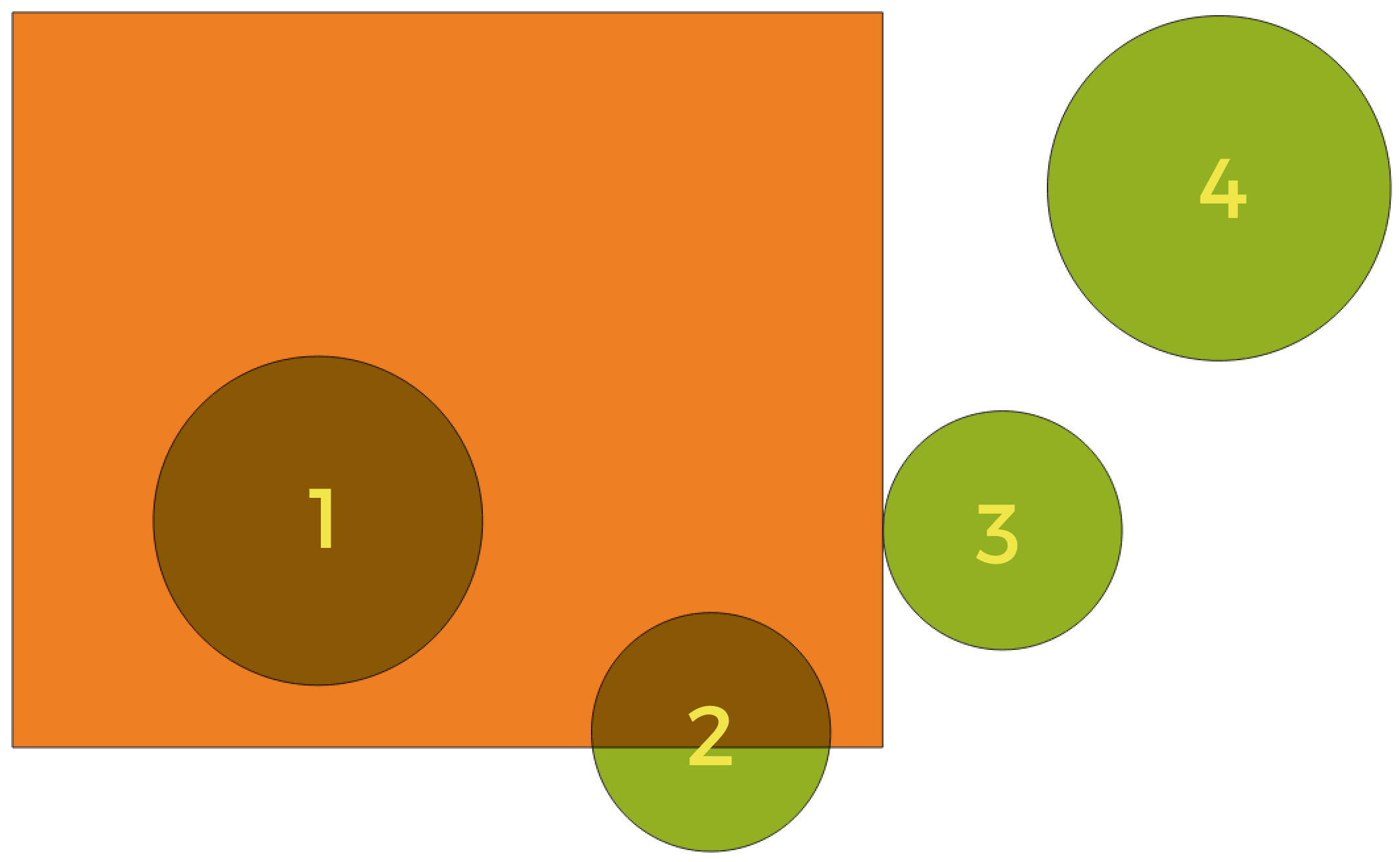
Fig. 25.46 Looking for spatial relations between layers
Using the figure above, we are looking for the green circles by spatially comparing them to the orange rectangle feature. Available geometric predicates are:
- Intersect
Tests whether a geometry intersects another. Returns 1 (true) if the geometries spatially intersect (share any portion of space - overlap or touch) and 0 if they don’t. In the picture above, this will return circles 1, 2 and 3.
- Contain
Returns 1 (true) if and only if no points of b lie in the exterior of a, and at least one point of the interior of b lies in the interior of a. In the picture, no circle is returned, but the rectangle would be if you would look for it the other way around, as it contains circle 1 completely. This is the opposite of are within.
- Disjoint
Returns 1 (true) if the geometries do not share any portion of space (no overlap, not touching). Only circle 4 is returned.
- Equal
Returns 1 (true) if and only if geometries are exactly the same. No circles will be returned.
- Touch
Tests whether a geometry touches another. Returns 1 (true) if the geometries have at least one point in common, but their interiors do not intersect. Only circle 3 is returned.
- Overlap
Tests whether a geometry overlaps another. Returns 1 (true) if the geometries share space, are of the same dimension, but are not completely contained by each other. Only circle 2 is returned.
- Are within
Tests whether a geometry is within another. Returns 1 (true) if geometry a is completely inside geometry b. Only circle 1 is returned.
- Cross
Returns 1 (true) if the supplied geometries have some, but not all, interior points in common and the actual crossing is of a lower dimension than the highest supplied geometry. For example, a line crossing a polygon will cross as a line (true). Two lines crossing will cross as a point (true). Two polygons cross as a polygon (false). In the picture, no circles will be returned.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Input vector layer. The output layer will consist of the features of this layer with attributes from matching features in the second layer. |
Join layer |
|
[vector: any] |
The attributes of this vector layer will be added to the source layer attribute table. |
Geometric predicate |
|
[enumeration] [list] Default: [0] |
Select the geometric criteria. One or more of:
|
Fields to add (leave empty to use all fields) Optional |
|
[tablefield: any] [list] |
Select the specific fields you want to add. By default all the fields are added. |
Join type |
|
[enumeration] |
The type of the final joined layer. One of:
|
Discard records which could not be joined |
|
[boolean] Default: False |
Remove from the output the input layer records which could not be joined |
Joined field prefix Optional |
|
[string] |
Add a prefix to joined fields in order to easily identify them and avoid field name collision |
Joined layer |
|
[same as input] Default: |
Specify the output vector layer for the join. One of:
The file encoding can also be changed here. |
Unjoinable features from first layer |
|
[same as input] Default: |
Specify the output vector layer for unjoinable features from first layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Number of joined features from input table |
|
[number] |
|
Unjoinable features from first layer Optional |
|
[same as input] |
Vector layer of the non-matched features |
Joined layer |
|
[same as input] |
Output vector layer with added attributes from the join |
Python code
Algorithm ID: native:joinattributesbylocation
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.20. Join attributes by location (summary)
Takes an input vector layer and creates a new vector layer that is an extended version of the input one, with additional attributes in its attribute table.
The additional attributes and their values are taken from a second vector layer. A spatial criteria is applied to select the values from the second layer that are added to each feature from the first layer.
The algorithm calculates a statistical summary for the values from matching features in the second layer (e.g. maximum value, mean value, etc).
See also
Exploring spatial relations
Geometric predicates are boolean functions used to determine the spatial relation a feature has with another by comparing whether and how their geometries share a portion of space.
Fig. 25.47 Looking for spatial relations between layers
Using the figure above, we are looking for the green circles by spatially comparing them to the orange rectangle feature. Available geometric predicates are:
- Intersect
Tests whether a geometry intersects another. Returns 1 (true) if the geometries spatially intersect (share any portion of space - overlap or touch) and 0 if they don’t. In the picture above, this will return circles 1, 2 and 3.
- Contain
Returns 1 (true) if and only if no points of b lie in the exterior of a, and at least one point of the interior of b lies in the interior of a. In the picture, no circle is returned, but the rectangle would be if you would look for it the other way around, as it contains circle 1 completely. This is the opposite of are within.
- Disjoint
Returns 1 (true) if the geometries do not share any portion of space (no overlap, not touching). Only circle 4 is returned.
- Equal
Returns 1 (true) if and only if geometries are exactly the same. No circles will be returned.
- Touch
Tests whether a geometry touches another. Returns 1 (true) if the geometries have at least one point in common, but their interiors do not intersect. Only circle 3 is returned.
- Overlap
Tests whether a geometry overlaps another. Returns 1 (true) if the geometries share space, are of the same dimension, but are not completely contained by each other. Only circle 2 is returned.
- Are within
Tests whether a geometry is within another. Returns 1 (true) if geometry a is completely inside geometry b. Only circle 1 is returned.
- Cross
Returns 1 (true) if the supplied geometries have some, but not all, interior points in common and the actual crossing is of a lower dimension than the highest supplied geometry. For example, a line crossing a polygon will cross as a line (true). Two lines crossing will cross as a point (true). Two polygons cross as a polygon (false). In the picture, no circles will be returned.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Input vector layer. The output layer will consist of the features of this layer with attributes from matching features in the second layer. |
Join layer |
|
[vector: any] |
The attributes of this vector layer will be added to the source layer attribute table. |
Geometric predicate |
|
[enumeration] [list] Default: [0] |
Select the geometric criteria. One or more of:
|
Fields to summarize (leave empty to use all fields) Optional |
|
[tablefield: any] [list] |
Select the specific fields you want to add and summarize. By default all the fields are added. |
Summaries to calculate (leave empty to use all fields) Optional |
|
[enumeration] [list] Default: [] |
Choose which type of summary you want to add to each field and for each feature. One or more of:
|
Discard records which could not be joined |
|
[boolean] Default: False |
Remove from the output the input layer records which could not be joined |
Joined layer |
|
[same as input] Default: |
Specify the output vector layer for the join. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Joined layer |
|
[same as input] |
Output vector layer with summarized attributes from the join |
Python code
Algorithm ID: qgis:joinbylocationsummary
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.21. Join attributes by nearest
Takes an input vector layer and creates a new vector layer with additional fields in its attribute table. The additional attributes and their values are taken from a second vector layer. Features are joined by finding the closest features from each layer.
By default only the nearest feature is joined, but the join can also join to the k-nearest neighboring features.
If a maximum distance is specified, only features which are closer than this distance will be matched.
See also
Nearest neighbour analysis, Join attributes by field value, Join attributes by location, Distance matrix
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input layer |
|
[vector: any] |
The input layer. |
Input layer 2 |
|
[vector: any] |
The join layer. |
Layer 2 fields to copy (leave empty to copy all fields) |
|
[fields] |
Join layer fields to copy (if empty, all fields will be copied). |
Discard records which could not be joined |
|
[boolean] Default: False |
Remove from the output the input layer records which could not be joined |
Joined field prefix |
|
[string] |
Joined field prefix |
Maximum nearest neighbors |
|
[number] Default: 1 |
Maximum number of nearest neighbors |
Maximum distance |
|
[number] |
Maximum search distance |
Joined layer |
|
[same as input] Default: |
Specify the vector layer containing the joined features. One of:
The file encoding can also be changed here. |
Unjoinable features from first layer |
|
[same as input] Default: |
Specify the vector layer containing the features that could not be joined. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Joined layer |
|
[same as input] |
The output joined layer. |
Unjoinable features from first layer |
|
[same as input] |
Layer containing the features from first layer that could not be joined to any features in the join layer. |
Number of joined features from input table |
|
[number] |
Number of features from the input table that have been joined. |
Number of unjoinable features from input table |
|
[number] |
Number of features from the input table that could not be joined. |
Python code
Algorithm ID: native:joinbynearest
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.22. Merge vector layers
Combines multiple vector layers of the same geometry type into a single one.
The attribute table of the resulting layer will contain the fields from all input layers. If fields with the same name but different types are found then the exported field will be automatically converted into a string type field. New fields storing the original layer name and source are also added.
If any input layers contain Z or M values, then the output layer will also contain these values. Similarly, if any of the input layers are multi-part, the output layer will also be a multi-part layer.
Optionally, the destination coordinate reference system (CRS) for the merged layer can be set. If it is not set, the CRS will be taken from the first input layer. All layers will be reprojected to match this CRS.
Default menu:
See also
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layers |
|
[vector: any] [list] |
The layers that are to be merged into a single layer. Layers should be of the same geometry type. |
Destination CRS Optional |
|
[crs] |
Choose the CRS for the output layer. If not specified, the CRS of the first input layer is used. |
Merged |
|
[same as input] Default: |
Specify the output vector layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Merged |
|
[same as input] |
Output vector layer containing all the features and attributes from the input layers. |
Python code
Algorithm ID: native:mergevectorlayers
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.23. Order by expression
Sorts a vector layer according to an expression: changes the feature index according to an expression.
Be careful, it might not work as expected with some providers, the order might not be kept every time.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Input vector layer to sort |
Expression |
|
[expression] |
Expression to use for the sorting |
Sort ascending |
|
[boolean] Default: True |
If checked the vector layer will be sorted from small to large values. |
Sort nulls first |
|
[boolean] Default: False |
If checked, Null values are placed first |
Ordered |
|
[same as input] Default: |
Specify the output vector layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Ordered |
|
[same as input] |
Output (sorted) vector layer |
Python code
Algorithm ID: native:orderbyexpression
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.24. Repair Shapefile
Repairs a broken ESRI Shapefile dataset by (re)creating the SHX file.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Shapefile |
|
[file] |
Full path to the ESRI Shapefile dataset with a missing or broken SHX file |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Repaired layer |
|
[vector: any] |
The input vector layer with the SHX file repaired |
Python code
Algorithm ID: native:repairshapefile
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.25. Reproject layer
Reprojects a vector layer in a different CRS. The reprojected layer will have the same features and attributes of the input layer.
Allows features in-place modification
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Input vector layer to reproject |
Target CRS |
|
[crs] Default: |
Destination coordinate reference system |
Coordinate Operation Optional |
|
[string] |
Specific operation to use for a particular reprojection task, instead of always forcing use of the current project’s transformation settings. Useful when reprojecting a particular layer and control over the exact transformation pipeline is required. Requires proj version >= 6. Read more at Datum Transformations. |
Reprojected |
|
[same as input] Default: |
Specify the output vector layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Reprojected |
|
[same as input] |
Output (reprojected) vector layer |
Python code
Algorithm ID: native:reprojectlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.26. Save vector features to file
Saves vector features to a specified file dataset.
For dataset formats supporting layers, an optional layer name parameter can be used to specify a custom string. Optional GDAL-defined dataset and layer options can be specified. For more information on this, read the online GDAL documentation on the format.
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Vector features |
|
[vector: any] |
Input vector layer. |
Saved features |
|
[same as input] Default: |
Specify the file to save the features to. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Layer name Optional |
|
[string] |
Name to use for the output layer |
GDAL dataset options Optional |
|
[string] |
GDAL dataset creation options of the output format. Separate individual options with semicolons. |
GDAL layer options Optional |
|
[string] |
GDAL layer creation options of the output format. Separate individual options with semicolons. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Saved features |
|
[same as input] |
Vector layer with the saved features. |
File name and path |
|
[string] |
Output file name and path. |
Layer name |
|
[string] |
Name of the layer, if any. |
Python code
Algorithm ID: native:savefeatures
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.27. Set layer encoding
Sets the encoding used for reading a layer’s attributes. No permanent changes are made to the layer, rather it affects only how the layer is read during the current session.
Note
Changing the encoding is only supported for some vector layer data sources.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Saved features |
|
[vector: any] |
Vector layer to set the encoding. |
Encoding |
|
[string] |
Text encoding to assign to the layer in the current QGIS session. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output layer |
|
[same as input] |
Input vector layer with the set encoding. |
Python code
Algorithm ID: native:setlayerencoding
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.28. Split features by character
Features are split into multiple output features by splitting a field’s value at a specified character. For instance, if a layer contains features with multiple comma separated values contained in a single field, this algorithm can be used to split these values up across multiple output features. Geometries and other attributes remain unchanged in the output. Optionally, the separator string can be a regular expression for added flexibility.
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Input vector layer |
Split using values in the field |
|
[tablefield: any] |
Field to use for splitting |
Split value using character |
|
[string] |
Character to use for splitting |
Use regular expression separator |
|
[boolean] Default: False |
|
Split |
|
[same as input] Default: |
Specify output vector layer. One of:
The file encoding can also be changed here. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Split |
|
[same as input] |
The output vector layer. |
Python code
Algorithm ID: native:splitfeaturesbycharacter
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.29. Split vector layer
Creates a set of vectors in an output folder based on an input layer and an attribute. The output folder will contain as many layers as the unique values found in the desired field.
The number of files generated is equal to the number of different values found for the specified attribute.
It is the opposite operation of merging.
Default menu:
See also
Parameters
Basic parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Input vector layer |
Unique ID field |
|
[tablefield: any] |
Field to use for splitting |
Output directory |
|
[folder] Default: |
Specify the directory for the output layers. One of:
|
Advanced parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Output file type Optional |
|
[enumeration] Default: |
Select the extension of the output files. If not specified or invalid, the output files format will be the one set in the “Default output vector layer extension” Processing setting. |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Output directory |
|
[folder] |
The directory for the output layers |
Output layers |
|
[same as input] [list] |
The output vector layers resulting from the split. |
Python code
Algorithm ID: native:splitvectorlayer
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.
25.1.17.30. Truncate table
Truncates a layer, by deleting all features from within the layer.
Warning
This algorithm modifies the layer in place, and deleted features cannot be restored!
Parameters
Label |
Name |
Type |
Description |
|---|---|---|---|
Input Layer |
|
[vector: any] |
Input vector layer |
Outputs
Label |
Name |
Type |
Description |
|---|---|---|---|
Truncated layer |
|
[folder] |
The truncated (empty) layer |
Python code
Algorithm ID: native:truncatetable
import processing
processing.run("algorithm_id", {parameter_dictionary})
The algorithm id is displayed when you hover over the algorithm in the Processing Toolbox. The parameter dictionary provides the parameter NAMEs and values. See Using processing algorithms from the console for details on how to run processing algorithms from the Python console.