중요
번역은 여러분이 참여할 수 있는 커뮤니티 활동입니다. 이 페이지는 현재 90.91% 번역되었습니다.
15.1. 수업: 데이터베이스의 기초
PostgreSQL을 사용해보기 전에, 일반적인 데이터베이스 이론으로 기초를 다지도록 합시다. 어떤 예제 코드도 입력할 필요 없습니다. 모든 코드는 오직 설명을 목적으로 합니다.
이 수업의 목표: 핵심적인 데이터베이스 개념들을 이해하기.
15.1.1. 데이터베이스란 무엇일까요?
데이터베이스는 하나 또는 그 이상의 용도로 쓰이는, 일반적으로 디지털 형태인, 데이터의 조직화된 집합으로 이루어진다. - 위키백과
DBMS(데이터베이스 관리 시스템)는 저장소, 접속, 보안, 백업 및 기타 기능을 제공하는, 데이터베이스를 조작하는 소프트웨어로 이루어진다. - 위키백과
15.1.2. 테이블
관계형 데이터베이스 및 플랫 파일 데이터베이스에서, 테이블이란 (이름으로 식별되는) 수직 열과 수평 행 모델을 사용해 조직된 데이터 요소(값)들의 집합이다. 테이블의 열은 지정된 개수이지만, 행은 무한대로 확장될 수 있다. 각 행은 후보 키라고 식별되는 특정 열 하위 집합에 나타나는 값으로 식별된다. - 위키백과
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
SQL 데이터베이스에서는 테이블을 관계 라고도 합니다.
15.1.3. 열/필드
열이란 테이블의 각 행의 하나씩을 차지하는, 특정 단순 유형 데이터 값들의 집합이다. 열은 어떤 행들로 이루어지느냐에 따르는 구조를 제공한다. 필드라는 용어는 종종 열과 바꿔 쓰이기도 하지만, 많은 이들은 필드(또는 필드 값)를 한 행과 한 열의 교차 지점에 있는 단일 값을 특별히 지칭하는 용어라고 간주한다. - 위키백과
열 :
| name |
+-------+
| Tim |
| Horst |
필드 :
| Horst |
15.1.4. 레코드
레코드란 테이블의 행에 저장된 정보를 말합니다. 각 레코드는 테이블에 있는 각 열의 필드를 차지하게 됩니다.
2 | Horst | 88 <-- one record
15.1.5. 데이터형
데이터형이란 열에 저장될 수 있는 정보의 유형을 제한한다. - 팀(Tim)과 호르스트(Horst)
여러 유형의 데이터형이 있습니다. 가장 흔히 쓰이는 데이터형에 대해 알아봅시다:
문자열(string)- 자유 서식 텍스트 데이터를 저장정수(integer)- 범자연수(whole number)를 저장실수(real)- 십진수(decimal number)를 저장날짜(date)- 아무도 잊지 않도록 호르스트(Horst)의 생일을 저장불(boolean)- 단순한 참/거짓 값을 저장
데이터베이스가 필드에 아무것도 저장하지 않도록 할 수도 있습니다. 필드에 아무것도 없을 경우, 필드의 내용을 ‘널(Null)’ 값 이라고 합니다:
insert into person (age) values (40);
select * from person;
결과:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
더 많은 데이터형을 사용할 수 있습니다. PostgreSQL 매뉴얼을 살펴보세요!
15.1.6. 주소 데이터베이스 모델 작업
간단한 예제를 통해 데이터베이스가 어떻게 구성되는지 알아봅시다. 주소 데이터베이스를 생성하겠습니다.
★☆☆ 혼자서 해보세요:
단순한 주소를 적어보고, 어떤 요소로 이루어져 있는지 그리고 데이터베이스에 어떤 요소를 저장해야 할지 생각해보십시오.
해답
이 이론적인 주소 테이블에 다음 속성들을 저장하길 원할 수도 있겠죠:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
주소 객체를 표현하는 테이블을 생성할 때, 이 속성들 각각을 나타내는 열들을 생성하고 SQL을 준수하며 가능하면 단축시킨 이름을 지정할 것입니다:
house_number
street_name
suburb
city
postcode
country
주소의 구조
주소를 표현하는 요소가 곧 열입니다. 각 열에 저장되는 데이터의 유형이 곧 데이터형입니다. 다음 단계에서 이 개념적인 주소 테이블을 분석해서 어떻게 향상시킬 수 있는지 알아보겠습니다!
15.1.7. 데이터베이스 이론
데이터베이스를 생성하는 과정은 실제 세계의 모형을 생성하는 것입니다. 실제 세계의 개념을 취해서 데이터베이스에 엔티티(entity)로서 표현하는 것입니다.
15.1.8. 정규화
데이터베이스의 주요 아이디어 가운데 하나는 데이터의 복제/중복을 피하자는 것입니다. 데이터베이스에서 중복을 제거하는 과정을 정규화(normalization)라고 합니다.
정규화란 데이터베이스의 구조가 범용 쿼리에 적합한지 그리고 데이터 무결성을 잃을 수 있는 바람직하지 않은 특성들 — 삽입, 업데이트 및 삭제 이상 — 을 피하는 데 적합한지 확인하는 체계적인 방법이다. - 위키백과
정규화 ‘형태’에는 서로 다른 유형들이 있습니다.
간단한 예를 살펴봅시다:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
동일한 도로 이름 또는 도시 이름을 가진 친구들이 많다고 상상해보십시오. 이 데이터가 복제될 때마다 용량을 소비하게 됩니다. 더구나 도시 이름이 바뀔 경우, 데이터베이스를 업데이트하기 위해 많은 작업을 해야 합니다.
15.1.9. ★☆☆ 혼자서 해보세요:
Redesign the theoretical people table above to reduce duplication and to
normalise the data structure.
여기 에서 데이터베이스 정규화에 대해 더 읽어볼 수 있습니다.
해답
The major problem with the people table is that there is a single address
field which contains a person’s entire address. Thinking about our theoretical
address table earlier in this lesson, we know that an address is made up of
many different properties. By storing all these properties in one field, we make
it much harder to update and query our data. We therefore need to split the
address field into the various properties. This would give us a table which has
the following structure:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
다음 절에서 이 데이터베이스의 구조를 한 단계 더 향상시키기 위해 이 예제에 사용할 수 있는 외래 키(Foreign Key) 관계에 대해 배울 것입니다.
15.1.10. 인덱스
데이터베이스 인덱스란 데이터베이스 테이블 상에서 데이터 검색 작업의 속도를 향상시키는 데이터 구조이다. - 위키백과
교과서를 읽다가 어떤 개념에 대한 설명을 찾는다고 상상해보십시오 — 그런데 교과서에 색인이 없군요! 여러분은 필요한 정보를 찾을 때까지 표지부터 책 전체를 다시 훑어야 할 겁니다. 책의 끝부분에 있는 색인은 관련 정보가 있는 페이지를 빨리 찾을 수 있게 해줍니다:
create index person_name_idx on people (name);
이제 이름 검색이 빨라질 겁니다:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. 시퀀스
시퀀스란 유일 숫자 생성기입니다. 보통 테이블의 어떤 열을 위한 유일한 식별자를 생성하는 데 쓰입니다.
이 예제에서는 id 가 시퀀스입니다. 테이블에 레코드가 추가될 때마다 숫자가 증가합니다:
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. 엔티티 관계 도표
In a normalised database, you typically have many relations (tables). The
entity-relationship diagram (ER Diagram) is used to design the logical
dependencies between the relations. Consider our non-normalised people table
from earlier in the lesson:
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
같은 거리에 사는 개인들에 대해 도로 이름을 반복할 필요가 없도록 이 테이블을 손쉽게 두 테이블로 분할할 수 있습니다:
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
이렇게 하면:
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
We can then link the two tables using the ‘keys’ streets.id and
people.streets_id.
이 두 테이블에 대해 ER 도표를 그린다면 다음과 같이 보일 것입니다:

ER 도표를 통해 ‘일대다(one to many)’ 관계를 표현할 수 있습니다. 이 예제에서 화살표는 한 도로에 많은 사람이 살 수 있다는 사실을 보여줍니다.
★★☆ 혼자서 해보세요:
이 ‘people’ 모델에는 아직 몇몇 정규화 문제가 남아 있습니다. 사용자 스스로 더 정규화를 진행시킬 수 있을지 생각해보고, ER 도표로 사용자의 생각을 표현해보십시오.
해답
Our people table currently looks like this:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
The street_id column represents a ‘one to many’ relationship between the
people object and the related street object, which is in the streets table.
이 테이블을 한 단계 더 정규화하는 방법 가운데 하나는 이름 필드를 first_name 과 last_name 으로 분할하는 것입니다:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
We can also create separate tables for the town or city name and country,
linking them to our people table via ‘one to many’ relationships:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
이를 표현하는 ER 도표는 다음과 같이 보일 것입니다:
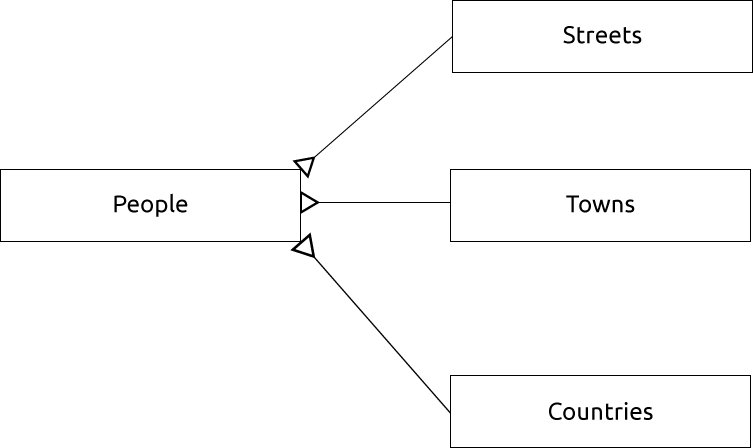
15.1.13. 제약 조건, 기본 키, 외래 키
A database constraint is used to ensure that data in a relation matches the
modeller’s view of how that data should be stored. For example a constraint on
your postal code could ensure that the number falls between 1000 and
9999.
기본 키(Primary Key)는 레코드를 유일하게 만들어주는 하나 이상의 필드 값입니다. 기본 키를 보통 id 라고 하며, 시퀀스인 경우가 대부분입니다.
외래 키(Foreign Key)는 다른 테이블에 있는 유일한 레코드를 (해당 테이블의 기본 키를 사용해서) 참조하는 데 쓰입니다.
ER 도표를 그릴 때, 테이블 사이의 연결은 보통 기본 키와 연결되는 외래 키에 기반합니다.
이 ‘people’ 예제를 보면, 테이블 정의에서 street 열이 streets 테이블의 기본 키를 참조하는 외래 키라는 사실을 보여주고 있습니다:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. 트랜잭션
데이터베이스에서 데이터를 추가, 변경, 삭제할 때 뭔가 문제가 발생해도 데이터베이스는 언제나 양호한 상태로 남아 있어야 합니다. 대부분의 데이터베이스는 트랜잭션 지원이라는 기능을 제공합니다. 트랜잭션은 데이터베이스에 대한 여러분의 수정 작업이 계획대로 되지 않았을 경우 되돌아갈 수 있는 복원 지점을 생성할 수 있게 해줍니다.
여러분이 은행 계좌 시스템을 가지고 있다고 생각해보십시오. 어떤 계좌에서 다른 계좌로 자금을 전송해야 합니다. 이 일련의 단계를 다음과 같이 가정해볼 수 있습니다:
조에게서 R20을 출금
앤에게 R20을 입금
이 과정에서 무언가 (정전 같은) 문제가 생길 경우, 트랜잭션이 이전으로 복원될 것입니다.
15.1.15. 결론
데이터베이스는 단순한 코드 구조를 사용해서 데이터를 구조화된 방법으로 관리할 수 있게 해줍니다.
15.1.16. 다음은 무엇을 배우게 될까요?
이제 데이터베이스가 이론적으로 어떻게 작동하는지 알아봤으니, 지금 배운 이론을 구현할 수 있는 새 데이터베이스를 생성해봅시다.