Importante
A tradução é um esforço comunitário você pode contribuir. Esta página está atualmente traduzida em 82.95%.
15.1. Lesson: Introduction to Databases
Antes de usarmos o PostgreSQL, vamos ficar mais seguros cobrindo a teoria geral de banco de dados. Você não precisa entrar com nenhum código dos exemplos; eles estão lá somente com o propósito de ilustrar.
O objetivo desta lição: Compreender os conceitos fundamentais das bases de dados.
15.1.1. O que é um banco de dados?
Um banco de dados consiste em uma coleção organizada de dados para um ou mais usos, tipicamente na forma digital. - Wikipedia
Um sistema gerenciador de banco de dados (SGBD) consiste em um software que opera bases de dados, proporcionando o armazenamento, acesso, segurança, backup e outras facilidades. - Wikipedia
15.1.2. Tabelas
Em bancos de dados relacionais e bases de dados em arquivos simples, uma tabela é um conjunto de elementos de dados (valores) que estão organizados usando um modelo de colunas verticais (que são identificadas por seu nome) e linhas horizontais. Uma tabela tem um número específico de colunas, mas pode ter um número qualquer de linhas. Cada linha é identificada pelos valores que aparecem em um conjunto particular de colunas que tenham sido identificadas como chaves candidatas. - Wikipedia
id | name | age
----+-------+-----
1 | Tim | 20
2 | Horst | 88
(2 rows)
Em bancos de dados SQL, uma tabela é também conhecida como uma relação.
15.1.3. Colunas / Campos
Uma coluna é um conjunto de valores de um tipo particular de dados, um para cada linha da tabela. As colunas fornecem a estrutura com a qual as linhas são compostas. O termo “campo” é muitas vezes utilizado alternadamente com o termo “coluna”, embora muitos considerem mais correto usar campo (ou valor de campo) para se referir especificamente a um simples item que exista na interseção entre uma linha e uma coluna. - Wikipedia
Uma coluna:
| name |
+-------+
| Tim |
| Horst |
Um campo:
| Horst |
15.1.4. Registros
Um registro é a informação armazenada em uma linha da tabela. Cada registro terá um campo para cada coluna na tabela.
2 | Horst | 88 <-- one record
15.1.5. Tipos de dados
Tipos de dados restringem o tipo de informação que pode ser armazenado em uma coluna. - Tim and Horst
Existem várias classes de tipos de dados. Vamos focar nas mais comuns:
String- para armazenar dados de texto de forma livreInteger- para armazenar números inteirosReal- para armazenar números decinaisDate- para armazenar o aniversário de Horst para que ninguém esqueçaBoolean- para armazenar valores simples verdadeiros/falsos
Você pode dizer ao banco de dados para permitir que você também não armazene nada em um campo. Se não houver nada em um campo, o conteúdo do campo será referido como um ‘valor nulo’:
insert into person (age) values (40);
select * from person;
Resultado:
id | name | age
---+-------+-----
1 | Tim | 20
2 | Horst | 88
4 | | 40 <-- null for name
(3 rows)
Existem muitos outros tipos de dados que você pode usar - verifique o manual do PostgreSQL!
15.1.6. Modelando um banco de dados de Endereços
Vamos usar um estudo de caso simples para ver como um banco de dados é construído. Queremos criar um banco de dados de endereços.
★☆☆ Try Yourself:
Anote as propriedades que compõem um endereço simples e que gostariamos de armazenar em nosso banco de dados.
Responda
Para nossa tabela de endereços teórica, podemos querer armazenar as seguintes propriedades:
House Number
Street Name
Suburb Name
City Name
Postcode
Country
Ao criar a tabela para representar um objeto de endereço, criamos colunas para representar cada uma dessas propriedades e as nomeamos com nomes compatíveis com SQL e possivelmente abreviados:
house_number
street_name
suburb
city
postcode
country
Estrutura de endereço
As propriedades que descrevem um endereço são as colunas. O tipo das informações armazenadas em cada coluna é o seu tipo de dado. Na próxima seção vamos analisar nossa tabela de endereços conceitual para ver como podemos fazê-la melhor!
15.1.7. Teoria de banco de dados
O processo de criação de um banco de dados envolve a criação de um modelo do mundo real; tomando conceitos do mundo real e representando-os no banco de dados como entidades.
15.1.8. Normalização
Uma das principais idéias em um banco de dados é evitar a duplicação de dados / redundância. O processo de remoção de redundância de um banco de dados é chamado de Normalização.
A normalização é uma forma sistemática de garantir que a estrutura do banco de dados é adequada para uso geral de consulta e isento de certas características indesejáveis - anomalias na inserção, atualização e exclusão - que poderia levar a uma perda de integridade dos dados. * - * Wikipedia
Existem diferentes ‘formas’ de normalização.
Vamos ver um exemplo simples:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
select * from people;
id | name | address | phone_no
---+---------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duester | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Imagine que você tem muitos amigos com o mesmo nome de rua ou cidade. Cada vez que os dados são duplicados, consome-se espaço. Pior ainda, se um nome de cidade muda, você tem que fazer um monte de trabalho para atualizar seu banco de dados.
15.1.9. ★☆☆ Try Yourself:
Redesign the theoretical people table above to reduce duplication and to
normalise the data structure.
Você pode ler mais sobre a normalização do banco de dados aqui
Responda
The major problem with the people table is that there is a single address
field which contains a person’s entire address. Thinking about our theoretical
address table earlier in this lesson, we know that an address is made up of
many different properties. By storing all these properties in one field, we make
it much harder to update and query our data. We therefore need to split the
address field into the various properties. This would give us a table which has
the following structure:
id | name | house_no | street_name | city | phone_no
--+---------------+----------+----------------+------------+-----------------
1 | Tim Sutton | 3 | Buirski Plein | Swellendam | 071 123 123
2 | Horst Duester | 4 | Avenue du Roix | Geneva | 072 121 122
Na próxima seção, você aprenderá sobre os relacionamentos de chave estrangeira que podem ser usados neste exemplo para melhorar ainda mais a estrutura do nosso banco de dados.
15.1.10. Índices
Um índice de banco de dados é uma estrutura de dados que aumenta a velocidade da operação de recuperação de dados de uma tabela de banco de dados. * - * Wikipedia
Imagine que você está lendo um livro e procurando a explicação de um conceito - e o livro não tem índice! Você terá que começar a ler em uma capa e percorrer todo o livro até encontrar as informações necessárias. O índice na parte de trás de um livro ajuda você a pular rapidamente para a página com as informações relevantes:
create index person_name_idx on people (name);
Now searches on name will be faster:
Table "public.people"
Column | Type | Modifiers
----------+------------------------+-------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
| |
name | character varying(50) |
address | character varying(200) | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
"person_name_idx" btree (name)
15.1.11. Sequencias
Uma sequência é um gerador de número único. É normalmente utilizado para criar um identificador único para uma coluna na tabela.
Neste exemplo, id é uma sequência - o número é incrementado toda vez que um registro é adicionado à tabela:
id | name | address | phone_no
---+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
15.1.12. Diagrama Entidade-relacionamento
In a normalised database, you typically have many relations (tables). The
entity-relationship diagram (ER Diagram) is used to design the logical
dependencies between the relations. Consider our non-normalised people table
from earlier in the lesson:
select * from people;
id | name | address | phone_no
----+--------------+-----------------------------+-------------
1 | Tim Sutton | 3 Buirski Plein, Swellendam | 071 123 123
2 | Horst Duster | 4 Avenue du Roix, Geneva | 072 121 122
(2 rows)
Com um pouco de trabalho, podemos dividi-lo em duas tabelas, eliminando a necessidade de repetir o nome da rua para pessoas que moram na mesma rua:
select * from streets;
id | name
----+--------------
1 | Plein Street
(1 row)
e:
select * from people;
id | name | house_no | street_id | phone_no
----+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
(1 row)
We can then link the two tables using the ‘keys’ streets.id and
people.streets_id.
Se desenharmos um Diagrama ER para essas duas tabelas, será algo parecido com isto:

O Diagrama ER nos ajuda a expressar relacionamentos “um para muitos”. Neste caso, o símbolo de seta mostra que uma rua pode ter muitas pessoas vivendo nela.
★★☆ Try Yourself:
Nosso modelo people ainda tem alguns problemas de normalização - veja se você consegue normalizá-lo ainda mais e representá-lo por meio de um Diagrama ER.
Responda
Our people table currently looks like this:
id | name | house_no | street_id | phone_no
---+--------------+----------+-----------+-------------
1 | Horst Duster | 4 | 1 | 072 121 122
The street_id column represents a ‘one to many’ relationship between the
people object and the related street object, which is in the streets table.
Uma maneira de normalizar ainda mais a tabela é dividir o campo de nome em primeiro_nome e último_nome:
id | first_name | last_name | house_no | street_id | phone_no
---+------------+------------+----------+-----------+------------
1 | Horst | Duster | 4 | 1 | 072 121 122
We can also create separate tables for the town or city name and country,
linking them to our people table via ‘one to many’ relationships:
id | first_name | last_name | house_no | street_id | town_id | country_id
---+------------+-----------+----------+-----------+---------+------------
1 | Horst | Duster | 4 | 1 | 2 | 1
Um diagrama ER para representar isso ficaria assim:
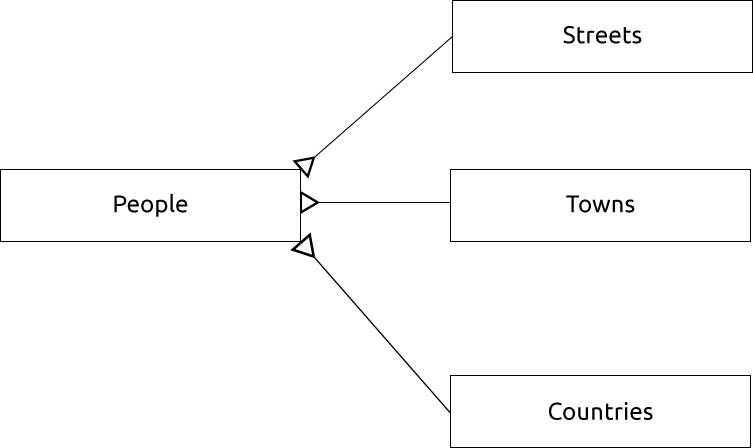
15.1.13. Restrições, Chaves Primárias e Chaves Estrangeiras
A database constraint is used to ensure that data in a relation matches the
modeller’s view of how that data should be stored. For example a constraint on
your postal code could ensure that the number falls between 1000 and
9999.
Uma chave primária é composta de um ou mais valores de campo que tornam um registro único. Normalmente, a chave primária é chamada id e é uma sequência.
Uma chave estrangeira é usada para se referir a um único registro em outra tabela (usando a chave primária dessa outra tabela).
Em um diagrama ER, a ligação entre as tabelas é normalmente baseada em chaves estrangeiras que se ligam a chaves primárias.
Se olharmos para o nosso exemplo de pessoas, a definição da tabela mostra que a coluna da rua é uma chave externa que faz referência à chave primária na tabela de ruas:
Table "public.people"
Column | Type | Modifiers
-----------+-----------------------+--------------------------------------
id | integer | not null default
| | nextval('people_id_seq'::regclass)
name | character varying(50) |
house_no | integer | not null
street_id | integer | not null
phone_no | character varying |
Indexes:
"people_pkey" PRIMARY KEY, btree (id)
Foreign-key constraints:
"people_street_id_fkey" FOREIGN KEY (street_id) REFERENCES streets(id)
15.1.14. Transações
Ao adicionar, alterar ou excluir dados em um banco de dados, é sempre importante que o banco de dados possa ser deixado em um estado bom se algo der errado. A maioria dos bancos de dados fornecem um recurso chamado suporte a transações. Transações permitem que você crie uma posição de “rollback” podendo voltar a esse ponto caso suas modificações ao banco de dados não ocorram conforme planejado.
Tome um cenário onde você tem um sistema de contabilidade. Você precisa transferir fundos de uma conta e adicioná-los à outro. A sequência de etapas seria assim:
remover R20 do Joe
adicionar R20 para a Anne
Se algo der errado durante o processo (por exemplo, falha de energia), a transação será revertida.
15.1.15. In Conclusion
Bancos de dados permitem que você gerencie os dados de forma estruturada usando estruturas de código simples.
15.1.16. What’s Next?
Agora que já vimos como bancos de dados funcionam na teoria, vamos criar um novo banco de dados para implementar a teoria que nós cobrimos.