18.22. Interpolación¶
Nota
Este capítulo muestra cómo interpolar datos de puntos y le mostrará otro ejemplo real de representación de análisis espacial
En esta lección, vamos a interpolar datos de puntos para obtener una capa ráster. Antes de hacerlo, vamos a tener que hacer un poco de preparación de datos, y después de la interpolación vamos a añadir un poco de procesamiento adicional para modificar la capa resultante, así que vamos a tener una rutina de análisis completo.
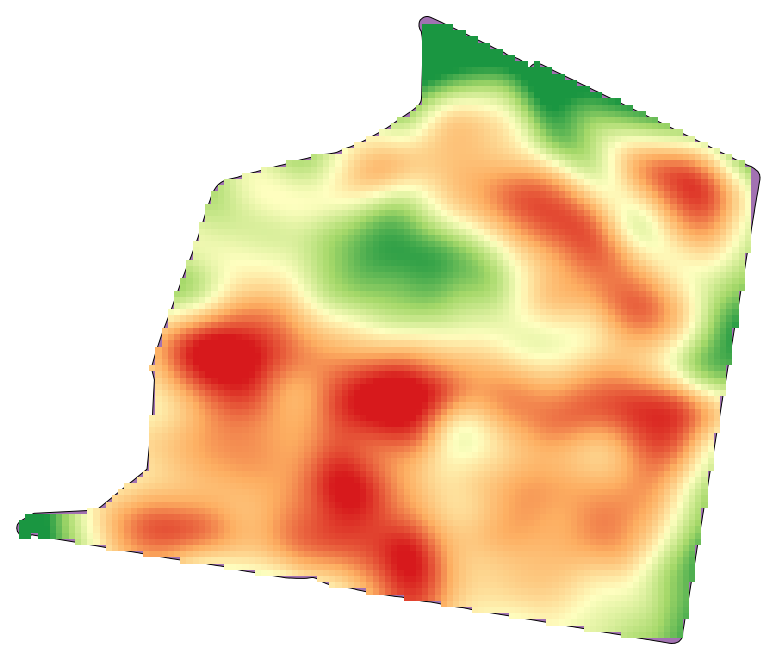
Abra los datos de ejemplo para esta lección, que debería tener este aspecto.

Los datos corresponden a recortar los datos de rendimiento, como lo producido por una cosechadora moderna, y vamos a utilizarlo para conseguir una capa ráster de rendimiento de los cultivos. No tenemos planes de hacer un análisis más lejos con esa capa, pero sólo para utilizarlo como una capa de fondo para identificar fácilmente las áreas más productivas y también aquellos en los que la productividad se puede mejorar.
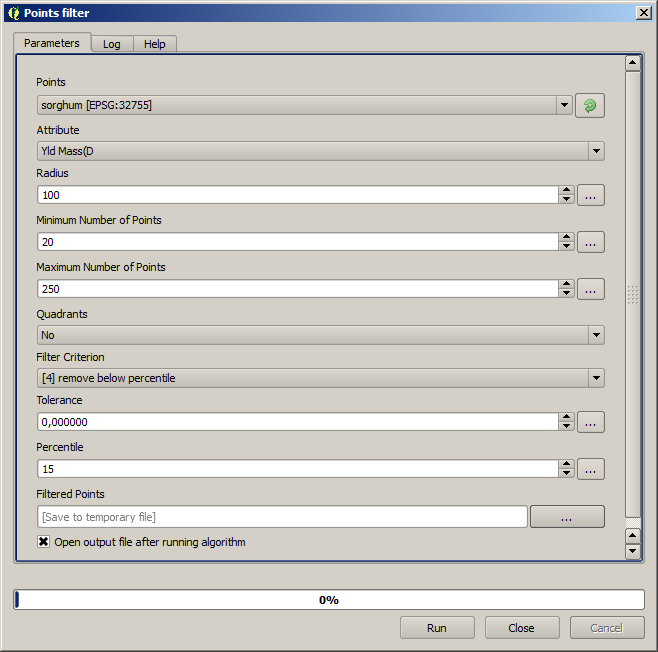
La primera cosa a hacer es limpiar la capa, ya que contiene puntos redundantes. Estas son causadas por el movimiento de la cosechadora, en lugares en los que tiene que hacer un giro o cambiar su velocidad por alguna razón. El algoritmo de Filtro de Puntos será útil para esto. Vamos a utilizarlo dos veces, para eliminar los puntos que se pueden considerar los valores extremos tanto en la parte superior e inferior de la distribución.
Para la primer ejecución, utilice los siguientes valores de parámetros.
Ahora para la siguiente, utilice la configuración que se muestra a continuación.
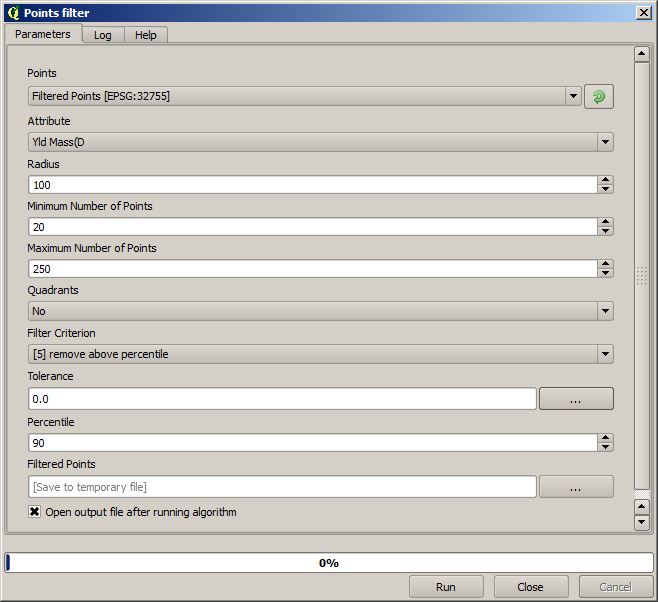
Observe que no estamos utilizando la capa original como entrada, pero la salida de la ejecución anterior en su lugar.
La capa de filtro final, con un conjunto reducido de puntos, debe ser similar a la original, pero contiene un menor número de puntos. Se puede comprobar esto mediante la comparación de sus tablas de atributos.
Ahora vamos a rasterizar la capa utilizando el algoritmo Rasterize
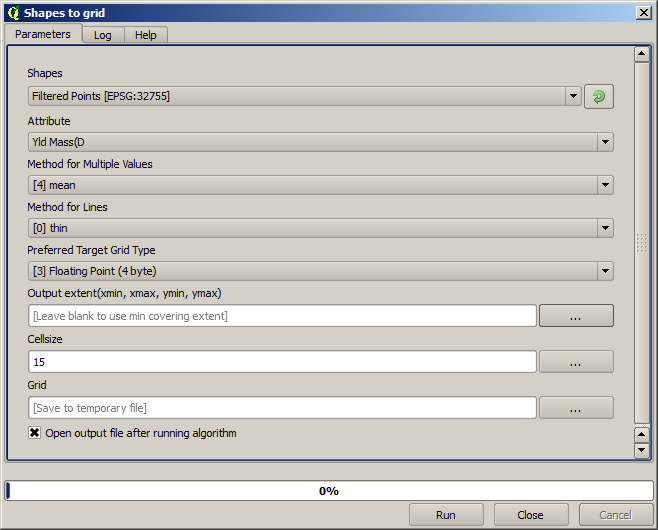
La capa de Puntos filtrados se refiere al resultado de el segundo filtro. Tiene el mismo nombre que el producido por el primer filtro, ya que el nombre es asignado por el algoritmo pero no se debe utilizar la primera. Ya que no vamos a utilizarlo para algo más, puede eliminarlo de forma segura desde su proyecto para evitar confusión y deje sólo la última capa filtrada.
La capa ráster resultante se parece a esto.

Ya es una capa ráster, pero faltan datos en algunas de sus celdas. Sólo contienen valores válidos en aquellas celdas que contienen un punto de la capa vectorial que tenemos rasterizada, y no hay valor de datos en todas las demás. Para llenar los valores faltantes podemos utilizar el algoritmo Cerrar huecos.
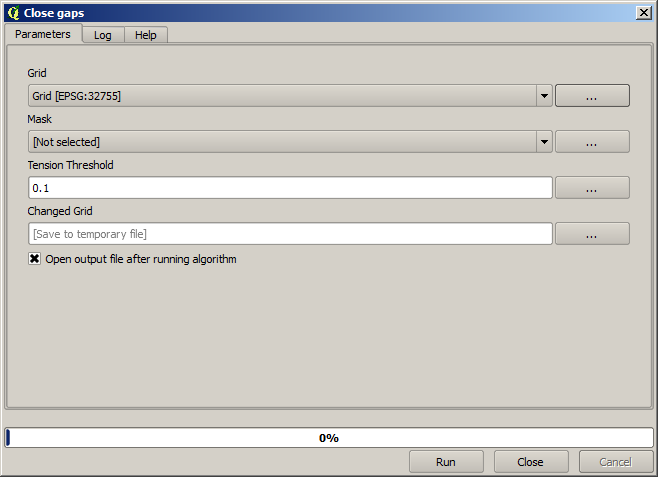
La capa sin ningún - valor de datos se parece a esto.

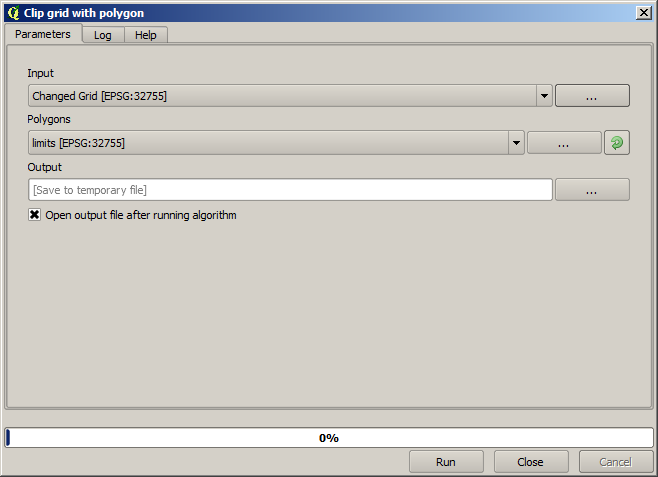
Para restringir el área cubierta por los datos sólo a la región en la que se midió el rendimiento del cultivo, podemos cortar la capa ráster con la capa de límites proporcionado.
Y para un resultado más suave (menos preciso pero mejor para la representación en el fondo como una capa de ayuda), podemos aplicar un Filtro Gaussiano a la capa.
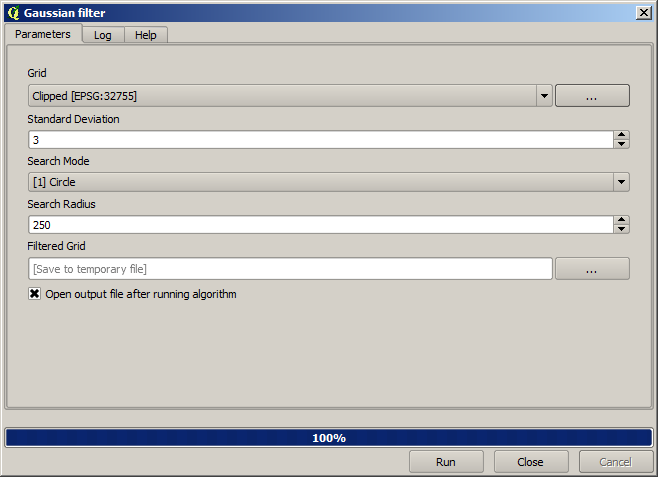
Con los parámetros anteriores obtendrá el siguiente resultado