18.22. Interpolação¶
Nota
Este capítulo mostra como interpolar dados de pontos e mostrará outro exemplo real de análise espacial.
Nesta lição iremos interpolar dados de pontos para obter uma camada raster. Antes disso, iremos realizar a preparação dos dados, e depois de interpolar faremos outros processamentos para modificar a camada resultante, para termos então uma rotina completa de análise.
Abra os dados de exemplo para esta lição, que deve ser semelhante a este.

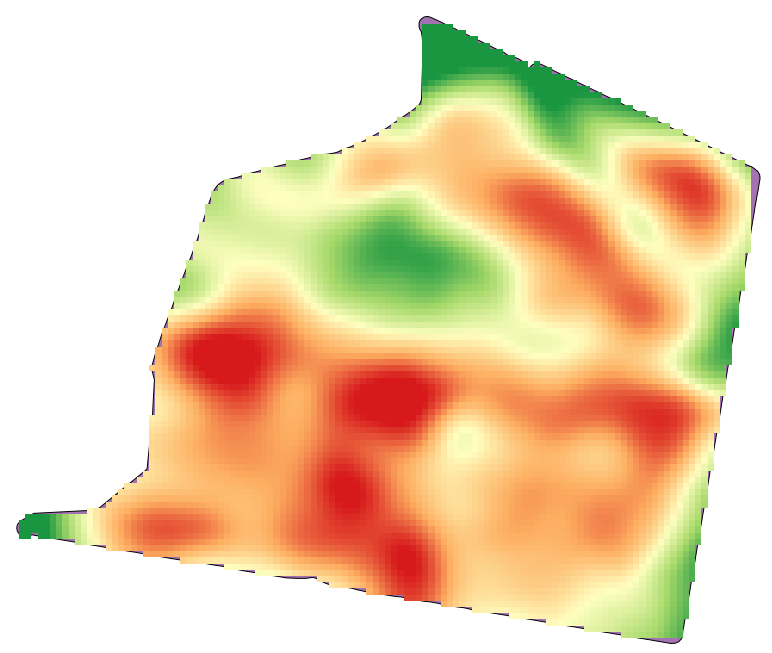
Os dados correspondem aos dados de rendimento de colheita, como produzido por uma colheitadeira moderna, e nós o usaremos para obter uma camada raster de rendimento de colheita. Não planejamos fazer nenhuma análise adicional com essa camada, mas apenas usá-la como uma camada de fundo para identificar facilmente as áreas mais produtivas e também aquelas onde a produtividade pode ser melhorada.
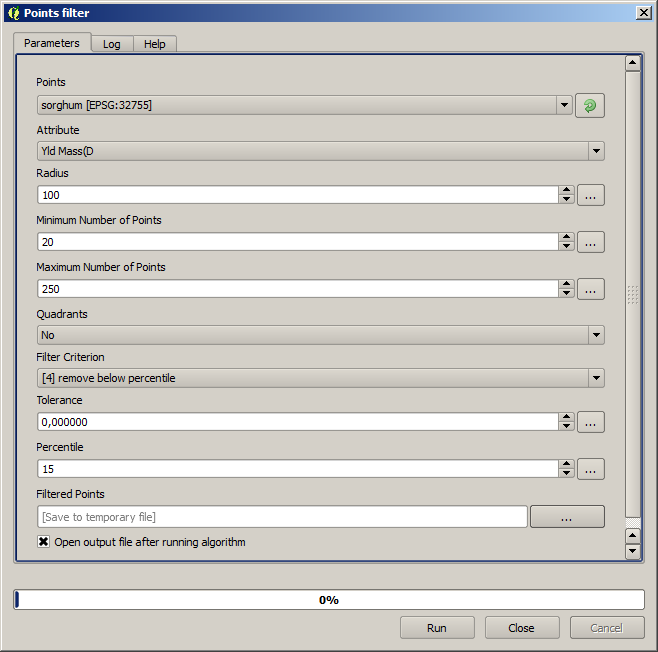
A primeira coisa a fazer é limpar a camada, pois ela contém pontos redundantes. Os pontos redundantes são gerados pelo movimento da colheitadeira, em locais onde a colheitadeira faz uma curva ou quando muda a sua velocidade por algum motivo. O algoritmo Filtrar pontos será útil para isso. Vamos usá-lo duas vezes, para remover pontos que podem ser considerados outliers na parte superior e inferior da distribuição.
Para a primeira execução, usar os seguintes valores de parâmetro.
Agora para o próximo, use a configuração mostrada abaixo.
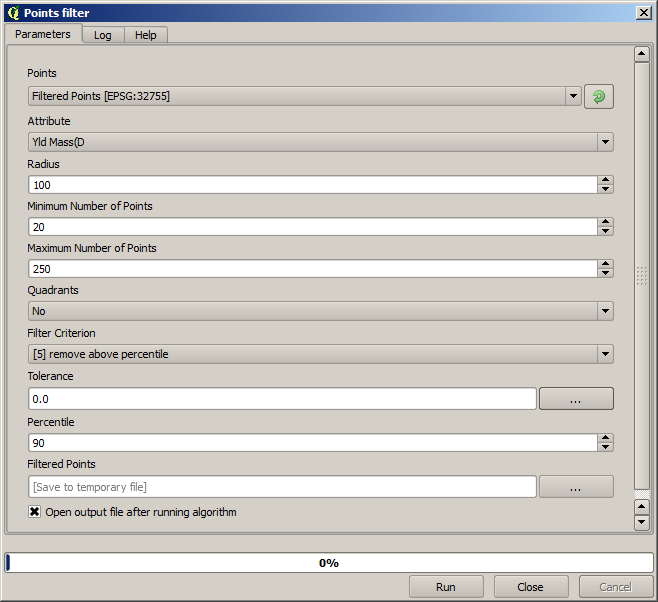
Observe que não estamos usando a camada original como entrada, mas sim a camada de saída da execução anterior.
A camada final filtrada, com um conjunto reduzido de pontos, deve ser semelhante à original, mas irá conter um número menor de pontos. Você pode verificar isso comparando suas tabelas de atributos.
Agora vamos rasterizar a camada usando o algoritmo Rasterizar.
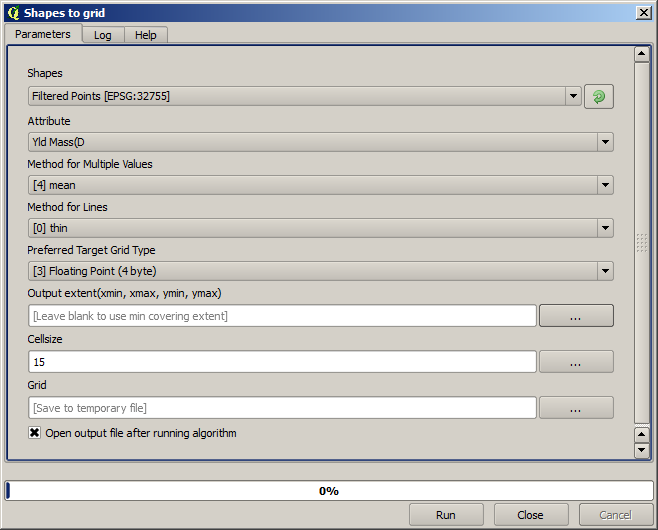
A camada Pontos filtrados refere-se ao resultado do segundo filtro. Tem o mesmo nome que a camada gerada pelo primeiro filtro, já que o nome é atribuído pelo algoritmo, mas você não deve usar a camada do primeiro filtro. Como não iremos usá-la para mais nada, você pode removê-la com segurança do seu projeto para evitar confusão e deixar apenas a última camada filtrada.
A camada raster resultante se parece com isso.

Já é uma camada raster, mas falta dados em algumas de suas células. Ele contém apenas valores válidos nas células que continham um ponto da camada vetorial que acabamos de rasterizar e valor no-data em todos os outros. Para preencher os valores, podemos usar o algoritmo Fechar lacunas.
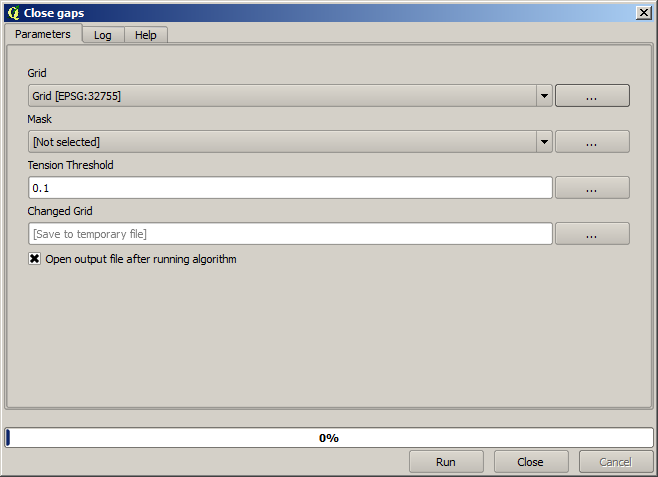
A camada sem valores no-data é assim.

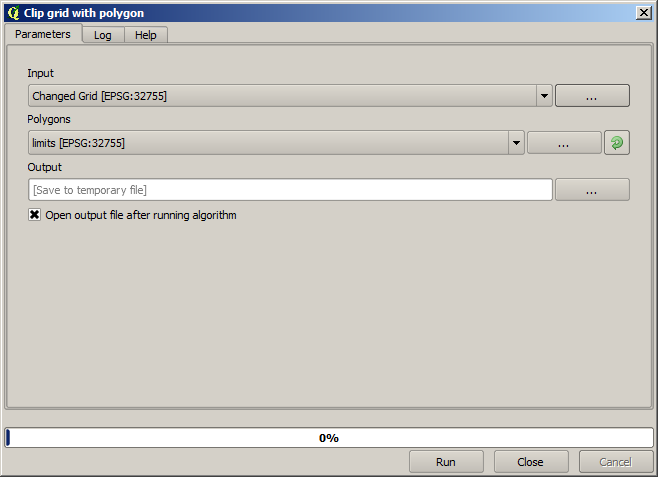
Para restringir a área coberta pelos dados apenas para a região onde o rendimento da safra foi medido, podemos recortar a camada raster com a camada de limites fornecida.
E para um resultado mais suavizado podemos aplicar um filtro Gaussiano à camada.
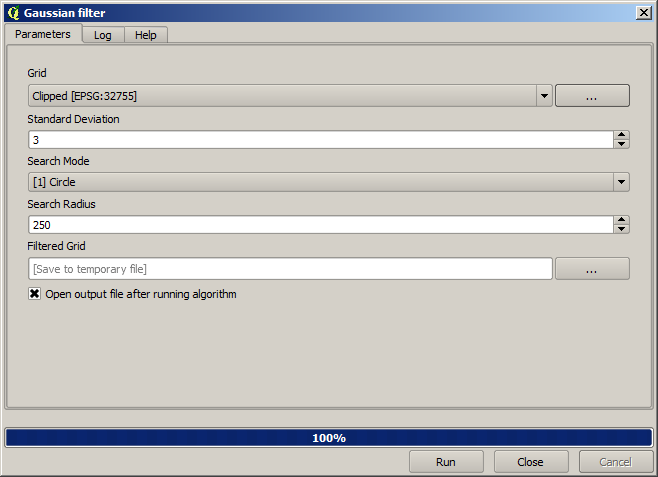
Com os parâmetros acima, você obterá o seguinte resultado